【数据结构与算法】之深入解析“删除排序链表中的重复元素II”的求解思路与算法示例

【摘要】
一、题目要求
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字,返回已排序的链表。示例 1:
输入:head = [1,2,3,3,4,4,5]
输出:[...
一、题目要求
- 给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字,返回已排序的链表。
- 示例 1:

输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
- 1
- 2
- 示例 2:

输入:head = [1,1,1,2,3]
输出:[2,3]
- 1
- 2
- 提示:
-
- 链表中节点数目在范围 [0, 300] 内;
-
- -100 <= Node.val <= 100;
-
- 题目数据保证链表已经按升序排列。
二、求解算法
① 递归
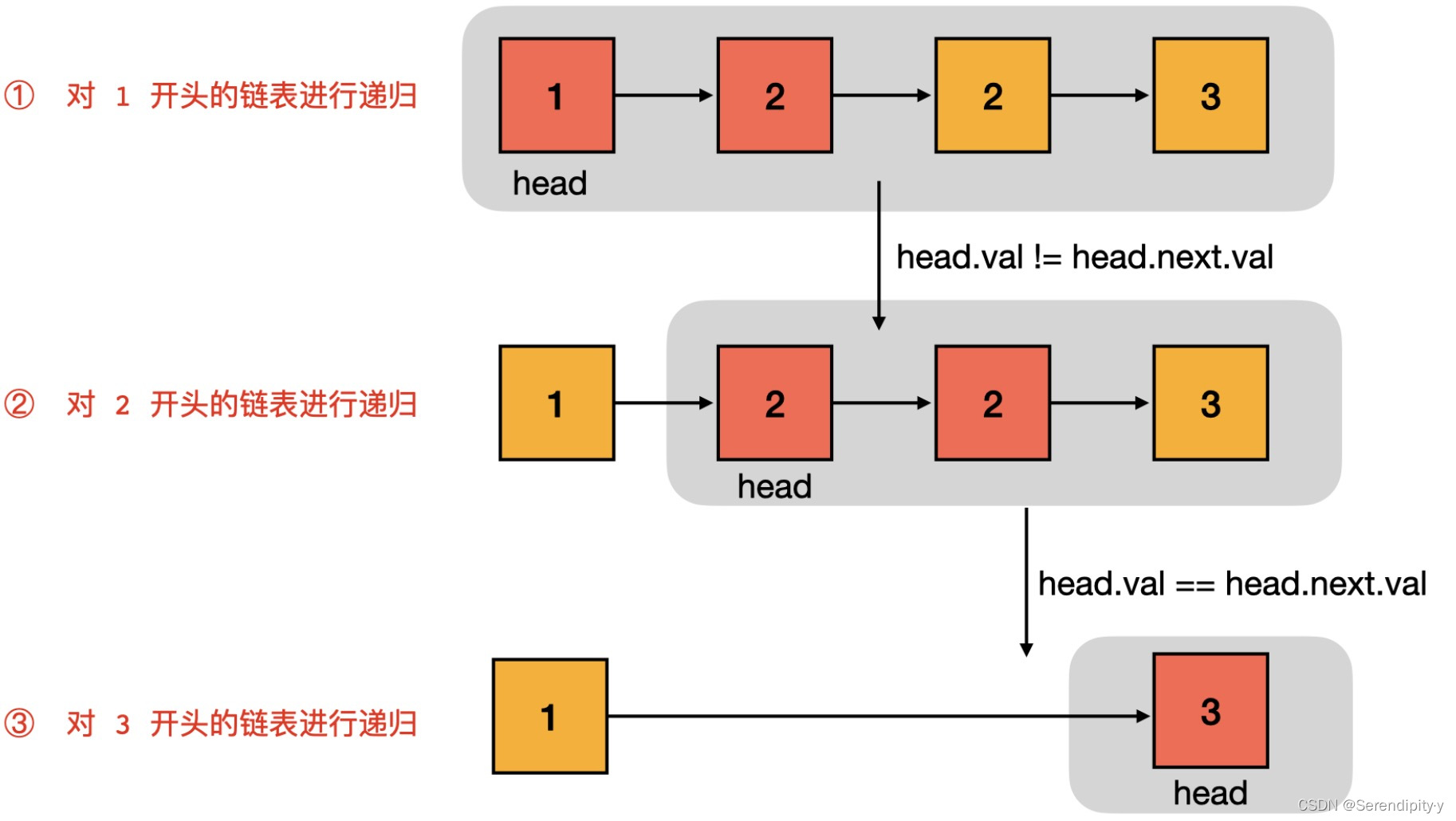
- 递归函数直接使用题目给出的函数 deleteDuplicates(head) ,它的含义是删除以 head 作为开头的有序链表中,值出现重复的节点。
- 递归的终止条件就是能想到的基本的、不用继续递归处理的 case:
-
- 如果 head 为空,那么肯定没有值出现重复的节点,直接返回 head;
-
- 如果 head.next 为空,那么说明链表中只有一个节点,也没有值出现重复的节点,也直接返回 head。
- 递归调用:
-
- 如果 head.val != head.next.val ,说明头节点的值不等于下一个节点的值,所以当前的 head 节点必须保留;但是 head.next 节点要不要保留呢?我们还不知道,需要对 head.next 进行递归,即对 head.next 作为头节点的链表,去除值重复的节点。所以 head.next = self.deleteDuplicates(head.next)。
-
- 如果 head.val == head.next.val ,说明头节点的值等于下一个节点的值,所以当前的 head 节点必须删除,并且 head 之后所有与 head.val 相等的节点也都需要删除;删除到哪个节点为止呢?需要用 move 指针一直向后遍历寻找到与 head.val 不等的节点。此时 move 之前的节点都不保留了,因此返回 deleteDuplicates(move)。
- 题目返回删除了值重复的节点后剩余的链表,结合上面两种递归调用的情况:
-
- 如果 head.val != head.next.val ,头结点需要保留,因此返回的是 head;
-
- 如果 head.val == head.next.val ,头结点需要删除,需要返回的是 deleteDuplicates(move)。
- 对链表 1 -> 2 -> 2 -> 3 递归的过程如下:
- C++ 示例:
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (!head || !head->next) {
return head;
}
if (head->val != head->next->val) {
head->next = deleteDuplicates(head->next);
} else {
ListNode* move = head->next;
while (move && head->val == move->val) {
move = move->next;
}
return deleteDuplicates(move);
}
return head;
}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- Python 示例:
class Solution(object):
def deleteDuplicates(self, head):
if not head or not head.next:
return head
if head.val != head.next.val:
head.next = self.deleteDuplicates(head.next)
else:
move = head.next
while move and head.val == move.val:
move = move.next
return self.deleteDuplicates(move)
return head
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
② 一次遍历
- 跟递归方法中的 while 语句跳过所有值相等的节点的思路是一样的:如果 cur.val == cur.next.val 说明两个相邻的节点值相等,所以继续后移,一直找到 cur.val != cur.next.val ,此时的 cur.next 就是值不等的节点。
- 比如: 1 -> 2 -> 2 -> 2 -> 3,用一个 pre 指向 1;当 cur 指向第一个 2 的时候,发现 cur.val == cur.next.val,所以出现了值重复的节点啊,所以 cur 一直后移到最后一个 2 的时候,发现 cur.val != cur.next.val ,此时 cur.next = 3 ,所以 pre.next = cur.next ,即让1 的 next 节点是 3,就把中间的所有 2 都删除。
- 代码中用到了一个常用的技巧:dummy 节点,也叫做“哑节点”,它在链表的迭代写法中非常常见,因为对于本题而言,可能会删除头结点 head,为了维护一个不变的头节点,所以添加了 dummy,让dummy.next = head,这样即使 head 被删了,那么会操作 dummy.next 指向新的链表头部,所以最终返回的也是 dummy.next。
- C++ 示例:
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (!head || !head->next) return head;
ListNode* preHead = new ListNode(0);
preHead->next = head;
ListNode* pre = preHead;
ListNode* cur = head;
while (cur) {
//跳过当前的重复节点,使得cur指向当前重复元素的最后一个位置
while (cur->next && cur->val == cur->next->val) {
cur = cur->next;
}
if (pre->next == cur) {
//pre和cur之间没有重复节点,pre后移
pre = pre->next;
} else {
//pre->next指向cur的下一个位置(相当于跳过了当前的重复元素)
//但是pre不移动,仍然指向已经遍历的链表结尾
pre->next = cur->next;
}
cur = cur->next;
}
return preHead->next;
}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- Python 示例:
class Solution(object):
def deleteDuplicates(self, head):
if not head or not head.next:
return head
dummy = ListNode(0)
dummy.next = head
pre = dummy
cur = head
while cur:
# 跳过当前的重复节点,使得cur指向当前重复元素的最后一个位置
while cur.next and cur.val == cur.next.val:
cur = cur.next
if pre.next == cur:
# pre和cur之间没有重复节点,pre后移
pre = pre.next
else:
# pre->next指向cur的下一个位置(相当于跳过了当前的重复元素)
# 但是pre不移动,仍然指向已经遍历的链表结尾
pre.next = cur.next
cur = cur.next
return dummy.next
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
③ 利用计数,两次遍历
- 这个做法忽略了链表有序这个性质,使用了两次遍历,第一次遍历统计每个节点的值出现的次数,第二次遍历的时候,如果发现 head.next 的 val 出现次数不是 1 次,则需要删除 head.next。
- C++ 示例:
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
unordered_map<int, int> m;
ListNode dummy(0);
ListNode* dummy_move = &dummy;
ListNode* move = head;
while (move) {
m[move->val]++;
move = move->next;
}
move = head;
while (move) {
if (m[move->val] == 1) {
dummy_move->next = move;
dummy_move = dummy_move->next;
}
move = move->next;
}
dummy_move->next = nullptr;
return dummy.next;
}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- Python 示例:
class Solution:
def deleteDuplicates(self, head):
dummy = ListNode(0)
dummy.next = head
val_list = []
while head:
val_list.append(head.val)
head = head.next
counter = collections.Counter(val_list)
head = dummy
while head and head.next:
if counter[head.next.val] != 1:
head.next = head.next.next
else:
head = head.next
return dummy.next
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
④ 一次遍历(LeetCode 官方解法)
- 由于给定的链表是排好序的,因此重复的元素在链表中出现的位置是连续的,因此只需要对链表进行一次遍历,就可以删除重复的元素。由于链表的头节点可能会被删除,因此需要额外使用一个哑节点(dummy node)指向链表的头节点。
- 具体地,从指针 cur 指向链表的哑节点,随后开始对链表进行遍历。如果当前 cur.next 与 cur.next.next 对应的元素相同,那么就需要将 cur.next 以及所有后面拥有相同元素值的链表节点全部删除。我们记下这个元素值 x,随后不断将 cur.next 从链表中移除,直到 cur.next 为空节点或者其元素值不等于 x 为止。此时,我们将链表中所有元素值为 x 的节点全部删除。
- 如果当前 cur.next 与 cur.next.next 对应的元素不相同,那么说明链表中只有一个元素值为 cur.next 的节点,那么就可以将 cur 指向 cur.next。
- 当遍历完整个链表之后,返回链表的的哑节点的下一个节点 dummy.next 即可。
- 需要注意 cur.next 以及 cur.next.next 可能为空节点,如果不加以判断,可能会产生运行错误。
- C++ 示例:
class Solution {
public:
ListNode* deleteDuplicates(ListNode* head) {
if (!head) {
return head;
}
ListNode* dummy = new ListNode(0, head);
ListNode* cur = dummy;
while (cur->next && cur->next->next) {
if (cur->next->val == cur->next->next->val) {
int x = cur->next->val;
while (cur->next && cur->next->val == x) {
cur->next = cur->next->next;
}
}
else {
cur = cur->next;
}
}
return dummy->next;
}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- Python 示例:
class Solution:
def deleteDuplicates(self, head: ListNode) -> ListNode:
if not head:
return head
dummy = ListNode(0, head)
cur = dummy
while cur.next and cur.next.next:
if cur.next.val == cur.next.next.val:
x = cur.next.val
while cur.next and cur.next.val == x:
cur.next = cur.next.next
else:
cur = cur.next
return dummy.next
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
文章来源: blog.csdn.net,作者:Serendipity·y,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/Forever_wj/article/details/122881183

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)