【愚公系列】2022年02月 攻防世界-进阶题-MISC-84(mysql)

前言
undrop是一款针对mysql innodb的数据恢复工具,通过扫描文件或磁盘设备,然后解析innodb数据页进而恢复丢失的数据,对于drop、truncate以及文件损坏都很有帮助。本文介绍drop操作后表结构的恢复过程。
innodb数据字典介绍
在做恢复演示之前,首先插播一段innodb数据字典的介绍。
innodb数据字典存储在系统表空间,主要是用于记录innodb核心的对象信息,比如表、索引、字段等。字典的本质是REDUNDANT行格式的innodb表,并且对用户不可见。
为了便于用户查看,innodb提供了一系列的字典视图,视图提供的信息和字典表完全相同,这一部分内容我们可以在information_schema中找到。如下,
mysql> use information_schema -A;
Database changed
mysql> show tables where Tables_in_information_schema like '%innodb_sys%';
+------------------------------+
| Tables_in_information_schema |
+------------------------------+
| INNODB_SYS_DATAFILES |
| INNODB_SYS_VIRTUAL |
| INNODB_SYS_INDEXES |
| INNODB_SYS_TABLES |
| INNODB_SYS_FIELDS |
| INNODB_SYS_TABLESPACES |
| INNODB_SYS_FOREIGN_COLS |
| INNODB_SYS_COLUMNS |
| INNODB_SYS_FOREIGN |
| INNODB_SYS_TABLESTATS |
+------------------------------+
10 rows in set (0.00 sec)
一、mysql
题目链接:https://adworld.xctf.org.cn/task/task_list?type=misc&number=1&grade=1&page=5
题目描述:我们在Mysql数据库中存放了flag,但是黑客已经把它删除了。你能找回来flag吗?

二、答题步骤
1.下载附件

发现mysql和sql脚本
2.解题方法
2.1 strings解法
strings ib_logfile0 | grep "flag"
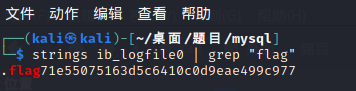
发现flag:71e55075163d5c6410c0d9eae499c977
2.2 Undrop for InnoDB解法
2.2.1 安装
undrop-for-innodb 在github上有,网址为:https://github.com/twindb/undrop-for-innodb
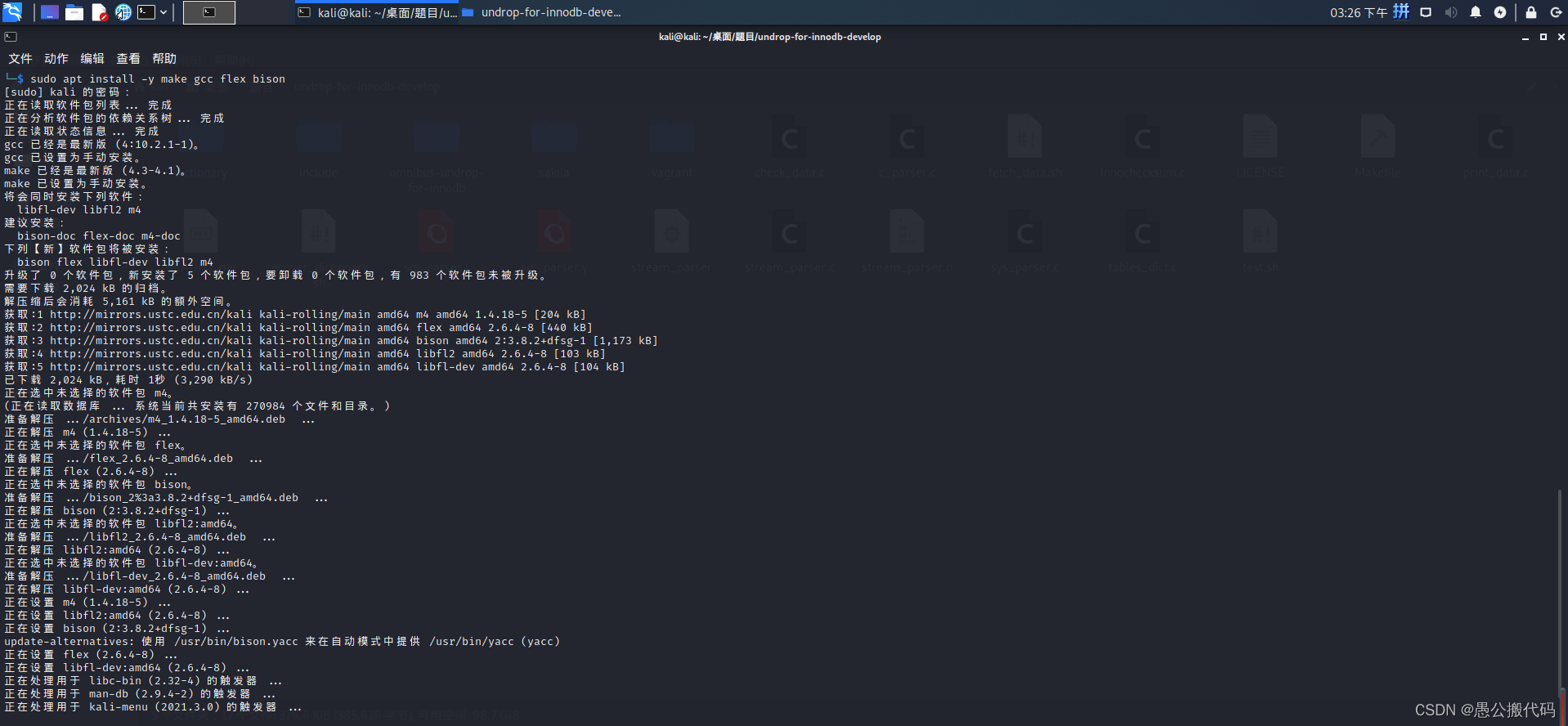
执行命令
sudo apt install -y make gcc flex bison
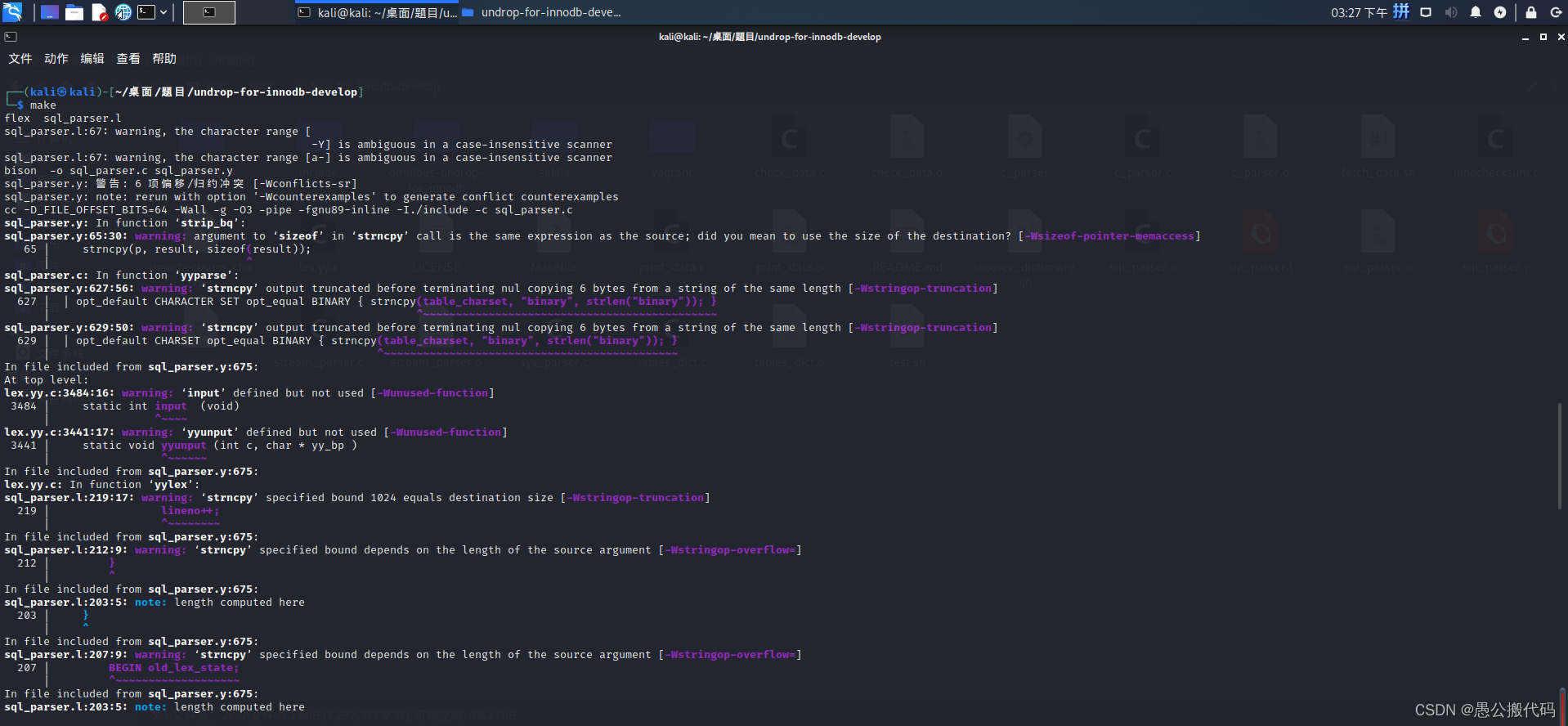
执行make安装:
make
到这里部署过程就结束了,这里介绍下几个重要的文件及目录:
- dictionary目录。存放字典sql脚本,用于恢复表结构的几张核心字典表的DDL语句
- sakila目录。测试schema
- stream_parser。可执行文件,用于扫描文件或者磁盘设备,目的是找出符合innodb格式的数据页,按照index_id进行组织
- c_parser。可执行文件,用于解析innodb数据页,获取行记录
- sys_parser。可执行文件,通过字典表记录恢复目标表的表结构
2.2.2 还原必要条件
一份ibdata1数据文件,一份要恢复的数据库的表结构
1.表结构
在structure.sql中看到了表的结构:
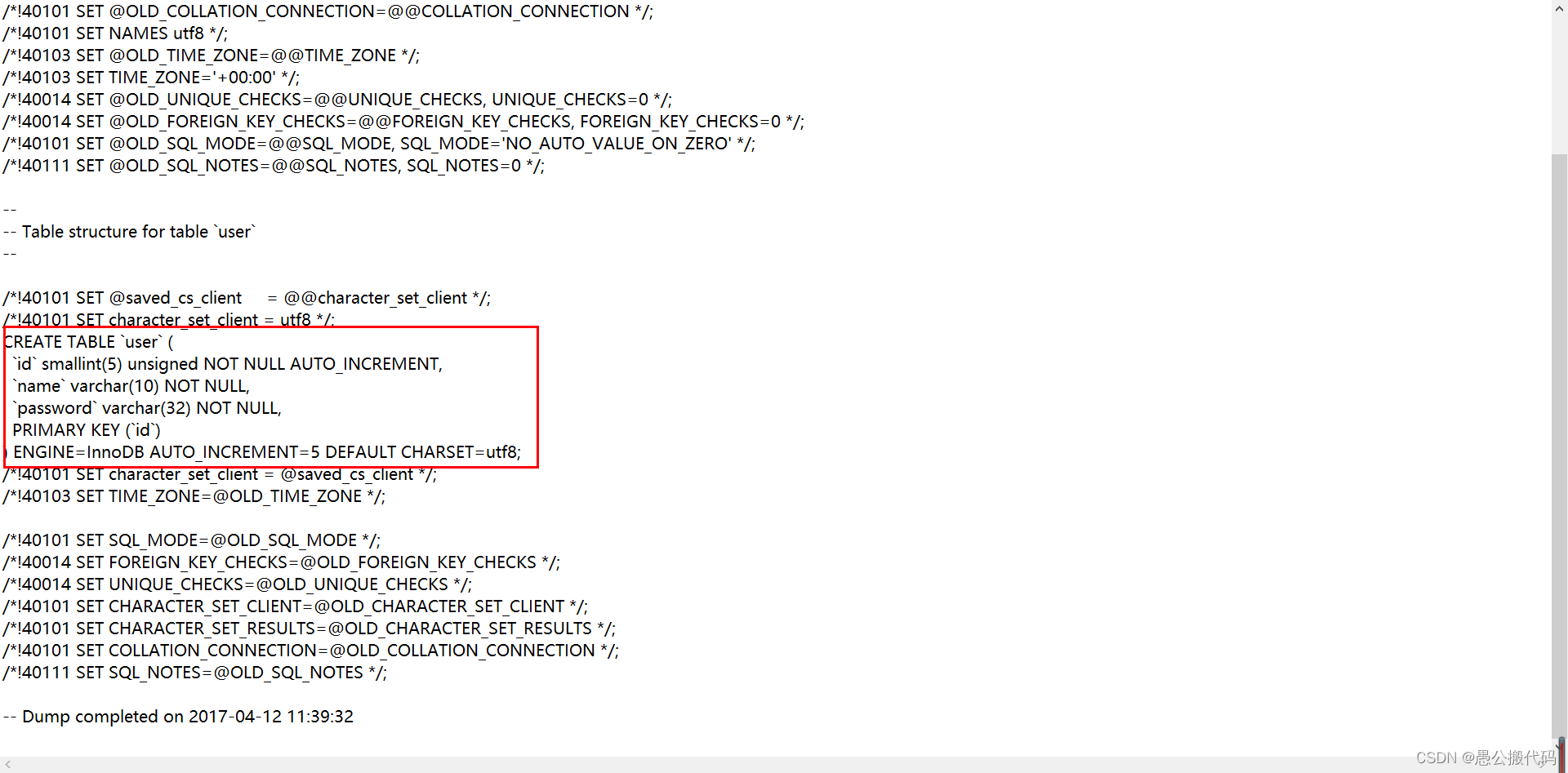
CREATE TABLE `user` (
`id` smallint(5) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL,
`password` varchar(32) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
2.ibdata1数据文件

2.2.3 解析数据文件
./stream_parser -f 01/ibdata1
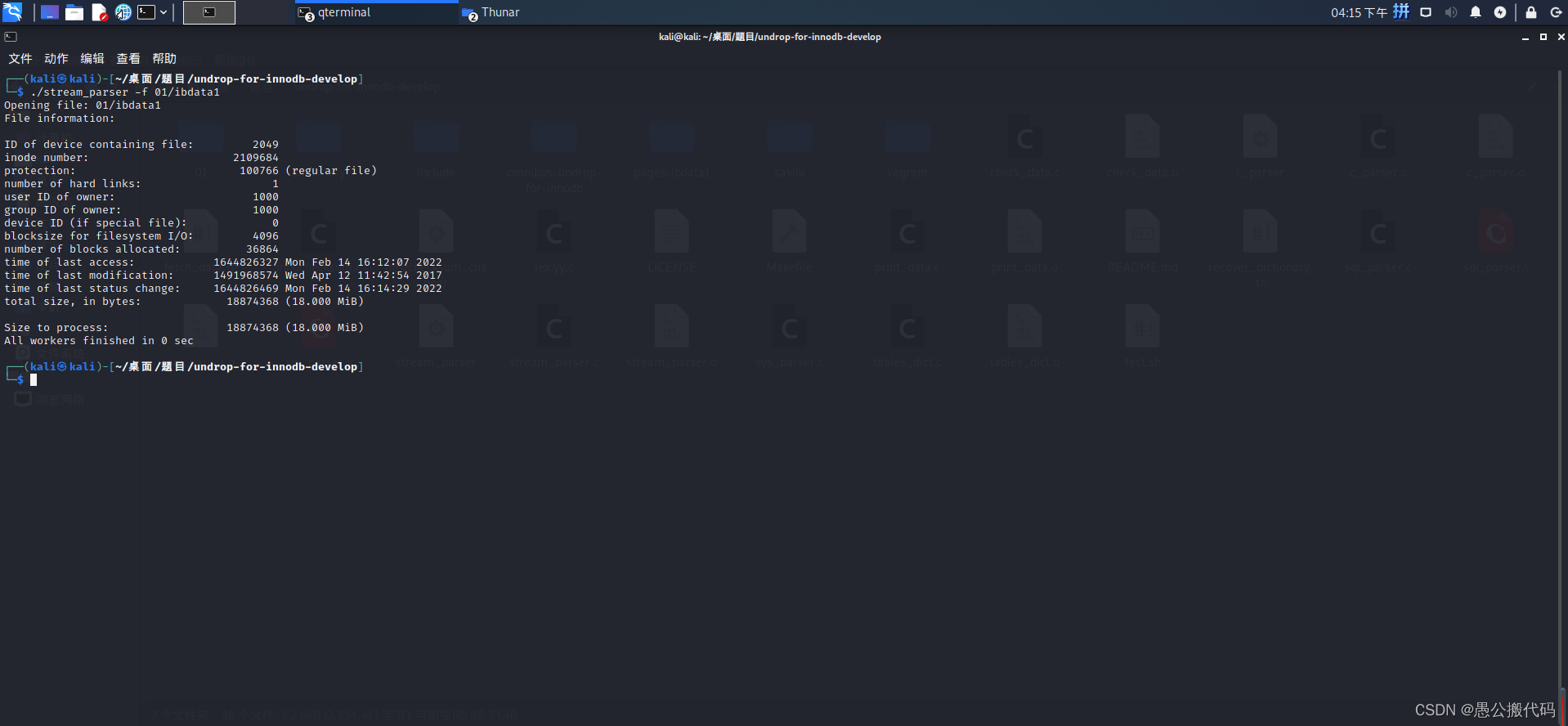
解析完成后,可以看到同目录下生成一个pages-ibdata1目录,其中包含两个子目录,一个是包含按索引排序的数据页目录,另一个是包含相关类型的数据目录:
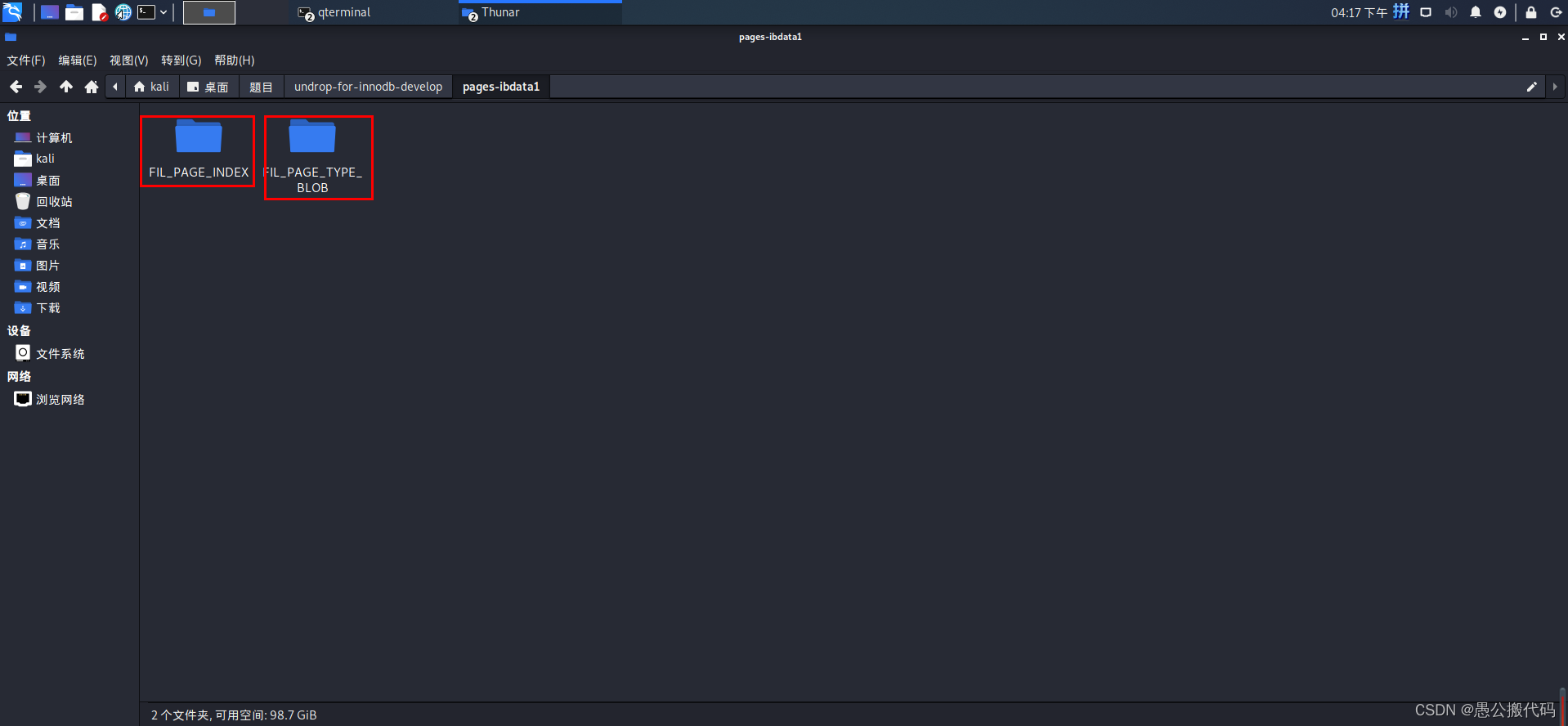
我们下面将主要关注的是第一个子目录即索引好的数据页目录,因为我们要恢复的数据就在里面,其中第一个页文件(0000000000000001.page)里包含所有数据库的表信息和相关的表索引信息,类似一个数据字典,可以使用项目提供的一个脚本recover_dictionary.sh将其内容放到一个test数据库里详细的查看。
2.2.4 解析页文件
既然第一个页文件包含所有数据库表的索引信息,我们就需要先解析它,以模拟mysql查询数据的过程,最终才能找到要恢复的数据。c_parser工具可以用来解析页文件,不过需要提供该页文件的一个内部结构(表结构)。
项目根目录下有个dictionary目录,里面就包含数据字典用到相关表结构,如用来解析第一个页文件的表结构在SYS_TABLES.sql文件
./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000001.page -t dictionary/SYS_TABLES.sql | grep ctf
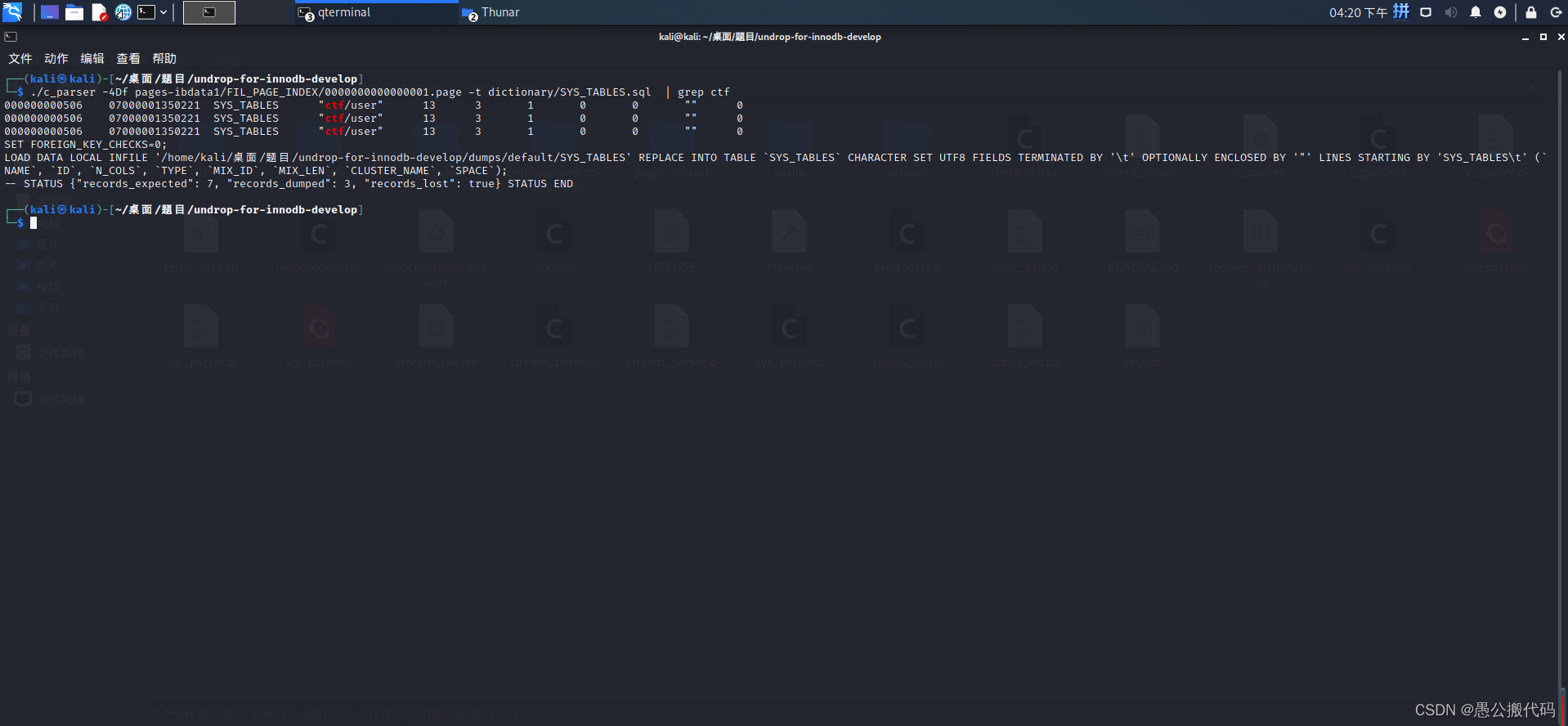
该命令使用c_parser工具解析数据库表索引信息并过滤出我们想要恢复的有关ctf的文件
我们看到 user这个表的索引值为 13,通过这个索引值,再到另外一张表去查询该user表所有的索引信息
该表的结构在"dictionary/SYS_INDEXES.sql"文件中可以看到,而此表对应的数据页文件是第三个数据页0000000000000003.page
./c_parser -4Df pages-ibdata1/FIL_PAGE_INDEX/0000000000000003.page -t dictionary/SYS_INDEXES.sql | grep 13

这里找到一条user 的索引信息,其在mysql 存储中的索引值为 15,此索引值编号对应的数据页文件中,即存储了该索引的全部数据
此处我们选择的是主键索引对应的数据页文件进行解析(另外一个索引键应该也可以,只不过方法可能需要有所区别),终于顺利解析见到了激动人心的数据:
./c_parser -5f pages-ibdata1/FIL_PAGE_INDEX/0000000000000015.page -t 01/structure.sql | more
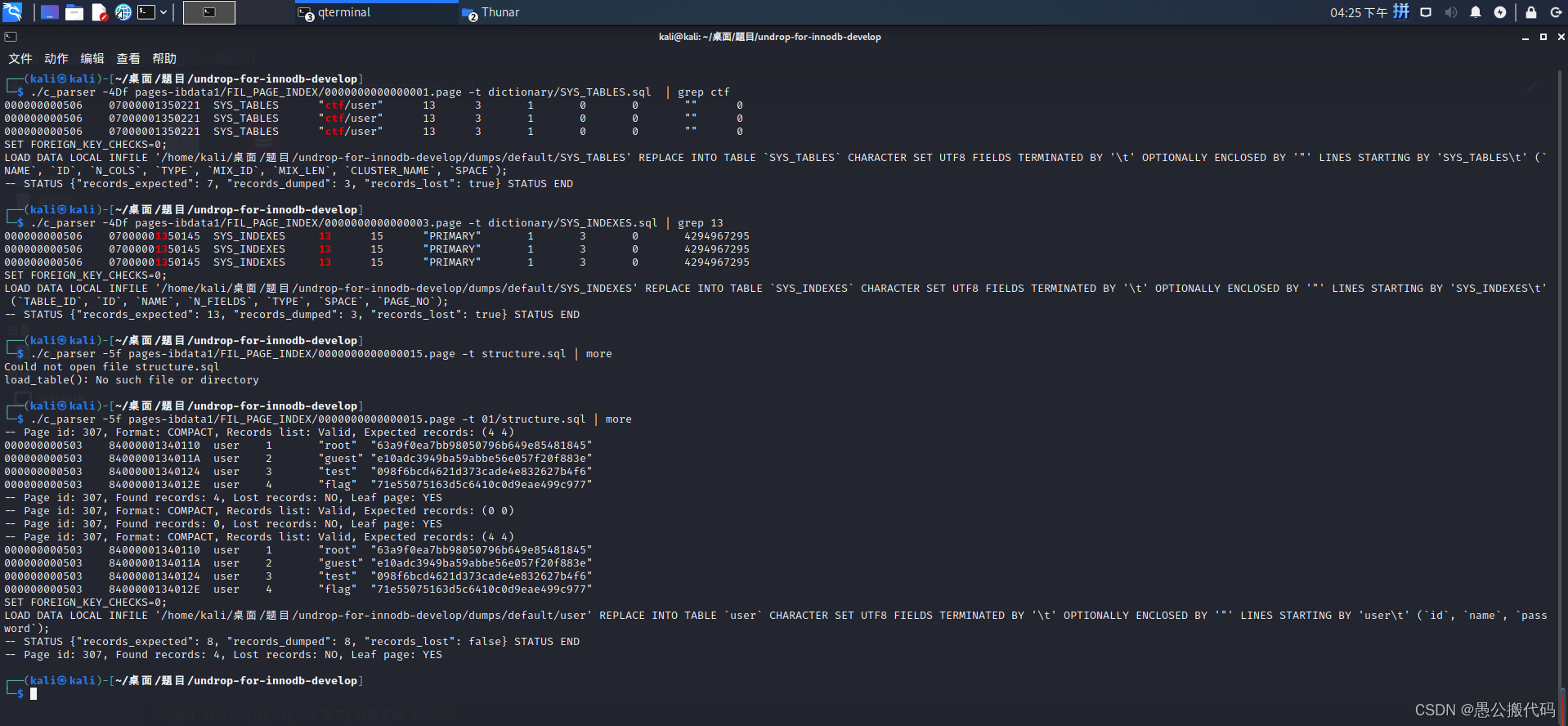
发现flag:71e55075163d5c6410c0d9eae499c977
总结
- mysql
- strings
- Undrop for InnoDB

- 点赞
- 收藏
- 关注作者
评论(0)