mysql性能优化:单表1400w查询最后十条数据(耗时0.036s)

排查问题发现线上mysql有个表数据量达到了1.4kw,观察了下,日增量大概40-50w的样子
突然联想到一个场景,如果我要拿这1.4kw数据中的最后十条怎么办(这就是所谓的深度分页)
本着理科生有问题解决问题,没问题制造问题来解决的心态
开始了性能压榨

先来看常规查询(公平起见,全部用select *)

我的天,用了19s,这要是再结合一些复杂查询,不得30+s,这谁顶得住啊
分析原因
不用想,这个sql肯定是没走索引了

看type类型,ALL代表进行了全表扫描
试图优化
既然没走索引那我就让你走索引
看了下表结构,只有一个字段建了索引,哪个字段我就不说了,秘密,我就直接用主键吧
select * 没走索引,那select id呢

时间缩短了不少,但是我想要所有字段,不可能只查id啊
所以

这不就妥了,我先查id,再通过id拿其它字段,靠谱~
到现在,原本 19s 的 sql 已经缩短到3s,nice
看下执行计划,我们得知道为啥变快了
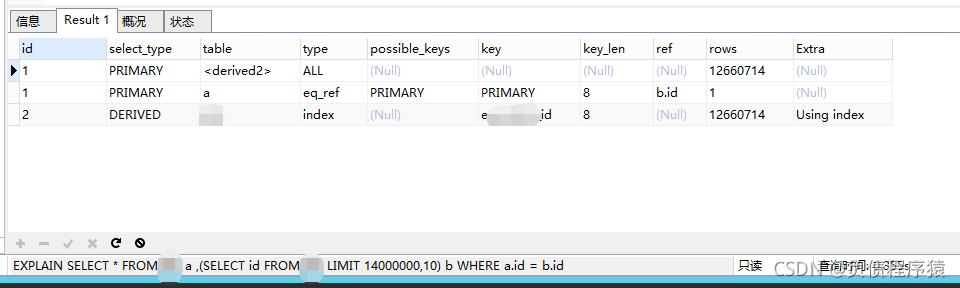
看几个关键字段,type、key、extra,不算完美,但也还行,毕竟我们这种非DBA选手,sql能力有限
顺便科普下这个执行计划,看id列,1 1 2,执行顺序是第三行 第一行 第二行,记住口诀:id不同大的先走,id相同,从上往下
所以第一行中type列的ALL并不是指进行了全部扫描,而是表示对子查询中的结果集进行了全部扫描,很合理
关于详细执行计划,出门右转 mysql执行计划explain属性解析
一千四百万数据量深度分页能3秒,算不错了,但是还能不能继续优化?
能
教你个绝活,老板见了都要激动的拍打轮椅

你没有看错,就是0.036s,刺不刺激
虽然性能嘎嘎猛,但局限性太大,首先你得是自增id,并且id不能有断层,这对表维护要求很高,每次删除了数据都得清一下旧id,就图个乐吧,量大了老老实实上es、ck,要么就让你的用户接受查询慢一点
总结
//常规分页
SELECT * FROM table_name limit 14000000,10//耗时19.426s
//先查id ,写法很多,看个人习惯
SELECT * FROM table_name a,(SELECT id FROM table_name limit 14000000,10) b WHERE a.id = b.id //耗时3.068
//如果你的表有自增id(并且没断层),就这么写,效率直接起飞
SELECT * FROM table_name WHERE id>14000000 LIMIT 10 //耗时0.036
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
完结
撒花
ok我话说完
文章来源: huangjie.blog.csdn.net,作者:负债程序猿,版权归原作者所有,如需转载,请联系作者。
原文链接:huangjie.blog.csdn.net/article/details/121619889

- 点赞
- 收藏
- 关注作者
评论(0)