【算法岗面试】某小厂面试题

零、项目提问
要按照背景、难点、解决方案和结果四个方面讲。
0.1 背景
有时候面试官和你的方向不同,不太清楚你的项目是解决什么问题,这时候就需要快速清晰地讲出这个项目的背景。包括但不限于 满足什么需求,在什么场景,是什么样的任务。
0.2 难点
一个项目中肯定有它的难点,是这个项目着力去解决的问题,如果是一个非常简单的事情肯定不太值得说。需要提炼出项目中困难的点,例如缺少数据、大模型训练成本高、已有的方法忽略了XX信息/条件等等。
0.3 解决方案
项目中做的事情,包括但不限于 怎样分析问题,针对难点如何设计。面试官经常会问的一个问题是为什么用了A而不用B,A比B有什么优势,这种问题要提前做好准备。这里是面试过程中非常体现面试官水平的地方,厉害的面试官会在这里问很多尖锐深刻的问题。
0.4 结果
结果最好要以直观的方式展现,例如对比基线准确率提升XX%,比赛排名XX,PV增加XX%等。
一、关于bert模型以及蒸馏的问题:
1.1 蒸馏的思想,为什么要蒸馏?
知识蒸馏(Knowledge Distillation,KD)是常用的知识迁移方法,通常由教师(Teacher)模型和学生(student)模型构成。知识蒸馏就像老师教学生的过程,将知识从教师模型传递给学生模型,使得学生模型尽量与教师模型接近。
一般地,大模型往往是单个复杂网络或者是若干网络的集合,拥有良好的性能和泛化能力,而小模型因为网络规模较小,表达能力有限。因此,可以利用大模型学习到的知识去指导小模型训练,使得小模型具有与大模型相当的性能,但是参数数量大幅降低,从而实现模型压缩与加速,这就是知识蒸馏与迁移学习在模型优化中的应用。
1.2 蒸馏中的学生模型是?
1.3 有哪些蒸馏方式?
- 三种经典的基于知识蒸馏的预训练模型:
- DistilBERT(基于三重损失);
- TinyBERT(主要使用了额外的词向量层蒸馏和中间层蒸馏进一步提升知识蒸馏效果);
- MobileBERT(瘦身版的 Bert-large模型)。

1、 离线蒸馏
离线蒸馏方式即为传统的知识蒸馏,如上图(a)。用户需要在已知数据集上面提前训练好一个teacher模型,然后在对student模型进行训练的时候,利用所获取的teacher模型进行监督训练来达到蒸馏的目的,而且这个teacher的训练精度要比student模型精度要高,差值越大,蒸馏效果也就越明显。一般来讲,teacher的模型参数在蒸馏训练的过程中保持不变,达到训练student模型的目的。蒸馏的损失函数distillation loss计算teacher和student之前输出预测值的差别,和student的loss加在一起作为整个训练loss,来进行梯度更新,最终得到一个更高性能和精度的student模型。
2、 半监督蒸馏
半监督方式的蒸馏利用了teacher模型的预测信息作为标签,来对student网络进行监督学习,如上图(b)。那么不同于传统离线蒸馏的方式,在对student模型训练之前,先输入部分的未标记的数据,利用teacher网络输出标签作为监督信息再输入到student网络中,来完成蒸馏过程,这样就可以使用更少标注量的数据集,达到提升模型精度的目的。
3、 自监督蒸馏
自监督蒸馏相比于传统的离线蒸馏的方式是不需要提前训练一个teacher网络模型,而是student网络本身的训练完成一个蒸馏过程,如上图(c)。具体实现方式 有多种,例如先开始训练student模型,在整个训练过程的最后几个epoch的时候,利用前面训练的student作为监督模型,在剩下的epoch中,对模型进行蒸馏。这样做的好处是不需要提前训练好teacher模型,就可以变训练边蒸馏,节省整个蒸馏过程的训练时间。
1.4 Bert 的输入是什么?

- 词向量
word_embeddings,上文中 subword 对应的嵌入。 - 块向量
token_type_embeddings,用于表示当前词所在的句子,辅助区别句子与 padding、句子对间的差异。 - 位置向量
position_embeddings,句子中每个词的位置嵌入,用于区别词的顺序。和 transformer 论文中的设计不同,这一块是训练出来的,而不是通过Sinusoidal函数计算得到的固定嵌入。一般认为这种实现不利于拓展性(难以直接迁移到更长的句子中)。
三个 embedding 不带权重的相加,并通过一层 LayerNorm+dropout 后输出,其大小为(batch_size, sequence_length, hidden_size)。
1.5 字向量的 embedding 怎么训练得到的?
二、关于 transformer 的问题:
2.1 self-attention 理解和作用,为什么要除以根号dk?
如果我们计算句子中第一个位置单词的 Attention Score(注意力分数),那么第一个分数就是 q1 和 k1 的内积,第二个分数就是 q1 和 k2 的点积。以此类推。
而每个Attention Score(注意力分数)除以 ( d k e y ) \sqrt(d_{key}) (dkey) ( d k e y d_{key} dkey是 Key 向量的长度),当然也可以除以其他数,除以一个数是为了在反向传播时,求取梯度更加稳定(避免因为向量维度d过大导致点积结果过大)。
2.2 为什么需要进行 Multi-head Attention?
可以类比CNN中同时使用多个滤波器的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息。
论文中是这么说的:Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
关于different representation subspaces,举一个不一定妥帖的例子:当你浏览网页的时候,你可能在颜色方面更加关注深色的文字,而在字体方面会去注意大的、粗体的文字。这里的颜色和字体就是两个不同的表示子空间。同时关注颜色和字体,可以有效定位到网页中强调的内容。使用多头注意力,也就是综合利用各方面的信息/特征。
2.3 Layer normlization的作用?
2.4 LN 和 BN 的区别?
(1)两者的区别
- 从操作上看:BN是对同一个batch内的所有数据的同一个特征数据进行操作;而LN是对同一个样本进行操作。
- 从特征维度上看:BN中,特征维度数=均值or方差的个数;LN中,一个batch中有
batch_size个均值和方差。
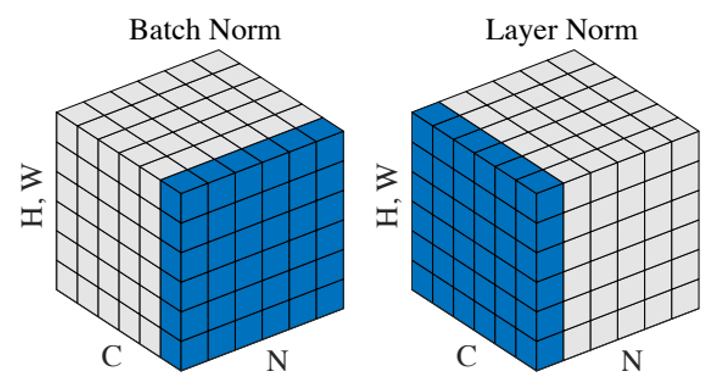
如在NLP中上图的C、N、H,W含义:
N:N句话,即batchsize;
C:一句话的长度,即seqlen;
H,W:词向量维度embedding dim。
(2)BN和LN的关系
- BN 和 LN 都可以比较好的抑制梯度消失和梯度爆炸的情况。BN不适合RNN、transformer等序列网络,不适合文本长度不定和
batchsize较小的情况,适合于CV中的CNN等网络; - 而LN适合用于NLP中的RNN、transformer等网络,因为sequence的长度可能是不一致的。
- 栗子:如果把一批文本组成一个batch,BN就是对每句话的第一个词进行操作,BN针对每个位置进行缩放就不符合NLP的规律了。
(3)小结
(1)经过BN的归一化再输入激活函数,得到的值大部分会落入非线性函数的线性区,导数远离导数饱和区,避免了梯度消失,这样来加速训练收敛过程。
(2)归一化技术就是让每一层的分布稳定下来,让后面的层能在前面层的基础上“安心学习”。BatchNorm就是通过对batch size这个维度归一化来让分布稳定下来(但是BN没有解决ISC问题)。LayerNorm则是通过对Hidden size这个维度归一。
三、与Python有关的问题:
3.1 怎么进行维度交换(transpose)、维度转换(reshape)?
3.2 点积和矩阵相乘的区别?
点积:维度完全一致的两个向量相乘,得到一个标量。
矩阵相乘:( X ∗ N N ∗ Y = = > X ∗ Y X*N N*Y==>X*Y X∗NN∗Y==>X∗Y)
3.3 怎么对字典的值进行排序?
sorted还能对字典按照value值进行排序,这里结合了lambda表达式,其中key = lambda kv:(kv[1], kv[0])的意思是先按照kv[1]对应的值进行排序(默认从小到大),然后按照kv[0]对应的值进行排序(默认从小到大)。
def dictionairy():
# 声明字典
key_value ={}
# 初始化
key_value[2] = 56
key_value[1] = 2
key_value[5] = 12
key_value[4] = 24
key_value[6] = 18
key_value[3] = 323
print ("按值(value)排序:")
print(sorted(key_value.items(), key = lambda kv:(kv[1], kv[0])))
def main():
dictionairy()
if __name__=="__main__":
main()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
结果为:
按值(value)排序:
[(1, 2), (5, 12), (6, 18), (4, 24), (2, 56), (3, 323)]
- 1
- 2
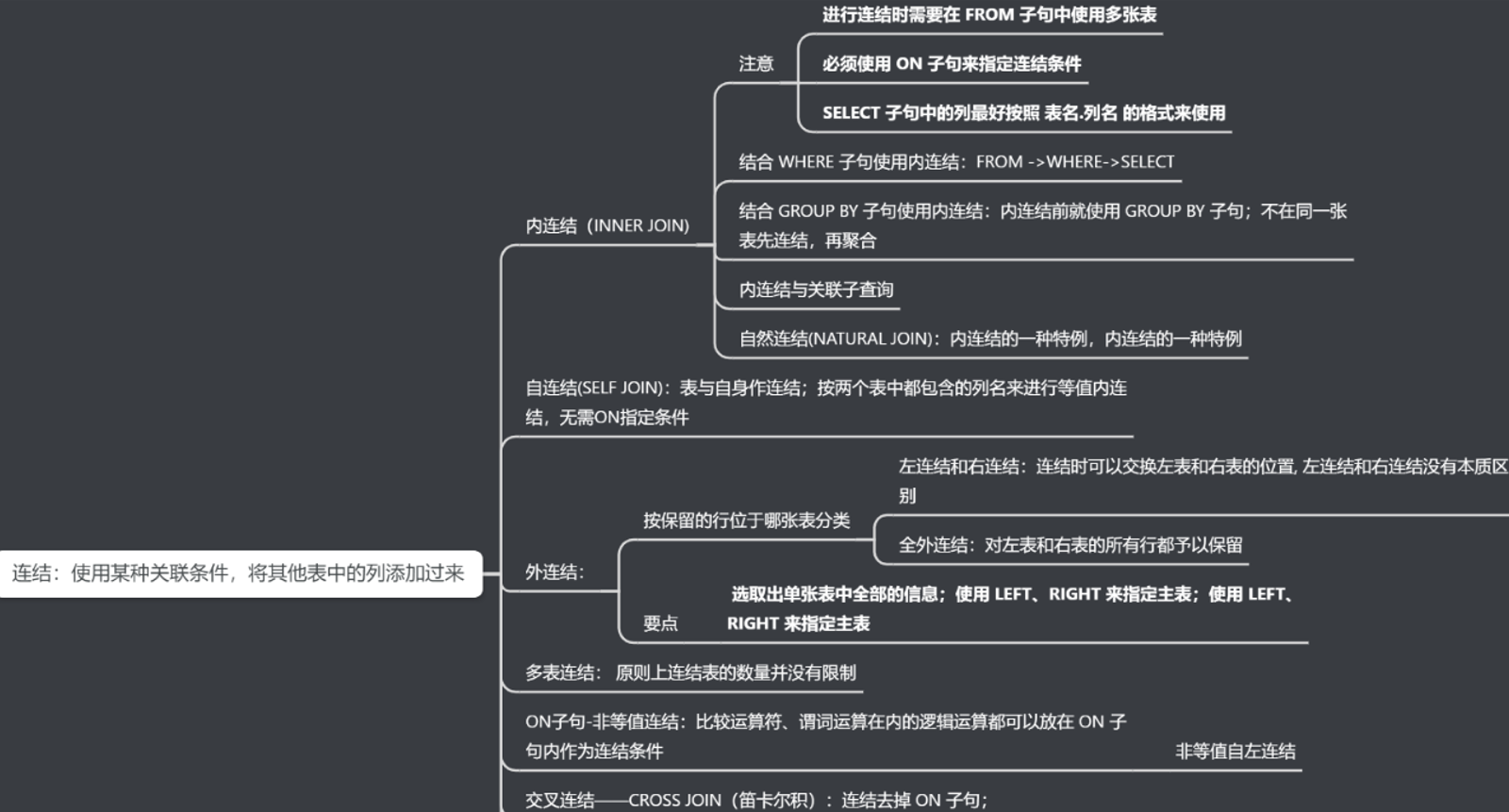
3.4 SQL:内连接、左连接、右连接的区别(结果集中右表中的字段必须全部存在且显示)?
3.5 Python在内存上做了哪些优化?
3.6 怎么节省内存?
(将数值型数据转化为32位或16位,手动回收不需要用的变量)
3.7 Pandas库怎么读取超大型文件?
(分块读取)
3.8 爬 虫:
a.多进程和多线程的区别?
我们直接编写的爬虫程序是单线程的,在数据需求量不大时它能够满足我们的需求。
但如果数据量很大,比如要通过访问数百数千个url去爬取数据,单线程必须等待当前url访问完毕并且数据提取保存完成后才可以对下一个url进行操作,一次只能对一个url进行操作;
我们使用多线程/多进程的话,就可以实现对多个url同时进行操作。这样就能大大缩减了爬虫运行时间。
b.有哪些解决反爬的手段?
反反爬的主要思路就是:尽可能的去模拟浏览器,浏览器在如何操作,代码中就如何去实现。浏览器先请求了地址url1,保留了cookie在本地,之后请求地址url2,带上了之前的cookie,代码中也可以这样去实现。
很多时候,爬 虫中携带的headers字段,cookie字段,url参数,post的参数很多,不清楚哪些有用,哪些没用的情况下,只能够去尝试,因为每个网站都是不相同的。
通过headers中的User-Agent字段来反爬:通过User-Agent字段反爬的话,只需要给他在请求之前添加User-Agent即可,更好的方式是使用User-Agent池来解决,我们可以考虑收集一堆User-Agent的方式,或者是随机生成User-Agen
四、算法题:
4.1 无重复字符的最长子串
滑动窗口:【LeetCode3】无重复字符的最长子串(滑动窗口)
4.2 判断链表是否有环、链表环的入口
快慢指针,其实和【环形链表 I】差不多,那个是判断是否有环,现在这题是找出开始入环的第一个结点。同样适用快慢指针,由下图分析,因为快指针的速度设置为慢指针的2倍(每次满指针走1步,快指针走2步),由2(F+a)= F+a+b+a,得到F=b的关键信息。所以当两个指针第一次相遇后,我们让快指针回到head原点,这时候让快指针和满指针以相同速度前进,即快指针走F步,慢指针走b步,就能够到达所求的环入口,进行相遇了。

六、场景题:
怎么把问题分配到多级的目录里去?
Reference
[1] 一分钟带你认识深度学习中的知识蒸馏
[2] 牛客算法面试题
文章来源: andyguo.blog.csdn.net,作者:山顶夕景,版权归原作者所有,如需转载,请联系作者。
原文链接:andyguo.blog.csdn.net/article/details/122911784

- 点赞
- 收藏
- 关注作者
评论(0)