PG高可用之主从流复制+keepalived 的高可用

简介
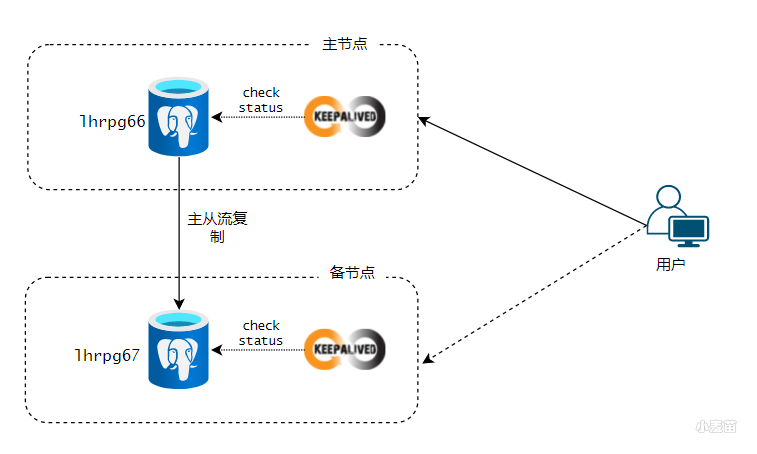
通过keepalived 来实现 PostgreSQL 数据库的主从自动切换,以达到高可用。当主节点宕机时,从节点可自动切换为主节点,继续对外提供服务。
在这一方案中Keepalived程序主要用来探测PostgreSQL主库是否存活,如果Keepalived主节点或主库故障,Keepalived备节点将接管VIP 并日激活流复制备库.从而实现高可用。
环境架构
| IP地址 | 操作系统 | 主机名 | 角色 | 端口 | 说明 |
|---|---|---|---|---|---|
| 172.72.6.6 | CentOS 7.6 | lhrpg66 | 主库 | 5433 | 安装postgesql 13.3 + keepalived v1.3.5 |
| 172.72.6.7 | CentOS 7.6 | lhrpg67 | 从库 | 5433 | 安装postgesql 13.3 + keepalived v1.3.5 |
| 172.72.6.8 | VIP | 在pg66和pg67之间进行漂移 |
配置主从流复制
主机环境准备
-- 创建PG高可用环境专用网络
docker network create --subnet=172.72.6.0/24 pg-network
-- 申请主机
docker rm -f lhrpg66
docker run -d --name lhrpg66 -h lhrpg66 \
-p 64306:5433 --net=pg-network --ip 172.72.6.6 \
-v /sys/fs/cgroup:/sys/fs/cgroup \
--privileged=true lhrbest/lhrpgall:2.0 \
/usr/sbin/init
docker rm -f lhrpg67
docker run -d --name lhrpg67 -h lhrpg67 \
-p 64307:5433 --net=pg-network --ip 172.72.6.7 \
-v /sys/fs/cgroup:/sys/fs/cgroup \
--privileged=true lhrbest/lhrpgall:2.0 \
/usr/sbin/init
[root@docker35 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a320c1882201 lhrbest/lhrpgall:2.0 "/usr/sbin/init" 23 seconds ago Up 21 seconds 0.0.0.0:64307->5433/tcp, :::64307->5433/tcp lhrpg67
e9c67922b0e8 lhrbest/lhrpgall:2.0 "/usr/sbin/init" 26 seconds ago Up 24 seconds 0.0.0.0:64306->5433/tcp, :::64306->5433/tcp lhrpg66
注意:该容器已安装PostgreSQL 13.3,故只需要配置主从即可,安装用户为pg13。
需要关闭其它版本的pg:
systemctl stop pg11
systemctl stop pg12
systemctl stop pg94
systemctl stop pg96
systemctl stop postgresql-13.servicesystemctl disable pg11
systemctl disable pg12
systemctl disable pg94
systemctl disable pg96
systemctl disable postgresql-13.service
主库放开防火墙
cat << EOF > /pg13/pgdata/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD
local all all trust
host all all 127.0.0.1/32 trust
host all all 0.0.0.0/0 md5
host replication all 0.0.0.0/0 md5
EOF
👉 注意添加replication
主库创建复制用户
su - pg13
psql
create user replhr password 'lhr' replication;
👉 创建用户需要加上replication选项。
在从库对主库进行备份
mkdir /bk
chown pg13.postgres /bk
su - pg13
pg_basebackup -h 172.72.6.6 -p 5433 -U replhr -l bk20220210 -F p -P -R -D /bk
执行完成后,会产生文件standby.signal,如下:
[pg13@lhrpg67 ~]$ pg_basebackup -h 172.72.6.6 -p 5433 -U replhr -l bk20220210 -F p -P -R -D /bk
Password:
WARNING: skipping special file "./.s.PGSQL.5433"
WARNING: skipping special file "./.s.PGSQL.5433"
23411/23411 kB (100%), 1/1 tablespace
[pg13@lhrpg67 ~]$ ll /bk
total 260
-rw------- 1 pg13 postgres 209 Feb 10 16:27 backup_label
-rw------- 1 pg13 postgres 135710 Feb 10 16:27 backup_manifest
drwx------ 5 pg13 postgres 4096 Feb 10 16:27 base
-rw------- 1 pg13 postgres 33 Feb 10 16:27 current_logfiles
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 global
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 pg_commit_ts
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 pg_dynshmem
-rw------- 1 pg13 postgres 243 Feb 10 16:27 pg_hba.conf
-rw------- 1 pg13 postgres 1636 Feb 10 16:27 pg_ident.conf
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 pg_log
drwx------ 4 pg13 postgres 4096 Feb 10 16:27 pg_logical
drwx------ 4 pg13 postgres 4096 Feb 10 16:27 pg_multixact
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 pg_notify
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 pg_replslot
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 pg_serial
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 pg_snapshots
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 pg_stat
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 pg_stat_tmp
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 pg_subtrans
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 pg_tblspc
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 pg_twophase
-rw------- 1 pg13 postgres 3 Feb 10 16:27 PG_VERSION
drwx------ 3 pg13 postgres 4096 Feb 10 16:27 pg_wal
drwx------ 2 pg13 postgres 4096 Feb 10 16:27 pg_xact
-rw------- 1 pg13 postgres 314 Feb 10 16:27 postgresql.auto.conf
-rw------- 1 pg13 postgres 28184 Feb 10 16:27 postgresql.conf
-rw------- 1 pg13 postgres 0 Feb 10 16:27 standby.signal
👉 在PG12之前,-R备份结束之后会自动生成recovery.conf文件,用来做流复制判断主从同步的信息。但是从PG12开始,这个文件已经不需要了。只需要在参数文件postgresql.conf中配置primary_conninfo参数即可。
还原从库
-- 关闭从库,删除从库的数据文件,并且将备份文件覆盖从库的数据文件
pg_ctl stop
cp -r /bk/* /pg13/pgdata/
修改从库primary_conninfo参数
cat >> /pg13/pgdata/postgresql.conf <<"EOF"
primary_conninfo = 'host=172.72.6.6 port=5433 user=replhr password=lhr'
EOF
启动从库
pg_ctl start
主库进程:
[root@lhrpg66 /]# ps -ef|grep pg13
pg13 1053 0 0 16:16 ? 00:00:00 /pg13/pg13/bin/postgres -D /pg13/pgdata -p 5433
pg13 1054 1053 0 16:16 ? 00:00:00 postgres: logger
pg13 1056 1053 0 16:16 ? 00:00:00 postgres: checkpointer
pg13 1057 1053 0 16:16 ? 00:00:00 postgres: background writer
pg13 1058 1053 0 16:16 ? 00:00:00 postgres: walwriter
pg13 1059 1053 0 16:16 ? 00:00:00 postgres: autovacuum launcher
pg13 1060 1053 0 16:16 ? 00:00:00 postgres: stats collector
pg13 1061 1053 0 16:16 ? 00:00:00 postgres: logical replication launcher
pg13 1827 1053 0 16:29 ? 00:00:00 postgres: walsender replhr 172.72.6.7(51662) streaming 0/3000148
root 2024 551 0 16:32 pts/0 00:00:00 grep --color=auto pg13
从库进程:
[root@lhrpg67 /]# ps -ef|grep pg13
pg13 1900 0 0 16:29 ? 00:00:00 /pg13/pg13/bin/postgres
pg13 1901 1900 0 16:29 ? 00:00:00 postgres: logger
pg13 1902 1900 0 16:29 ? 00:00:00 postgres: startup recovering 000000010000000000000003
pg13 1903 1900 0 16:29 ? 00:00:00 postgres: checkpointer
pg13 1904 1900 0 16:29 ? 00:00:00 postgres: background writer
pg13 1905 1900 0 16:29 ? 00:00:00 postgres: stats collector
pg13 1906 1900 0 16:29 ? 00:00:00 postgres: walreceiver streaming 0/3000148
root 2186 540 0 16:32 pts/0 00:00:00 grep --color=auto pg13
查询复制状态
-- 主库查看wal日志发送状态
select * from pg_stat_replication;
-- 从库查看wal日志接收状态
select * from pg_stat_wal_receiver;
-- 也可以通过该名称查看
pg_controldata | grep state
-- 也可以查看这个,主库是f代表false ;备库是t,代表true
select pg_is_in_recovery();
主库查询复制状态:
C:\Users\lhrxxt>psql -U postgres -h 192.168.66.35 -p 64306
Password for user postgres:
psql (14.0, server 13.3)
Type "help" for help.
postgres=# select * from pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-----+----------+---------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+-----------+-----------+-----------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
623 | 16430 | replhr | walreceiver | 172.72.6.7 | | 51676 | 2022-02-10 16:37:28.351635+08 | | streaming | 0/3000060 | 0/3000060 | 0/3000060 | 0/3000060 | | | | 0 | async | 2022-02-10 16:38:58.583056+08
(1 row)
postgres=# \x
Expanded display is on.
postgres=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 623
usesysid | 16430
usename | replhr
application_name | walreceiver
client_addr | 172.72.6.7
client_hostname |
client_port | 51676
backend_start | 2022-02-10 16:37:28.351635+08
backend_xmin |
state | streaming
sent_lsn | 0/3000060
write_lsn | 0/3000060
flush_lsn | 0/3000060
replay_lsn | 0/3000060
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2022-02-10 16:39:18.625797+08
pg_stat_replication是一个视图,主要用于监控PG流复制情况。在这个系统视图中每个记录只代表一个slave。因此,可以看到谁处于连接状态,在做什么任务。pg_stat_replication也是检查slave是否处于连接状态的一个好方法。
每个字段代码的含义:
• pid: 这代表负责流连接的wal_sender进程的进程ID。例如“postgres: walsender replhr 172.72.6.3(40056) streaming 0/7000148”。
• usesysid: 每个内部用户都有一个独一无二的编号。该系统的工作原理很像UNIX。 usesysid 是 (PostgreSQL) 用户连接到系统的唯一标识符。
• usename: (不是用户名, 注意少了 r),它存储与用户相关的 usesysid 的名字。这是客户端放入到连接字符串中的东西。
• application_name:这是同步复制的通常设置。它可以通过连接字符串传递到master。
• client_addr: 它会告诉您流连接从何而来。它拥有客户端的IP地址。
• client_hostname: 除了客户端的IP,您还可以这样做,通过它的主机名来标识客户端。您可以通过master上的postgresql.conf中的log_hostname启用DNS反向查找。
• client_port: 这是客户端用来和WALsender进行通信使用的TPC端口号。 如果不本地UNIX套接字被使用了将显示-1。
• backend_start: 它告诉我们slave什么时间创建了流连接。
• state: 此列告诉我们数据的连接状态。如果事情按计划进行,它应该包含流信息。
• sent_lsn:这代表发送到连接的最后的事务日志的位置。已经通过网络发送了多少WAL?
• write_lsn: 这是写到standby系统磁盘上最后的事务日志位置。已向操作系统发送了多少WAL?( 尚未 flushing)
• flush_lsn: 这是被刷新到standby系统的最后位置。(这里注意写和刷新之间的区别。写并不意味着刷新 。)已经有多少WAL已 flush 到磁盘?
• replay_lsn: 这是slave上重放的最后的事务日志位置。已重放了多少WAL,因此对查询可见?
• sync_priority: 这个字段是唯一和同步复制相关的。每次同步复制将会选择一个优先权 —sync_priority—会告诉您选择了那个优先权。
• sync_state: 最后您会看到slave在哪个状态。这个状态可以是async, sync, or potential。当有一个带有较高优先权的同步slave时,PostgreSQL会把slave 标记为 potential。
人们经常说 pg_stat_replication 视图是primary 端的,这是不对的。该视图的作用是揭示有关wal sender 进程的信息。换句话说:如果你正在运行级联复制,该视图意味着在 secondary 复制到其他slaves 的时候, secondary 端的 pg_stat_replication 上的也会显示entries ( 条目 )
从库查询wal日志接收状态:
C:\Users\lhrxxt>psql -U postgres -h 192.168.66.35 -p 64307
Password for user postgres:
psql (14.0, server 13.3)
Type "help" for help.
postgres=# select * from pg_stat_wal_receiver;
pid | status | receive_start_lsn | receive_start_tli | written_lsn | flushed_lsn | received_tli | last_msg_send_time | last_msg_receipt_time | latest_end_lsn | latest_end_time | slot_name | sender_host | sender_port | conninfo
-----+-----------+-------------------+-------------------+-------------+-------------+--------------+-------------------------------+-------------------------------+----------------+-------------------------------+-----------+-------------+-------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
614 | streaming | 0/3000000 | 1 | 0/3000060 | 0/3000060 | 1 | 2022-02-10 16:39:28.647917+08 | 2022-02-10 16:39:28.648022+08 | 0/3000060 | 2022-02-10 16:37:28.355389+08 | | 172.72.6.6 | 5433 | user=replhr password=******** channel_binding=disable dbname=replication host=172.72.6.6 port=5433 fallback_application_name=walreceiver sslmode=disable sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=disable krbsrvname=postgres target_session_attrs=any
(1 row)
postgres=# \x
Expanded display is on.
postgres=# select * from pg_stat_wal_receiver;
-[ RECORD 1 ]---------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 614
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000060
flushed_lsn | 0/3000060
received_tli | 1
last_msg_send_time | 2022-02-10 16:39:28.647917+08
last_msg_receipt_time | 2022-02-10 16:39:28.648022+08
latest_end_lsn | 0/3000060
latest_end_time | 2022-02-10 16:37:28.355389+08
slot_name |
sender_host | 172.72.6.6
sender_port | 5433
conninfo | user=replhr password=******** channel_binding=disable dbname=replication host=172.72.6.6 port=5433 fallback_application_name=walreceiver sslmode=disable sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=disable krbsrvname=postgres target_session_attrs=any
postgres=#
PostgreSQL数据库配置
在主库创建表sr_delay,后续Keepalived每探测一次会刷新这张表的last_alive字段为当前探测时间,这张表用来判断主备延迟,数据库故障切换时会用到这张表。
直接在主库执行,备库会自动同步:
create table sr_delay(id int4, last_alive timestamp(0) without time zone);
INSERT INTO sr_delay VALUES(1,now()) ;
postgres=> select * from sr_delay;
id | last_alive
----+---------------------
1 | 2022-02-11 09:02:52
(1 row)
配置keepalived
安装
yum install -y keepalived
配置keepalived
以下所有脚本在主备库都创建:
keepalived.conf
cat > /etc/keepalived/keepalived.conf <<"EOF"
! Configuration File for keepalived
global_defs {
router_id lhrpg
}
vrrp_script check_pg_alived {
script "/etc/keepalived/check_pg.sh"
interval 10
fall 3
}
vrrp_instance VI_1 {
state BACKUP
nopreempt
interface eth0
virtual_router_id 10
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass lhr
}
track_script {
check_pg_alived
}
virtual_ipaddress {
172.72.6.8/32 dev eth0 label eth0:1
}
smtp_alert
notify_master /etc/keepalived/failover.sh
# notify_fault /etc/keepalived/fault.sh
}
EOF
以上是Keepalived主节点的配置,Keepalived备节点的priority参数改成90,其余参数配置一样。
check_pg.sh
对主从PG 状态进行监控,监控脚本 check_pg.sh:
cat > /etc/keepalived/check_pg.sh <<"EOF"
#!/bin/bash
export PGDATABASE=postgres
export PGPORT=5433
export PGUSER=postgres
export PGHOME=/pg13/pg13
export PATH=$PGHOME/bin:$PATH:.
PGIP=127.0.0.1
LOGFILE=/etc/keepalived/pg_keepalived.log
#pg_port_status=`lsof -i :$PGPORT | grep LISTEN | wc -l`
#pg_port_status=`ps -ef | grep LISTEN | wc -l`
SQL1='SELECT pg_is_in_recovery from pg_is_in_recovery();'
SQL2='update sr_delay set last_alive = now() where id =1;'
SQL3='SELECT 1;'
#此脚本不检查备库存活状态,如果是备库则退出
db_role=`echo $SQL1 | $PGHOME/bin/psql -h $PGIP -p $PGPORT -d $PGDATABASE -U $PGUSER -At -w`
#if [ $pg_port_status -lt 1 ];then
# echo -e `date +"%F %T"` 'Error: The postgreSQL is not running,please check the postgreSQL server status!' >> $LOGFILE
# exit 1
#fi
if [ $db_role == 't' ]; then
echo -e `date +"%F %T"` 'Attention: the current database is standby DB!' >> $LOGFILE
exit 0
fi
# 判断主库是否可用,主库更新状态
echo $SQL3 | $PGHOME/bin/psql -h $PGIP -p $PGPORT -d $PGDATABASE -U $PGUSER -At -w
if [ $? -eq 0 ]; then
echo $SQL2 | $PGHOME/bin/psql -h $PGIP -p $PGPORT -d $PGDATABASE -U $PGUSER -At -w
echo -e `date +"%F %T"` 'Success: update the master sr_delay successed!' >> $LOGFILE
exit 0
else
echo -e `date +"%F %T"` 'Error: Is the server is running?' >> $LOGFILE
exit 1
fi
EOF
此脚本每隔10秒执行一次,执行频率由keepalived.conf配置文件中interval参数设置,脚本主要作用为:
① 检测主库是否存活。
② 更新sr_delay表last_alive字段为当前探测时间。
③ 若主库不可用,则应该关闭主库的keepalived服务。
failover.sh
主库挂掉后,keepalived调用执行切换脚本 failover.sh进行主备切换,Keepalived备节点激活成主节点后触发notify_master参数定义的/etc/keepalived/scripts/failover.sh脚本。
cat > /etc/keepalived/failover.sh <<"EOF"
#!/bin/bash
export PGPORT=5433
export PGUSER=postgres
export PG_OS_USER=pg13
export PGDATA=/pg13/pgdata
export PGDBNAME=postgres
export PGHOME=/pg13/pg13
export PATH=$PGHOME/bin:$PATH:.
PGIP=127.0.0.1
LOGFILE=/etc/keepalived/pg_keepalived.log
# 主备数据库同步时延,单位为秒,这里设置延迟5分钟
sr_allowed_delay_time=300
SQL1='select pg_is_in_recovery from pg_is_in_recovery();'
SQL2="select last_alive as delay_time from sr_delay where now()- last_alive < interval '$sr_allowed_delay_time';"
db_role=`echo $SQL1 | $PGHOME/bin/psql -h $PGIP -p $PGPORT -U $PGUSER -d $PGDBNAME -At -w`
db_sr_delaytime=`echo $SQL2 | $PGHOME/bin/psql -h $PGIP -p $PGPORT -d $PGDBNAME -U $PGUSER -At -w`
SWITCH_COMMAND='pg_ctl promote -D $PGDATA'
# 如果为备库,且延迟在指定时间范围内则切换为主库
if [ $db_role == f ]; then
echo -e `date +"%F %T"` 'Attention: The current postgreSQL DB is master database,cannot switched!' >> $LOGFILE
exit 0
elif [[ $db_role == t ]] && [[ $db_sr_delaytime ]]; then
echo -e `date +"%F %T"` 'Attention: The current database is statndby, ready to switch master database!' >> $LOGFILE
su - $PG_OS_USER -c "$SWITCH_COMMAND"
db_role=`echo $SQL1 | $PGHOME/bin/psql -h $PGIP -p $PGPORT -U $PGUSER -d $PGDBNAME -At -w`
if [ $db_role == f ]; then
echo -e `date +"%F %T"` 'success: The current standby database successed to switched the primary PG database !' >> $LOGFILE
exit 0
else
echo -e `date +"%F %T"` 'Error: the standby database failed to switch the primary PG database ! Pelease checked it!' >> $LOGFILE
exit 1
fi
fi
EOF
当异步流复制主库故障时,流复制的备库延迟时间在指定范围内才进行主备切换,如果备库延迟时间超出指定范围则不进行主备切换。
赋权
chmod +x /etc/keepalived/*.sh
启动keepalived
systemctl start keepalived
systemctl enable keepalived
systemctl status keepalived
# keepalived启动报错:IPVS: Can't initialize ipvs: Protocol not available
lsmod | grep ip_vs
modprobe ip_vs
modprobe ip_vs_wrr
lsmod | grep ip_vs
# 如果是容器,那么宿主机也需要加载ip_vs模块。
-- 使用VIP连接
psql -h 172.72.6.8 -U postgres -p 5433 -c 'SELECT inet_server_addr(),pg_is_in_recovery()'
查看状态:
-- 启动之后可以看到VIP 172.72.6.8已经在主节点了
[root@lhrpg66 log]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.72.6.6 netmask 255.255.255.0 broadcast 172.72.6.255
ether 02:42:ac:48:06:06 txqueuelen 0 (Ethernet)
RX packets 20149 bytes 25983425 (24.7 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 21118 bytes 26526579 (25.2 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.72.6.8 netmask 255.255.255.255 broadcast 0.0.0.0
ether 02:42:ac:48:06:06 txqueuelen 0 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 16184 bytes 5223332 (4.9 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 16184 bytes 5223332 (4.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
-- 主节点日志
[root@lhrpg66 ~]# tailf /etc/keepalived/log/pg_keepalived.log
2022-02-11 14:49:28 Success: update the master sr_delay successed!
2022-02-11 14:49:38 Success: update the master sr_delay successed!
2022-02-11 14:49:48 Success: update the master sr_delay successed!
2022-02-11 14:49:58 Success: update the master sr_delay successed!
2022-02-11 14:50:08 Success: update the master sr_delay successed!
2022-02-11 14:50:18 Success: update the master sr_delay successed!
2022-02-11 14:50:28 Success: update the master sr_delay successed!
2022-02-11 14:50:38 Success: update the master sr_delay successed!
-- 备节点日志
[root@lhrpg67 ~]# tailf /etc/keepalived/log/pg_keepalived.log
2022-02-11 14:49:44 Attention: the current database is standby DB!
2022-02-11 14:49:54 Attention: the current database is standby DB!
2022-02-11 14:50:04 Attention: the current database is standby DB!
2022-02-11 14:50:14 Attention: the current database is standby DB!
2022-02-11 14:50:24 Attention: the current database is standby DB!
2022-02-11 14:50:34 Attention: the current database is standby DB!
2022-02-11 14:50:44 Attention: the current database is standby DB!
2022-02-11 14:50:54 Attention: the current database is standby DB!
-- 主从库的表sr_delay时间更新
postgres=> select * from sr_delay;
id | last_alive
----+---------------------
1 | 2022-02-11 10:37:01
(1 row)
验证高可用
-- 判断是否同步
select * from sr_delay;
-- 判断主备库
select * from pg_is_in_recovery();
停止主库的数据库服务
pg_ctl stop
查看日志:
-- 主库
2022-02-11 15:26:08 Success: update the master sr_delay successed!
2022-02-11 15:26:18 Success: update the master sr_delay successed!
2022-02-11 15:26:28 Success: update the master sr_delay successed!
2022-02-11 15:26:38 Error: Is the server is running?
2022-02-11 15:26:48 Error: Is the server is running?
2022-02-11 15:26:58 Error: Is the server is running?
2022-02-11 15:27:08 Error: Is the server is running?
-- 备库
2022-02-11 15:26:34 Attention: the current database is standby DB!
2022-02-11 15:26:44 Attention: the current database is standby DB!
2022-02-11 15:26:54 Attention: the current database is standby DB!
2022-02-11 15:27:00 Attention: The current database is statndby, ready to switch master database!
2022-02-11 15:27:00 success: The current standby database successed to switched the primary PG database !
2022-02-11 15:27:04 Success: update the master sr_delay successed!
2022-02-11 15:27:14 Success: update the master sr_delay successed!
2022-02-11 15:27:24 Success: update the master sr_delay successed!
在主库关闭后,检测3次,即30秒之后,发生切换,此时备库切换为主库,VIP也在此时漂移到备库:
[root@lhrpg67 /]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.72.6.7 netmask 255.255.255.0 broadcast 172.72.6.255
ether 02:42:ac:48:06:07 txqueuelen 0 (Ethernet)
RX packets 3005 bytes 33264390 (31.7 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 2393 bytes 286938 (280.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.72.6.8 netmask 255.255.255.255 broadcast 0.0.0.0
ether 02:42:ac:48:06:07 txqueuelen 0 (Ethernet)
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 5797 bytes 1549768 (1.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5797 bytes 1549768 (1.4 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
此时,可以修复源主库:
touch /pg13/pgdata/standby.signal
pg_ctl start
启动后,可以看到源主库作为新备库存在,新主备架构同步正常。
关闭主库的OS
docker stop lhrpg67
过程和“停止主库的数据库服务”基本一样,主库又回到了lhrpg66。
关闭主库的keepalived
若关闭主库的keepalived进程,那么,备库会立马进行切换为主库:
2022-02-11 15:44:11 Attention: the current database is standby DB!
2022-02-11 15:44:20 Attention: The current database is statndby, ready to switch master database!
2022-02-11 15:44:21 Attention: the current database is standby DB!
2022-02-11 15:44:21 success: The current standby database successed to switched the primary PG database !
2022-02-11 15:44:31 Success: update the master sr_delay successed!
2022-02-11 15:44:41 Success: update the master sr_delay successed!
关闭备库的数据库或keepalived服务或OS
经过测试,无论是关闭备库的pg数据库,还是关闭备库的keepalived,亦或关闭备库的OS,然后重启相关服务,对这个架构没有影响。
总结
1、挂掉的主库若重启作为主库的话,在启动之前需要配置standby.signal文件,若启动之前没有配置standby.signal文件,而是以主库的角色启动,那么需要重新关闭,然后按照如下步骤修复,否则启动过程会报错“requested timeline 2 is not a child of this server’s history”:
wal_log_hints = 'on'
pg_rewind --target-pgdata=/pg13/pgdata --source-server='host=172.72.6.6 port=5433 user=postgres dbname=postgres password=lhr'
touch standby.signal
修改primary_conninfo
2、总体感受,keepalived可维护性不强,并不建议生产环境使用。
3、keepalived只是解决了高可用中的单点故障问题(故障可以自动切换),并不提供负载均衡、读写分离等特性。

- 点赞
- 收藏
- 关注作者
评论(0)