【ESWIN编程大赛】五、2020年11月12日陈工直播笔记

【摘要】
文章目录
一、pint api功能说明1.1、背景1.2、需求1.3、功能模块以及说明1.3.1、组成模块层次1.3.2、Memory Management1.3.3、1D/2D/3D 内存分配与...
一、pint api功能说明
1.1、背景
- 充分展示公司芯片的编程模式的灵活性和高效性。
- 为用户开发人员提供简单高效的编程方式,降低用户编程的入门门槛,提高用户使用粘性。
- 编程模型易维护、易扩展。
1.2、需求
- 编程流程简单高效,API风格与CUDA保持一致,每个API都会返回运行状态值。其功能可以根据使用场景稍作修改。
- 扩展性强,对CUDA的API有针对性的模拟,比如与GPU功能相似的API。
- pint API包含通用的basic API(memory malloc、copy和memset,program launch, stream operation, event等)。
- 提供支持C/C++、python 语言的api功能
1.3、功能模块以及说明
| Module Name | Description |
|---|---|
| Memory Management (Single device) | Memory malloc, copy, memset in 1D,2D,3D |
| Memory Management (Multi devices) | Memory copy peer (1 device to other device) |
| Execution Control | Create and launch program with source type is code file, binary, code string. |
| Device Management | Init device running mode, get device count and detail info, set and change computing device. |
| Stream Management | A task queue to control device tasks and realize asynchronous operation |
| Error handling | Show the error return as string type or string description. |
| Version management | Show the pint api and other dependency libraries version. |
| other new function | deep learnning etc… |
1.3.1、组成模块层次
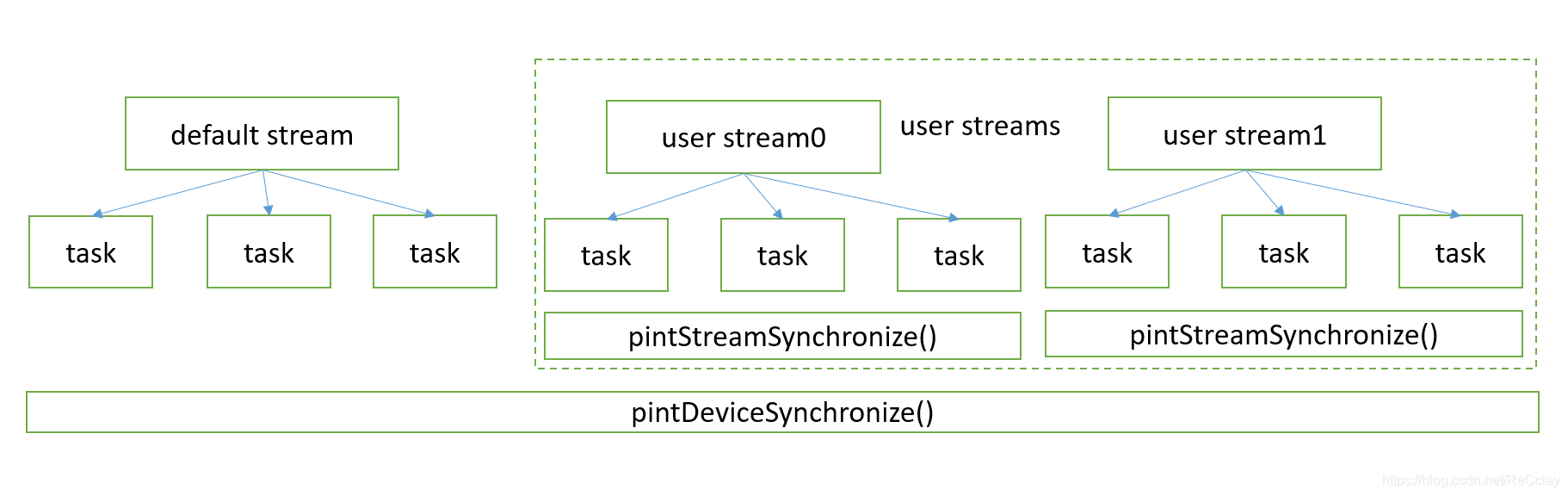
默认使用的是default stream
1.3.2、Memory Management
- 1、支持1D,2D,3D的memory 分配,多维的memory malloc会产生pitch。
- 2、pitch是设备cache line的整数倍,pitch的存在有利于memory的对齐操作,比如跨行访问、对齐拷贝,提高效率。
- 3、pintMemcpy, pintMemcpy2D, pintMemcpy3D,pintMemset, pintMemsetPatern都是设备全局同步函数。
- 4、Memory copy支持同步异步模式,共5种类型:
- a、Host to Host (H2H, 多一种host端的异步的选择,如果不想用这个功能,可用系统函数memcpy替代)
- b、Host to Device(H2D)
- c、Device to Host (D2H)
- d、Device to Device (D2D)
- e、Default (通过判断输入参数的类型(Host ptr or Device ptr),自动去选择拷贝类型。
1.3.3、1D/2D/3D 内存分配与拷贝
内存分配
1D/2D内存分配
1D pintMalloc(void **devPtr, size_t size)
2D pintMallocPitch(void **devPtr, size_t *pitch, size_width, size_t height)
- 1
- 2
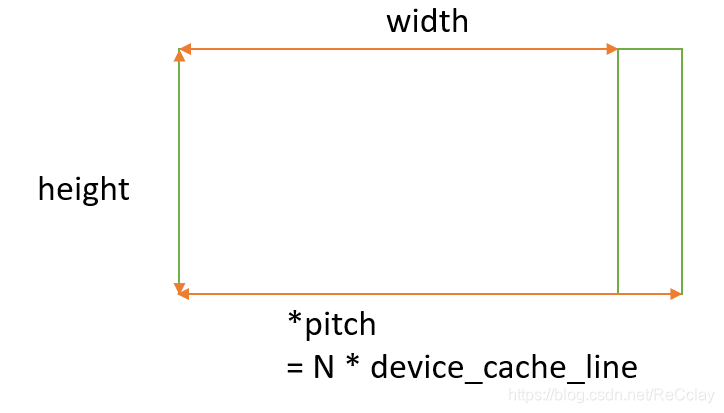
3D内存分配
3D pintMalloc3D(void **devPtr, struct pintPitch *pitch, const struct pintRegion region)
- 1
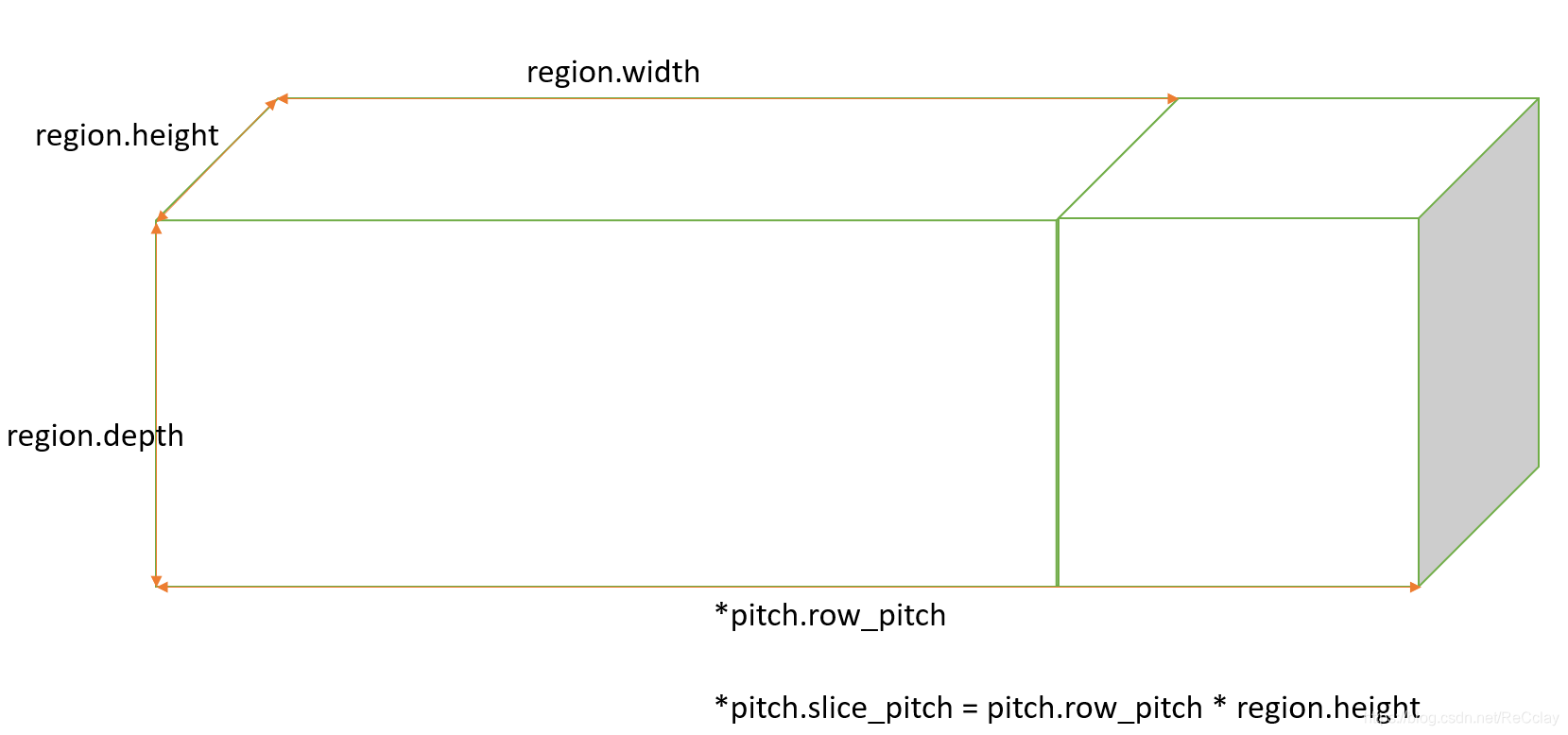
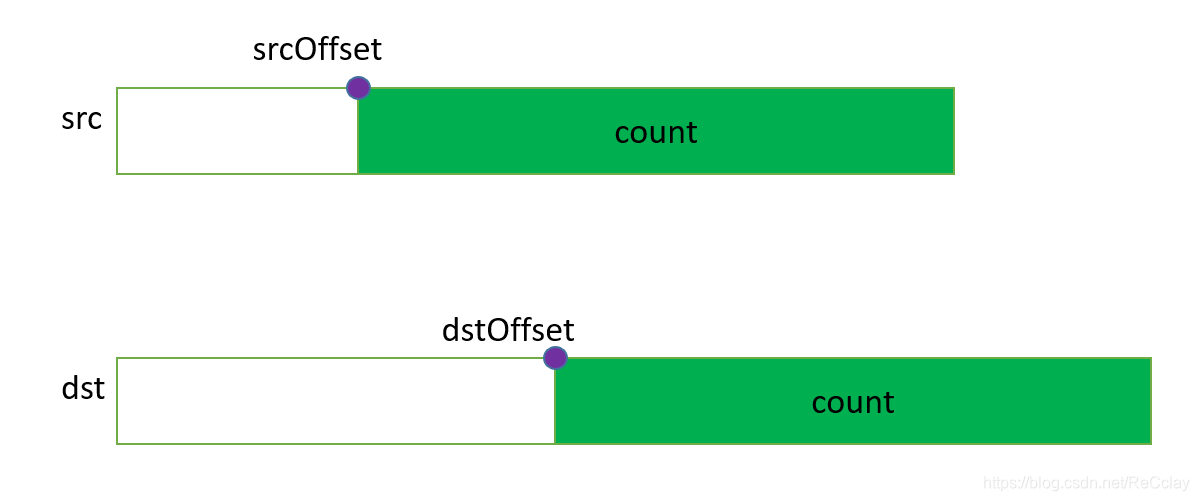
内存拷贝
1D内存拷贝
1D copy pintMemcpy(void *dst, const size_t dstOffset, const void *src,
const size_t srcOffset, size_t count,
enum pintMemcpyKind kind);
- 1
- 2
- 3
- 4
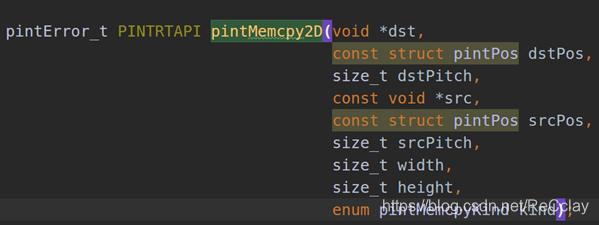
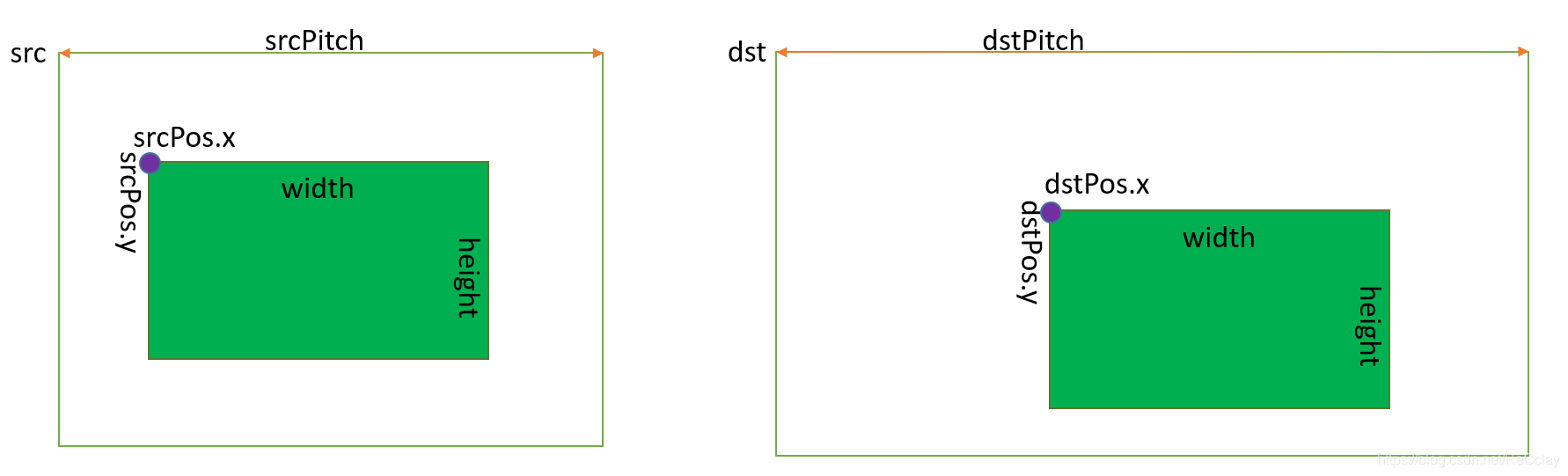
2D内存拷贝
3D内存拷贝

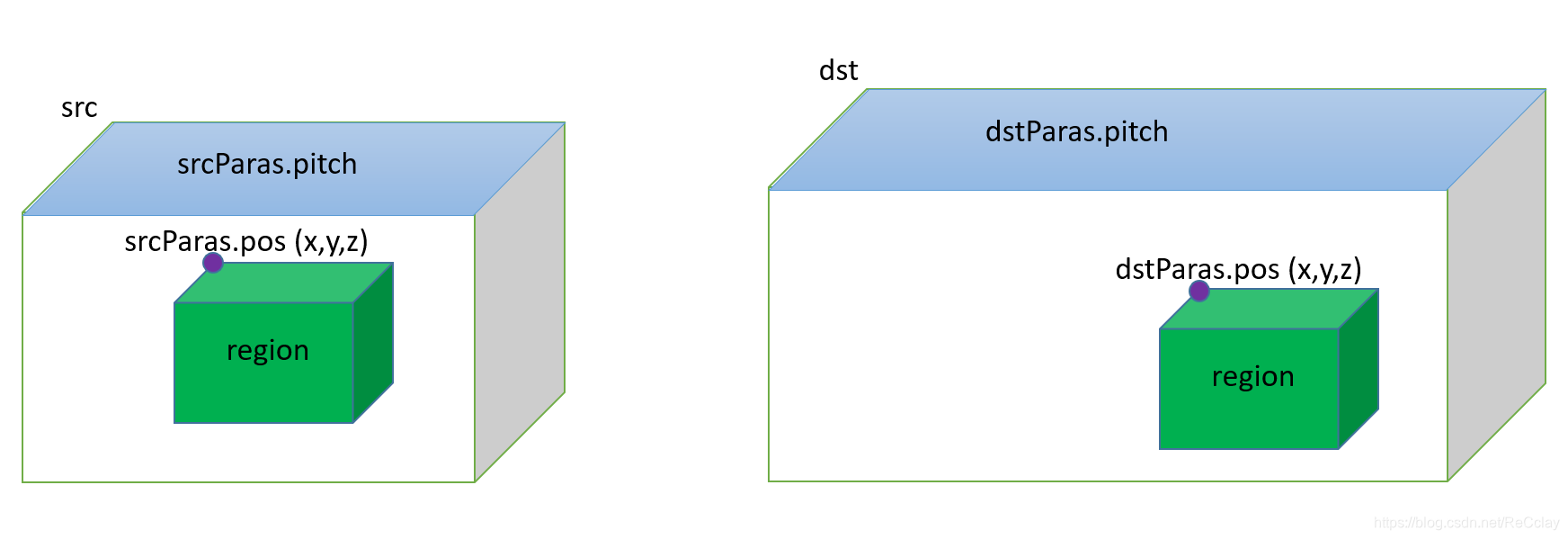
1.3.4、Pattern

支持 pattern_size 1,2,4,8,16,32,64,128.

按1Byte做memory set.
1.3.5、Execution Control
- 编译源码、源码文件或者解析可执行文件,并生成一个携带可在设备上运行的信息的program结构体。
- 由于设备代码中需要传参,参数是global变量,且编译后的参数在设备上的地址顺序不确定,所以传参的方式需要指定global变量,以与字符串映射的方式传入,比如 {“iA”, d_iA}。
1.3.6、Program

- src: 源代码文件、源代码字符串、编译的可执行二进制.pin文件。
- options:额外的编译选项。
- kind: 指定src的类型。

- 该函数主要功能是更新参数并将该kernel的可执行信息提交给设备。该函数为异步函数,如果想要获取准确的结果,需要加上同步函数。
- pint_args:类似于字典的结构体,存入kernel 代码中的global变量和host端初始化的指针,比如{“iA”, d_iA} 。如果不想传参或者更新参数,该参数可设置为NULL。
- info:program 运行时候的一些信息,比如设备上的耗时 cycle数。该结构体也可以作为今后的一个扩展用。如果不想获取这些信息,该参数可设置为NULL。
1.3.7、Device Management
- 初始化设备。如果没有显示初始化,pint api会在设备运行时初始化设备。
- 获取设备的基本信息,包括数量、id等其它基本信息。
- 切换设备。可以快速切换设备id的方式,让对应的设备能里面运行。
- 设备id从0开始,止于设备数量 - 1。
- 如果未指定设备,默认使用设备id 0。【现在比赛用的就是默认设备0】
pintError_t pintSetDevice(int device)
- 1
- 通过设置设备id来快速切换到对应的设备。
- 如果不调用该函数,则使用default device 0.
Code example:
for(int i = 0; i < device_count; ++i){
pintSetDevice(i);
pintMalloc();
pintMemcpy();
pintLaunch();
pintDeviceSynchronize();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
pintError_t pintDeviceSynchronize()同步设备上的所有操作,直到当前时刻设备上所有的操作执行完。pintError_t pintDeviceRest(void)销毁当前进程的所有分配的资源并对其重置。
1.3.8、Stream Management
- 一个host上运行的异步的任务队列,用于管理在设备上运行的任务集。
- 一个设备上可拥有多个stream。
- Streams之间的任务集相互独立。设备上支持多种类型的操作同时运行,通过多个stream协作,可以overlap掉部分操作,提高效率。
- 如果没有创建stream,每个设备都会有一个对应的default stream,来管理任务集。
- 所有支持stream的api尾部都带有Async(除了pintLaunchProgram),并在参数列表中需要指定stream。
- 所有支持stream api都是异步函数,想要保证结果的正确性,最好加上同步函数。
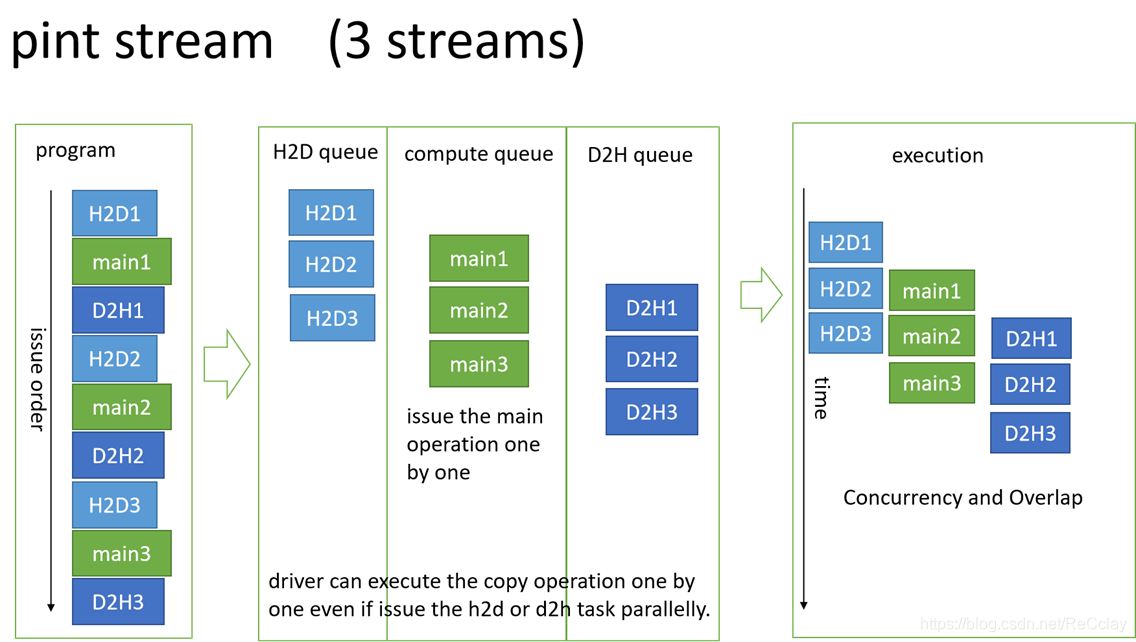
常见的3种stream的写法


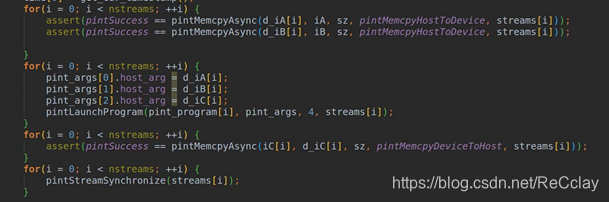
1.3.9、Error handling
返回错误码对应的字符串或者错误信息,方便调试。
const char* pintGetErrorName(pintError_t error)const char* pintGetErrorString(pintError_t error)
二、pint kernel优化讲解
2.1、pintMemset 和pintMemsetPattern 用于初始化memory
int *d_buffer = pintMalloc((void**)&d_buffer, size_inbytes);
pintMemset(d_buffer, 0, 0, size_inbytes);
d_buffer[i] = 0; //on device
- 1
- 2
- 3
int pattern = 1234;
pintMemsetpattern(d_buffer, &pattern, sizeof(int), 0, size_inbytes);
d_buffer[i] = 1234; //on device
- 1
- 2
- 3
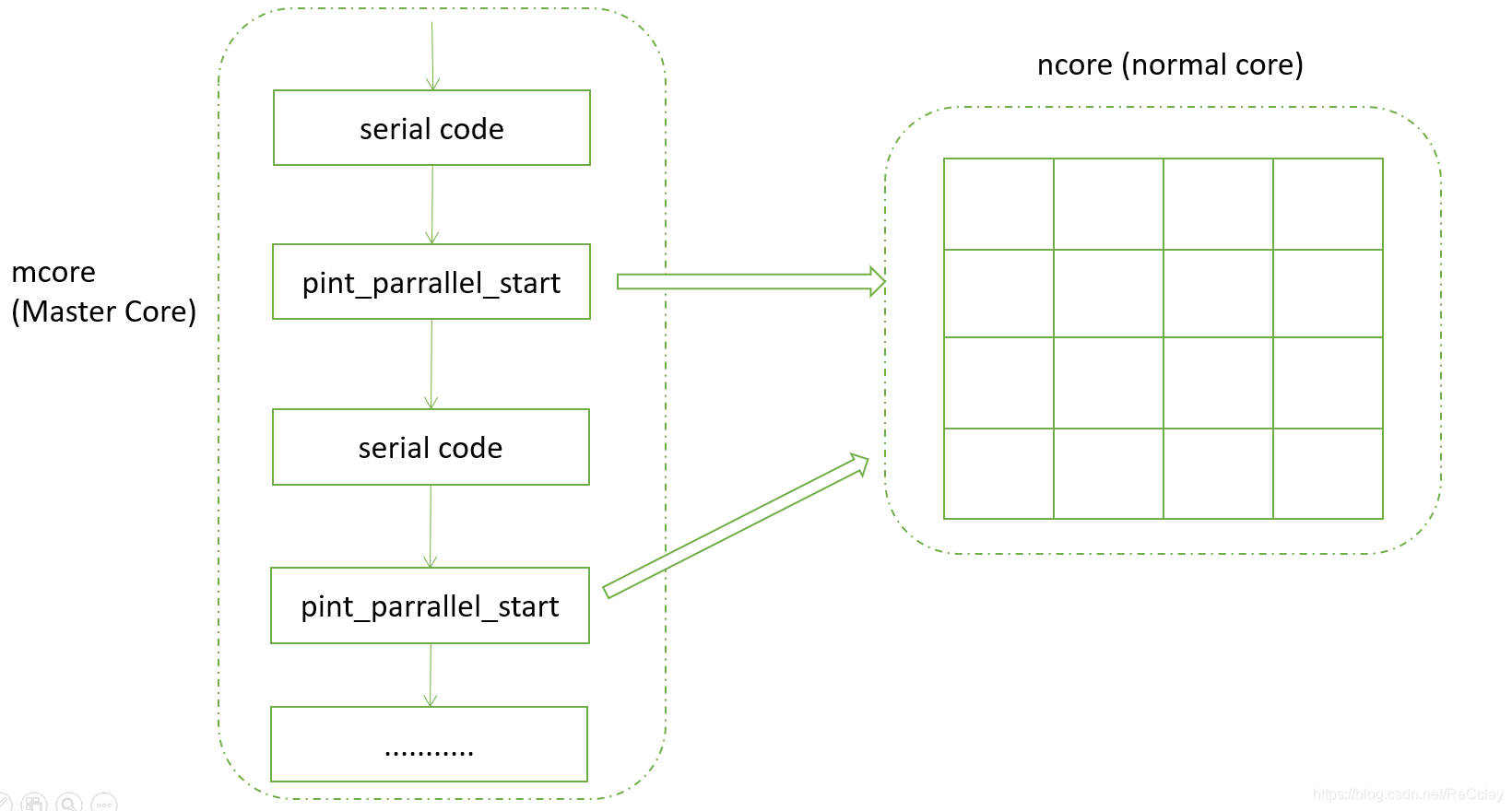
2.2、pint kernel运行模式(支持串行并行)
2.3、read only + cache line

- 1、without read only
- 每次数据从Share Cache读取到D cache只有一个Word(4Bytes)。
- 2、with read only
- 每次数据从Share Cache读取到D cache有一个cache line(64Bytes)。
有效利用硬件的read only,可以大大提高UAP的带宽。
①、函数调用
/**
* \brief set dcache read-only range
*
* \param begin - read-only start addr
* \param end - read-only end addr
*
* \return
* void
*
*/
inline void pint_ro_seg_set(const void* begin, const void* end){
uap_ro_seg_set(
(addr_t)(begin) ,
(addr_t)(end) );
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
②、结束
pint_dcache_discard();
- 1
2.4、write only
- 数据写入share cache并不会马上写入DDR,而是会保留在share cache上。等cache line被踢后,被踢的cache line会写到DDR上。减少数据与DDR的通信次数。
- 目前write only功能支持的数据量较小,大约8MB左右。
①、设置只写区域函数:
/**
* \brief initialize write only region with begin address and length
*
* \param begin_addr - write only region begin address
* \param length - write only region length in byte
*
* \return
* void
*/
inline void pint_mcore_wo_region_init(const void* begin_addr, uint32_t length)
{
cache_line_t start_cache = (addr_t)begin_addr >> 6;
cache_line_t end_cache = ((addr_t)begin_addr + length + 63) >> 6;
uap_mcore_wo_enable(start_cache, end_cache);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
需要注意的是,length为只写区域的字节数!
②、只写区域结束调用:
pint_mcore_wo_region_release();
- 1
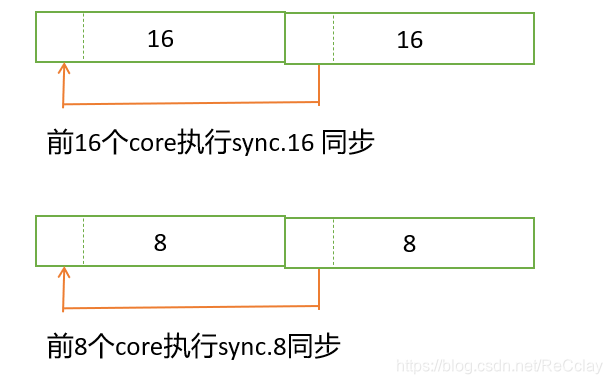
2.5、ncore 同步sync功能(全局,部分同步)
- 全局同步 sync (所有core)
- 32 core同步 (
0~31,32~63,..为一组) - 16 core同步 (
0~15,16~31,..为一组) - 8 core同步 (
0~7,8~15,..为一组) - sync.retire 不同步 (调用该函数的core都可以不强制被同步
这里以累加操作做说明。UAP目前由256个core,512个int数据:

第一次累加,将后半段的数据累加到前半段,同时增加一个全局同步。

第一次累加,将后半段的数据累加到前半段,考虑到后128个core不需要保存数据,不参与下一次累加计算,所以不用做同步,调用sync.retire后不会被强制同步。

①、汇编写法:
asm volatile("uap.sync");
- 1
②、C语言写法:
pint_sync_all_cores();
- 1
2.6、原子操作
①、 汇编写法:
asm volatile("uap.faa\t%1, %0":"+m" (x), "+r" (b));
- 1
执行:
tmp = x;
x = x + b;
b = tmp;
- 1
- 2
- 3
②、C语言写法
b = pint_atomic_add(&x, 1);
- 1
执行:
b = x;
x = x + 1;
- 1
- 2
2.7、Dcache discard 和 Dcache flush
Dcache discard
/**
* \brief discard data of dcache
*
* \return
* void
*
*/
inline void pint_dcache_discard(){
uap_dcac_discard();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Dcache flush
/**
* \brief flush dcache dirty data to shared-cache excluding stack data.
* 将dcache脏数据清除到shared-cache中,不清除栈数据。
* \return
* void
*/
inline void pint_dcache_flush_excluding_stack(){
uap_dcac_flush_excluding_stack();
}
/**
* \brief flush all dcache dirty data to shared-cache.
* 将所有dcache脏数据刷新到shared-cache中。
* \return
* void
*/
inline void pint_dcache_flush(){
uap_dcac_flush();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2.8、nonblocking
文章来源: recclay.blog.csdn.net,作者:ReCclay,版权归原作者所有,如需转载,请联系作者。
原文链接:recclay.blog.csdn.net/article/details/109692272

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)