Spark基础学习笔记01:初步了解Spark

零、本讲学习目标
- 了解Spark的发展历史及特点
- 学会搭建Spark环境
- 了解Spark的运行架构与原理
一、认识Spark
(一)Spark简介
- 快速、分布式、可扩展、容错的集群计算框架;
- Spark是基于内存计算的大数据分布式计算框架;
- Spark提供低延迟的复杂分析;
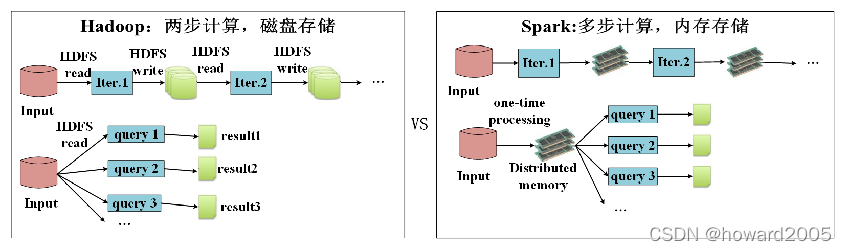
- Spark是Hadoop MapReduce的替代方案。MapReudce不适合迭代和交互式任务,Spark主要为交互式查询和迭代算法设计,支持内存存储和高效的容错恢复。Spark拥有MapReduce具有的优点,但不同于MapReduce,Spark中间输出结果可以保存在内存中,减少读写HDFS的次数。
(二)Spark官网
(三)Spark发展历史
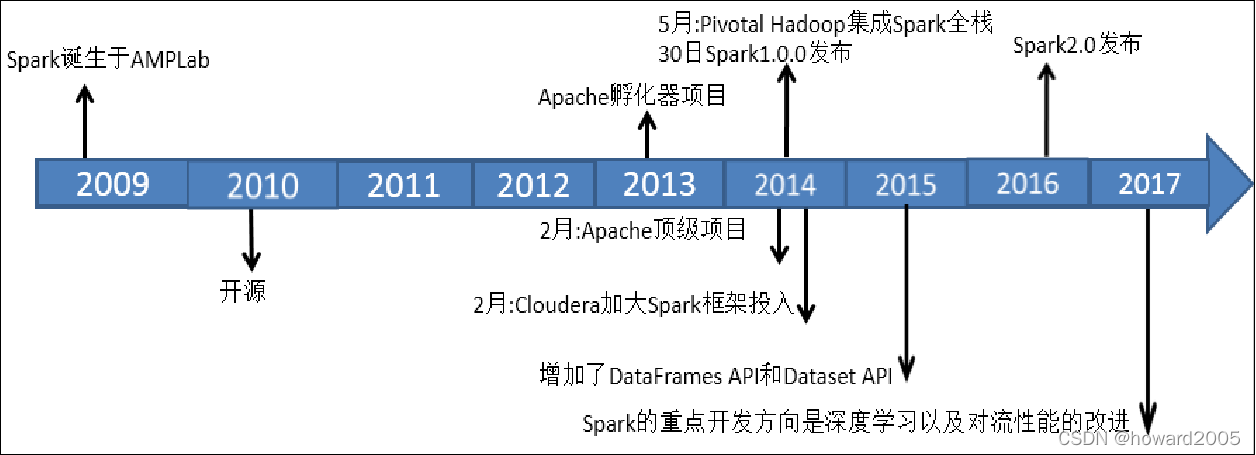
- Spark目前最新版本是2022年1月26日发布的Spark3.2.1
(四)Spark的特点
1、快速
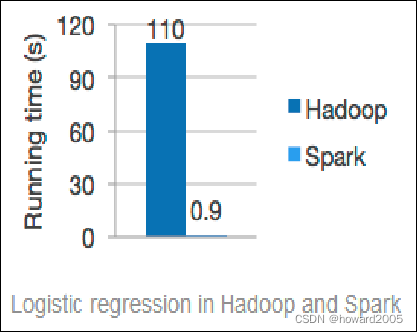
- 一般情况下,对于迭代次数较多的应用程序,Spark程序在内存中的运行速度是Hadoop MapReduce运行速度的100多倍,在磁盘上的运行速度是Hadoop MapReduce运行速度的10多倍。

2、易用性
- Spark支持使用Scala、Python、Java及R语言快速编写应用。同时Spark提供超过80个高级运算符,使得编写并行应用程序变得容易并且可以在Scala、Python或R的交互模式下使用Spark。

3、通用性
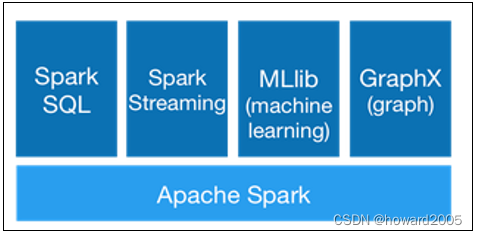
- Spark可以与SQL、Streaming及复杂的分析良好结合。Spark还有一系列的高级工具,包括Spark SQL、MLlib(机器学习库)、GraphX(图计算)和Spark Streaming,并且支持在一个应用中同时使用这些组件。
4、随处运行
- 用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据。

5、代码简洁
- 参看【采用多种方式实现词频统计】
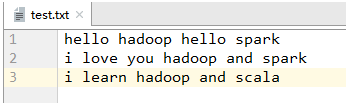
(1)采用MapReduce实现词频统计
- 编写WordCountMapper
package net.hw.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Created by howard on 2018/2/6.
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] data = line.split(" ");
for (int i = 0; i < data.length; i++) {
context.write(new Text(data[i]), new IntWritable(1));
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 编写WordCountReducer
package net.hw.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Created by howard on 2018/2/6.
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count = count + value.get();
}
context.write(key, new IntWritable(count));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 编写WordCountDriver
package net.hw.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
/**
* Created by howard on 2018/2/6.
*/
public class WordCountDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
String uri = "hdfs://hadoop:9000";
Path inputPath = new Path(uri + "/word");
Path outputPath = new Path(uri + "/word/result");
FileSystem fs = FileSystem.get(new URI(uri), conf);
fs.delete(outputPath, true);
FileInputFormat.addInputPath(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
job.waitForCompletion(true);
System.out.println("统计结果:");
FileStatus[] fileStatuses = fs.listStatus(outputPath);
for (int i = 1; i < fileStatuses.length; i++) {
System.out.println(fileStatuses[i].getPath());
FSDataInputStream in = fs.open(fileStatuses[i].getPath());
IOUtils.copyBytes(in, System.out, 4096, false);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 运行程序WordCountDriver,查看结果
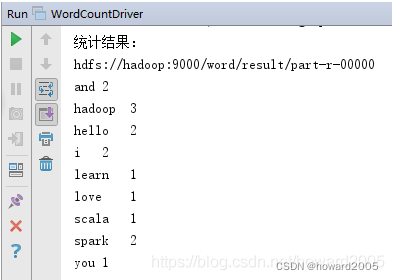
(2)采用Spark实现词频统计
- 编写WordCount
package net.hw.spark.wc
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by howard on 2018/2/6.
*/
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("wordcount")
val sc = new SparkContext(conf)
val rdd = sc.textFile("test.txt")
.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
rdd.foreach(println)
rdd.saveAsTextFile("result")
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 启动WordCount,查看结果
- 大家可以看出,完成同样的词频统计任务,Spark代码比MapReduce代码简洁很多。
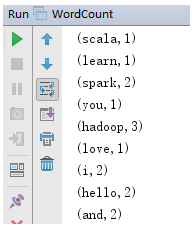
(五)Spark存储层次
- Spark 不仅可以将任何Hadoop 分布式文件系统(HDFS)上的文件读取为分布式数据集,也可以支持其他支持Hadoop 接口的系统,比如本地文件、亚马逊S3、Cassandra、Hive、HBase 等。我们需要弄清楚的是,Hadoop 并非Spark 的必要条件,Spark 支持任何实现了Hadoop 接口的存储系统。Spark 支持的Hadoop 输入格式包括文本文件、SequenceFile、Avro、Parquet 等。
(六)Spark生态圈
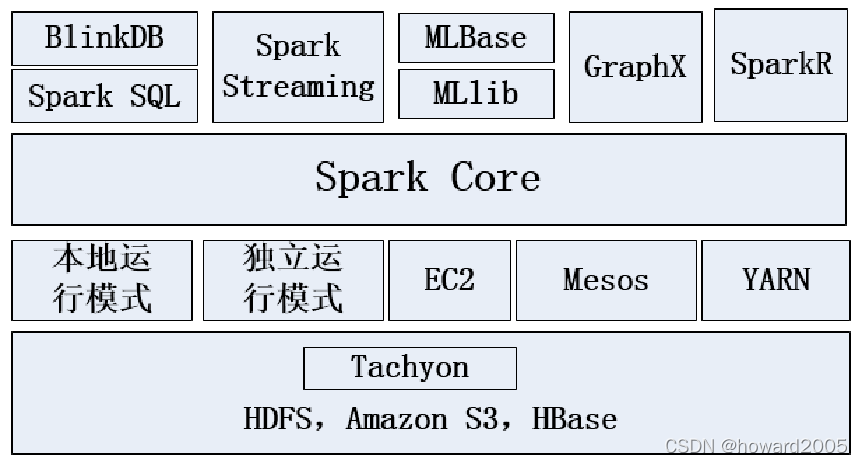
1、Spark SQL
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val prop = new java.util.Properties
prop.put("user","root")
prop.put("password","root")
val df = sqlContext.read.jdbc("jdbc:mysql://hadoop:3306/studb", "student", prop)
df.show()
- 1
- 2
- 3
- 4
- 5
- 6
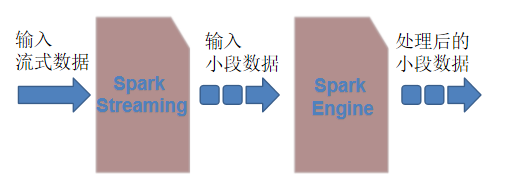
2、Spark Streaming
3、MLlib
4、GraphX
(七)Spark应用场景
1、腾讯
- 广点通是最早使用Spark的应用之一。腾讯大数据精准推荐借助Spark快速迭代的优势,围绕“
数据+算法+系统”这套技术方案,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR (Predict Click-Through Rate) 投放系统上,支持每天上百亿的请求量。
2、Yahoo
- Yahoo将Spark用在Audience Expansion中。Audience Expansion是广告中寻找目标用户的一种方法,首先广告者提供一些观看了广告并且购买产品的样本客户,据此进行学习,寻找更多可能转化的用户,对他们定向广告。Yahoo采用的算法是
Logistic Regression。同时由于某些SQL负载需要更高的服务质量,又加入了专门跑Shark的大内存集群,用于取代商业BI/OLAP工具,承担报表/仪表盘和交互式/即席查询,同时与桌面BI工具对接。
3、淘宝
- 淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等,将Spark运用于淘宝的推荐相关算法上,同时还利用GraphX解决了许多生产问题,包括以下计算场景:基于度分布的中枢节点发现、基于最大连通图的社区发现、基于三角形计数的关系衡量、基于随机游走的用户属性传播等。
4、优酷土豆
- 目前Spark已经广泛使用在优酷土豆的视频推荐,广告业务等方面,相比Hadoop,Spark交互查询响应快,性能比Hadoop提高若干倍。一方面,使用Spark模拟广告投放的计算效率高、延迟小(同Hadoop比延迟至少降低一个数量级)。另一方面,优酷土豆的视频推荐往往涉及机器学习及图计算,而使用Spark解决机器学习、图计算等迭代计算能够大大减少网络传输、数据落地等的次数,极大地提高了计算性能。
二、搭建Spark环境
(一)搭建单机版环境
- 参看学习笔记《大数据学习笔记03:安装配置CentOS7虚拟机》下载链接:https://pan.baidu.com/s/1wxRh3ggzxZtzQshqMy_A8g 提取码:71yw
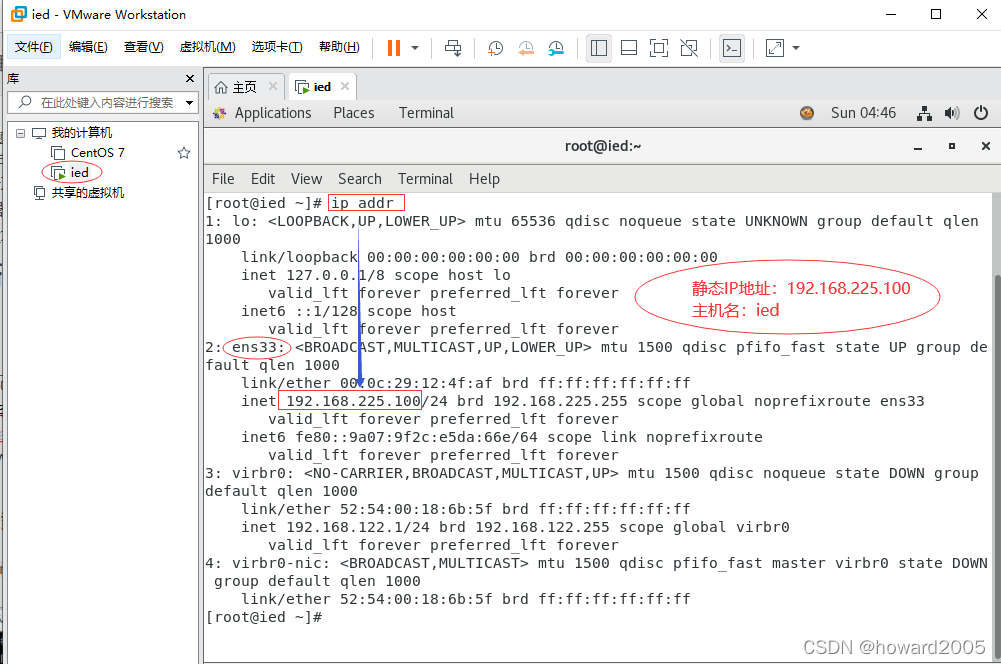
- 在VMware Workstation上创建了虚拟机 - ied
1、卸载CentOS7自带的OpenJDK
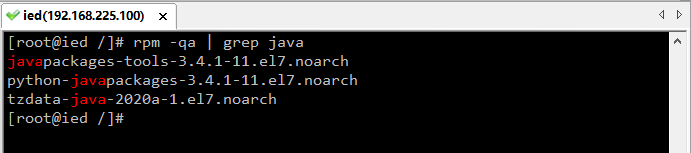
- 通过命令
rpm -qa | grep java查询已经安装的java包
- 通过命令
rpm -e --nodeps xxxxxx卸载已经安装的OpenJDK包

rpm -e --nodeps java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.262.b10-1.el7.x86_64
rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.261-2.6.22.2.el7_8.x86_64
- 1
- 2
- 3
- 4

- 确认是否已经删除成功
2、下载和安装JDK
-
下载链接:https://pan.baidu.com/s/1RcqHInNZjcV-TnxAMEtjzA 提取码:jivr
-
上传到虚拟机/opt目录
-
将Java安装包解压到/usr/local
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local

- 配置环境变量

JAVA_HOME=/usr/local/jdk1.8.0_231
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH CLASSPATH
- 1
- 2
- 3
- 4
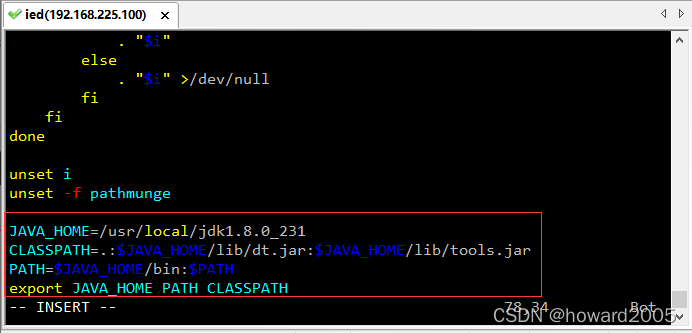
- 存盘退出,让环境配置生效
- 在任意目录下都可以查看JDK版本(不是CentOS自带的OpenJDK)

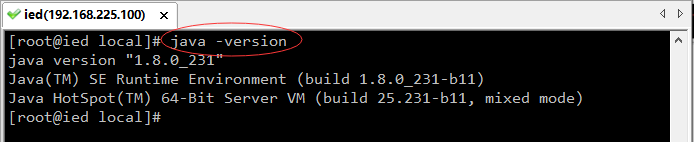
3、下载Spark安装包到Windows本地
- 下载链接:https://pan.baidu.com/s/1dLKt5UJgpqehRNNDcoY2DQ 提取码:zh0x
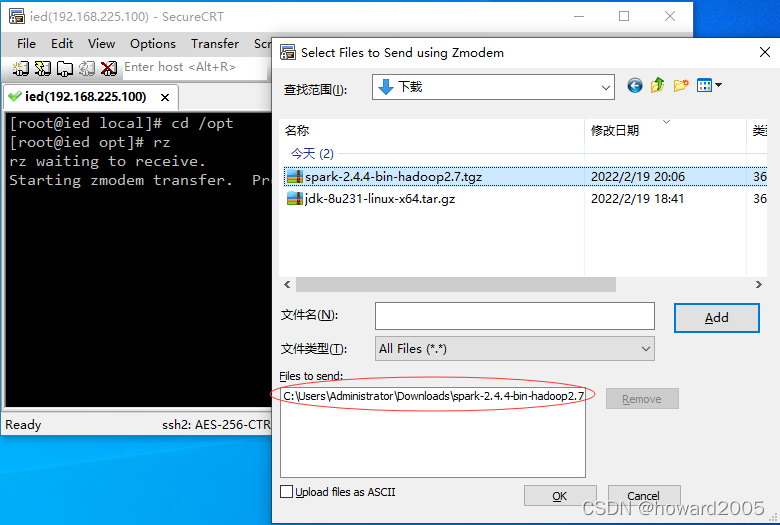
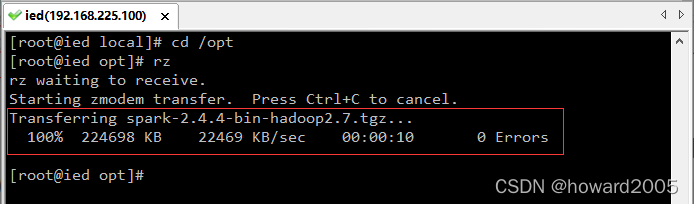
4、将Spark安装包上传到Linux的/opt目录下
-
进入/opt目录
-
利用rz命令上传Spark安装包

5、将Spark安装包解压到/usr/local目录下
tar -zxvf spark-2.4.4-bin-hadoop2.7.tgz -C /usr/local

6、配置Spark环境变量
- 执行 vim /etc/profile

JAVA_HOME=/usr/local/jdk1.8.0_231
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
SPARK_HOME=/usr/local/spark-2.4.4-bin-hadoop2.7
PATH=$JAVA_HOME/bin:$SPARK_HOME/bin:$PATH
export JAVA_HOME SPARK_HOME PATH CLASSPATH
- 1
- 2
- 3
- 4
- 5
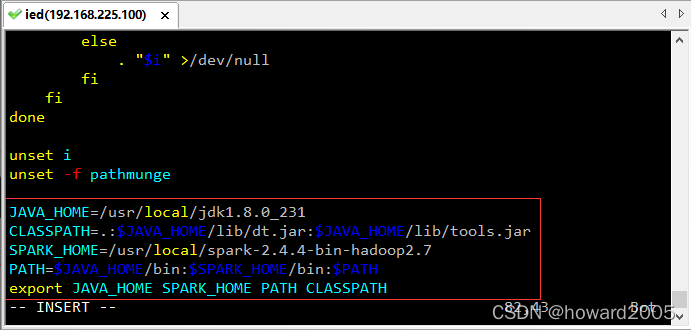
- 存盘退出,让环境配置生效

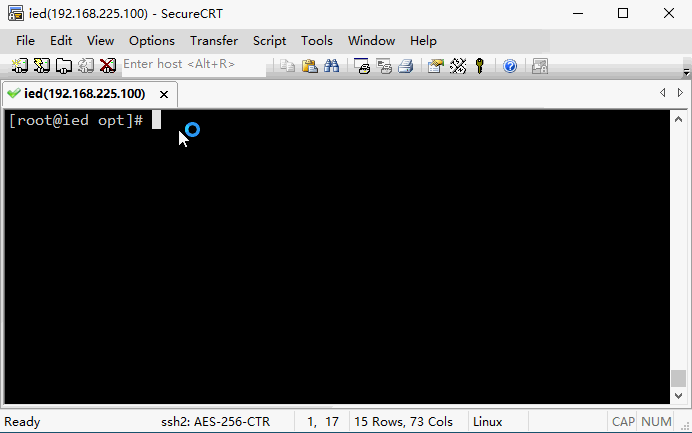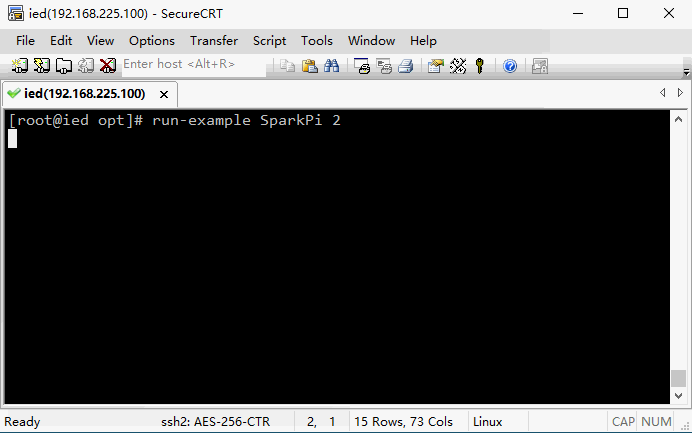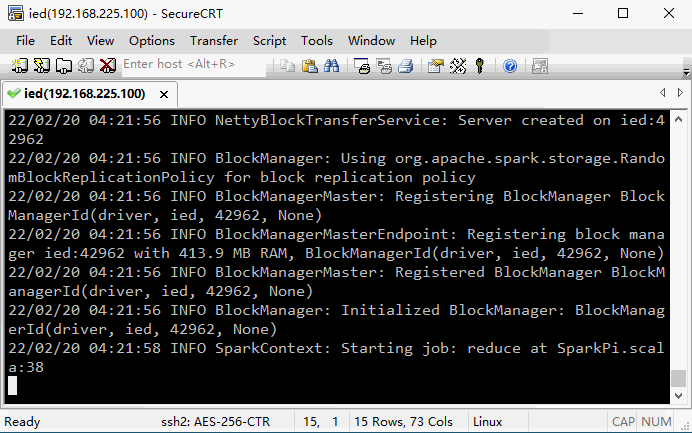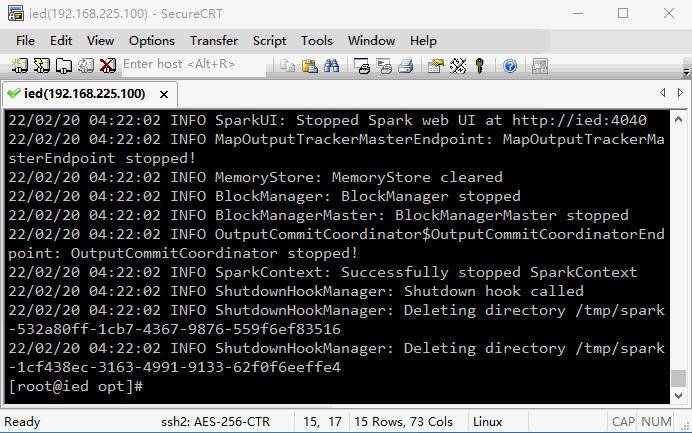
7、使用SparkPi来计算Pi的值
run-example SparkPi 2 # 其中参数2是指两个并行度
[root@ied opt]# run-example SparkPi 2
22/02/20 04:24:32 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
22/02/20 04:24:34 INFO SparkContext: Running Spark version 2.4.4
22/02/20 04:24:34 INFO SparkContext: Submitted application: Spark Pi
22/02/20 04:24:34 INFO SecurityManager: Changing view acls to: root
22/02/20 04:24:34 INFO SecurityManager: Changing modify acls to: root
22/02/20 04:24:34 INFO SecurityManager: Changing view acls groups to:
22/02/20 04:24:34 INFO SecurityManager: Changing modify acls groups to:
22/02/20 04:24:34 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
22/02/20 04:24:35 INFO Utils: Successfully started service 'sparkDriver' on port 41942.
22/02/20 04:24:35 INFO SparkEnv: Registering MapOutputTracker
22/02/20 04:24:36 INFO SparkEnv: Registering BlockManagerMaster
22/02/20 04:24:36 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
22/02/20 04:24:36 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
22/02/20 04:24:36 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-8de32b0e-530a-47ba-ad2d-efcfaa2af498
22/02/20 04:24:36 INFO MemoryStore: MemoryStore started with capacity 413.9 MB
22/02/20 04:24:36 INFO SparkEnv: Registering OutputCommitCoordinator
22/02/20 04:24:36 INFO Utils: Successfully started service 'SparkUI' on port 4040.
22/02/20 04:24:36 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://ied:4040
22/02/20 04:24:36 INFO SparkContext: Added JAR file:///usr/local/spark-2.4.4-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.4.4.jar at spark://ied:41942/jars/spark-examples_2.11-2.4.4.jar with timestamp 1645302276946
22/02/20 04:24:36 INFO SparkContext: Added JAR file:///usr/local/spark-2.4.4-bin-hadoop2.7/examples/jars/scopt_2.11-3.7.0.jar at spark://ied:41942/jars/scopt_2.11-3.7.0.jar with timestamp 1645302276946
22/02/20 04:24:37 INFO Executor: Starting executor ID driver on host localhost
22/02/20 04:24:37 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 33814.
22/02/20 04:24:37 INFO NettyBlockTransferService: Server created on ied:33814
22/02/20 04:24:37 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
22/02/20 04:24:37 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, ied, 33814, None)
22/02/20 04:24:37 INFO BlockManagerMasterEndpoint: Registering block manager ied:33814 with 413.9 MB RAM, BlockManagerId(driver, ied, 33814, None)
22/02/20 04:24:37 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, ied, 33814, None)
22/02/20 04:24:37 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, ied, 33814, None)
22/02/20 04:24:39 INFO SparkContext: Starting job: reduce at SparkPi.scala:38
22/02/20 04:24:39 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:38) with 2 output partitions
22/02/20 04:24:39 INFO DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:38)
22/02/20 04:24:39 INFO DAGScheduler: Parents of final stage: List()
22/02/20 04:24:39 INFO DAGScheduler: Missing parents: List()
22/02/20 04:24:39 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents
22/02/20 04:24:40 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1936.0 B, free 413.9 MB)
22/02/20 04:24:40 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1256.0 B, free 413.9 MB)
22/02/20 04:24:40 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on ied:33814 (size: 1256.0 B, free: 413.9 MB)
22/02/20 04:24:40 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1161
22/02/20 04:24:40 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34) (first 15 tasks are for partitions Vector(0, 1))
22/02/20 04:24:40 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
22/02/20 04:24:40 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 7866 bytes)
22/02/20 04:24:40 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
22/02/20 04:24:40 INFO Executor: Fetching spark://ied:41942/jars/scopt_2.11-3.7.0.jar with timestamp 1645302276946
22/02/20 04:24:41 INFO TransportClientFactory: Successfully created connection to ied/192.168.225.100:41942 after 185 ms (0 ms spent in bootstraps)
22/02/20 04:24:41 INFO Utils: Fetching spark://ied:41942/jars/scopt_2.11-3.7.0.jar to /tmp/spark-1426c39a-4d28-40e6-84da-d2d5f6071ddf/userFiles-3f7a473d-50b4-46ed-be1f-d77e07167e09/fetchFileTemp2787747616090799670.tmp
22/02/20 04:24:42 INFO Executor: Adding file:/tmp/spark-1426c39a-4d28-40e6-84da-d2d5f6071ddf/userFiles-3f7a473d-50b4-46ed-be1f-d77e07167e09/scopt_2.11-3.7.0.jar to class loader
22/02/20 04:24:42 INFO Executor: Fetching spark://ied:41942/jars/spark-examples_2.11-2.4.4.jar with timestamp 1645302276946
22/02/20 04:24:42 INFO Utils: Fetching spark://ied:41942/jars/spark-examples_2.11-2.4.4.jar to /tmp/spark-1426c39a-4d28-40e6-84da-d2d5f6071ddf/userFiles-3f7a473d-50b4-46ed-be1f-d77e07167e09/fetchFileTemp5384793568751348333.tmp
22/02/20 04:24:42 INFO Executor: Adding file:/tmp/spark-1426c39a-4d28-40e6-84da-d2d5f6071ddf/userFiles-3f7a473d-50b4-46ed-be1f-d77e07167e09/spark-examples_2.11-2.4.4.jar to class loader
22/02/20 04:24:42 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 910 bytes result sent to driver
22/02/20 04:24:42 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 7866 bytes)
22/02/20 04:24:42 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
22/02/20 04:24:42 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 867 bytes result sent to driver
22/02/20 04:24:42 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1654 ms on localhost (executor driver) (1/2)
22/02/20 04:24:42 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 139 ms on localhost (executor driver) (2/2)
22/02/20 04:24:42 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
22/02/20 04:24:42 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 2.597 s
22/02/20 04:24:42 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 2.956212 s
Pi is roughly 3.1441757208786045
22/02/20 04:24:42 INFO SparkUI: Stopped Spark web UI at http://ied:4040
22/02/20 04:24:42 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
22/02/20 04:24:42 INFO MemoryStore: MemoryStore cleared
22/02/20 04:24:42 INFO BlockManager: BlockManager stopped
22/02/20 04:24:42 INFO BlockManagerMaster: BlockManagerMaster stopped
22/02/20 04:24:42 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
22/02/20 04:24:42 INFO SparkContext: Successfully stopped SparkContext
22/02/20 04:24:42 INFO ShutdownHookManager: Shutdown hook called
22/02/20 04:24:42 INFO ShutdownHookManager: Deleting directory /tmp/spark-1426c39a-4d28-40e6-84da-d2d5f6071ddf
22/02/20 04:24:42 INFO ShutdownHookManager: Deleting directory /tmp/spark-e8fe131d-a733-466f-9665-4277ace75a06
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
8、使用Scala版本Spark-Shell
- 执行 spark-shell 命令启动Scala版的Spark-Shell
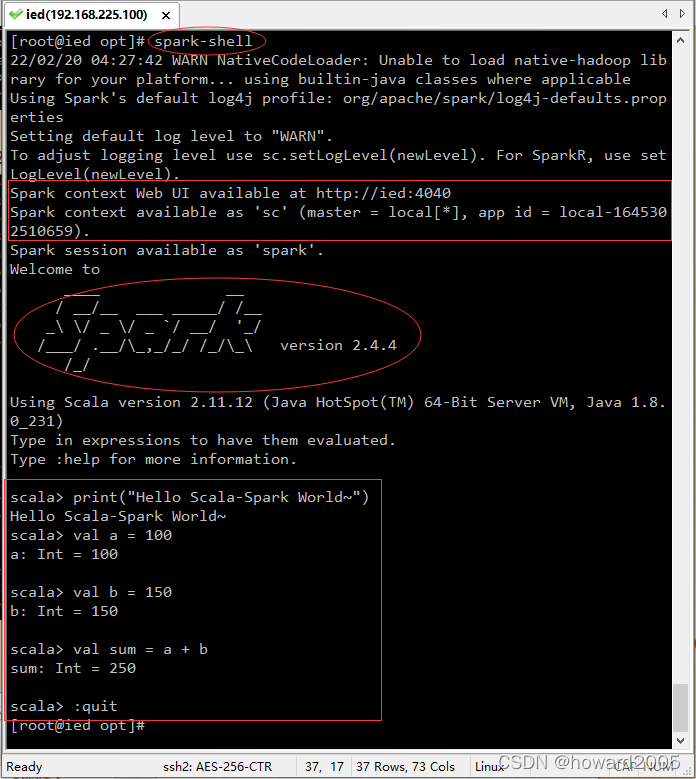
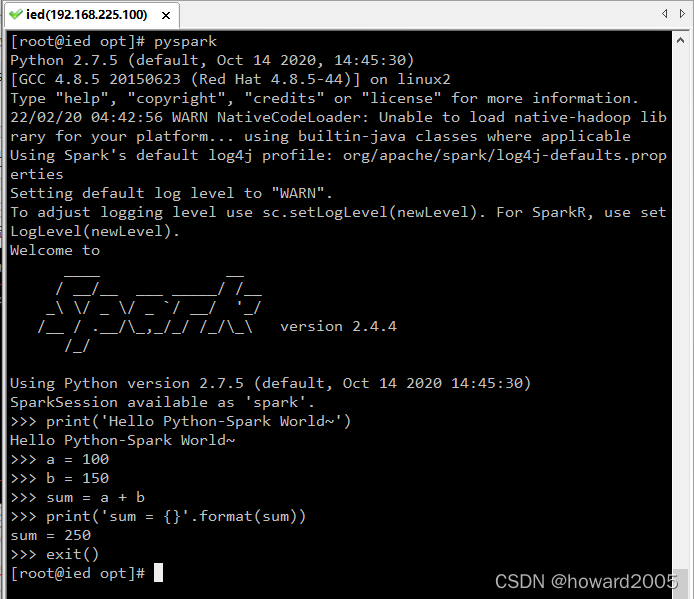
9、使用Python版本Spark-Shell
- 执行 pyspark 命令启动Python版的Spark-Shell
- 上传test.txt文件到/opt目录
- 执行 pyspark 启动 spark shell
- Spark 中的RDD (Resilient Distributed Dataset) 就是一个不可变的分布式对象集合。每个RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含Python、Java、Scala 中任意类型的对象,甚至可以包含用户自定义的对象。用户可以使用两种方法创建RDD:读取一个外部数据集,或在驱动器程序里分发驱动器程序中的对象集合(比如list 和set)。
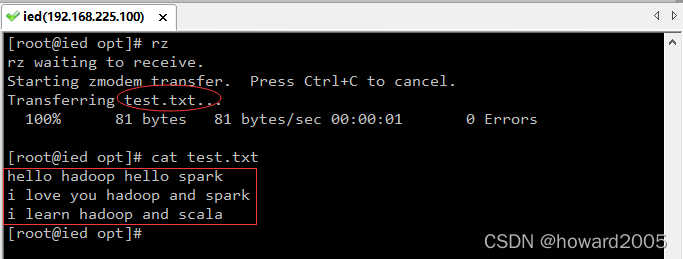
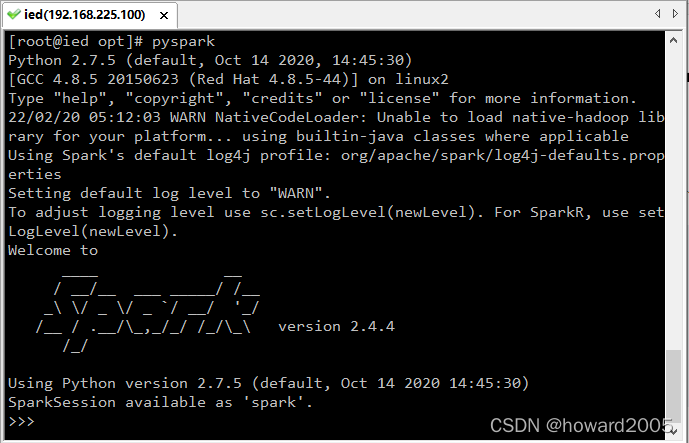
例1、在Python 中使用textFile() 创建一个字符串的RDD
>>> lines = sc.textFile('test.txt')
创建出来后,RDD 支持两种类型的操作: 转化操作(transformation) 和行动操作(action)。转化操作会由一个RDD 生成一个新的RDD。另一方面,行动操作会对RDD 计算出一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储系统(如HDFS)中。
例2、调用转化操作filter()
>>> sparkLines = lines.filter(lambda line: 'spark' in line)
例3、调用first() 行动操作
>>> sparkLines.first()
‘hello hadoop hello spark’
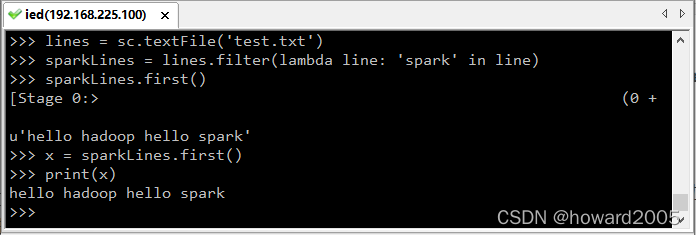
转化操作和行动操作的区别在于Spark 计算RDD 的方式不同。虽然你可以在任何时候定义新的RDD,但Spark 只会惰性计算这些RDD。它们只有第一次在一个行动操作中用到时,才会真正计算。这种策略刚开始看起来可能会显得有些奇怪,不过在大数据领域是很有道理的。比如,看看例2 和例3,我们以一个文本文件定义了数据,然后把其中包含spark的行筛选出来。如果Spark 在我们运行lines = sc.textFile(…) 时就把文件中所有的行都读取并存储起来,就会消耗很多存储空间,而我们马上就要筛选掉其中的很多数据。相反, 一旦Spark 了解了完整的转化操作链之后,它就可以只计算求结果时真正需要的数据。事实上,在行动操作first() 中,Spark 只需要扫描文件直到找到第一个匹配的行为止,而不需要读取整个文件。
三、Spark运行架构及原理
文章来源: howard2005.blog.csdn.net,作者:howard2005,版权归原作者所有,如需转载,请联系作者。
原文链接:howard2005.blog.csdn.net/article/details/123018812

- 点赞
- 收藏
- 关注作者
评论(0)