【C++】面向对象之封装篇

学习总结
文章目录
一、封装篇(上)
1.1 类和对象、类对象定义
3.1.1 引例----狗
class Dog{//class为关键字
char name[20];
int Age;//属性
int type;//数据成员
void spead();//方法
void run();//成员函数
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.1.2 引例----电视机
class TV{
public:
char name[20];//电视名字
int type;//电视类型
void changeVol();//调节音量
void power();//开关电源
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.1.3 对象的实例化
(1)从栈实例化
(使用完后,系统会自动将其所占内存释放)
int main(){
TV tv;//定义一个对象
TV tv[10];//定义一个对象数组
return 0;
}
- 1
- 2
- 3
- 4
- 5
(2)从堆实例化
(使用完后,要我们自己释放内存)
int main(){
TV *p=new TV();//定义一个对象
TV *q=new TV[10];//定义一个对象数组
//to do
delete p;
delete []q;//删除指向对象数组的指针
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.1.4 对象成员的访问
通过不同实例化对象的方法,生成的对象访问其数据成员和成员函数的方式也不同。
(1)栈实例化对象访问其成员
(2)堆实例化单一对象访问其成员
(3)堆实例化对象数组访问其成员

3.1.5 代码实践
#include<iostream>
#include<stdlib.h>
using namespace std;
class Coordinate{
public:
int x;
int y;
void printX(){
cout<<x<<endl;
}
void printY(){
cout<<y<<endl;
}
};
int main(){
Coordinate coor;//从栈中实例化一个坐标对象
coor.x=10;
coor.y=20;
coor.printX();
coor.printY();
Coordinate *p=new Coordinate();//从堆中实例化一个坐标对象
//这里需要判断申请的内存是否成功
if(NULL==p){
cout<<"申请内存失败"<<endl;
return 0;
}
p->x=100;
p->y=200;
p->printX();
p->printY();
//对象使用完后,需要释放内存
delete p;
p=NULL;
system("pause");
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
输出结果为:

1.2 初始字符串类型
(1)string类型
字符串,如果只用char数组,经常使用strlen、strcat、strcmp函数会比较麻烦,而C++就因此引入string类型。
string hobby="football";
cout<<hobby<<endl;
- 1
- 2
(2)初始化string对象的方式
string s1;//s1为空字符串
string s2("ABC");//用字符串字面值初始化s2
string s3(s2);//将s3初始化为s2的一个副本
string s4(n,'c');//将s4初始化为字符‘c’的n个副本
- 1
- 2
- 3
- 4
(3)string的常用操作
s.empty() //若s为空串,则返回true
s.size()//返回s中字符的个数
s[n]//返回s中位置为n的字符,位置从0开始
s1+s2//将两个串连接成新串,返回新生成的串
s1=s2//将s1的内容替换为s2的副本
- 1
- 2
- 3
- 4
- 5
(4)代码实践
题目描述:
1 提示用户输入姓名
2 接收用户的输入
3 然后向用户问好,hello xxxx
4 告诉用户名字的长度
5 告诉用户名字的首字母是什么
6 如果用户直接输入回车,那么告诉用户输入的为空
7 如果用户输入的是imooc,那么告诉用户的角色是一个管理员
#include<iostream>
#include<stdlib.h>
#include<string>
using namespace std;
int main()
{
string name;
cout<<"please input your name: ";
getline(cin, name);
if(name.empty())
{
cout<<"input is null..."<<endl;
system("pause");
return 0;
}
if(name == "imooc")
{
cout<<"You are a administartor"<<endl;
}
cout<<"hello " + name <<endl;
cout<<"Your name's length is:"<<name.size() <<endl;
cout<<"Your name's first letter is: "<< name[0] <<endl;
system("pause");
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
1.3 属性封装的艺术
(1)数据的封装
如果按照C语言的面向过程的习惯,我们会这样写:
class Student{
public:
string name;
int age;
};
int main(){
Student stu;
stu.name='Jim';
stu.age=10;
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
而面向对象:以对象为中心,要以谁做什么来表达程序的逻辑,
代码层上:将所有的数据操作转换为成员函数的调用,对象在程序中所有的行为都通过自己的函数完成。
通过函数来封装数据成员:
class Student{
private:
void setAge(int _age){
age=_age;
}
int getAge(){
return age;
}
private:
string name;
int age;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
即上面的2个成员函数:一个设置年龄的值,一个读取年龄的值。
(2)封装的好处
(1)防止非法输入
如上面的年龄防止输入1000这种不合理的数据。
class Student{
private:
void setAge(int _age){
if(_age>0 && _age<100){
age=_age;
}else{
.....
}
}
int getAge(){
return age;
}
private:
string name;
int age;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
(2)可以控制外界对数据的访问属性
如Car类,我们不希望外界通过某个函数改变m_iWheelCount变量的值,即只希望设置为只读属性,那就设置为private。
class Car{
public:
int getWheelCount(){
return m_iWheelCount;
}
private:
int m_iWheelCount;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
(3)代码实践
定义一个Student类,含有如下信息:
1 姓名:name
2 性别:gender
3 学分(只读):score
4 学习:study(用于获得学分)
#include<iostream>
#include<stdlib.h>
#include<string>
using namespace std;
/* **********数据的封装
定义一个Student类,含有如下信息:
姓名:name
性别:gender
学分(只读):score
学习:study(用于获得学分)
/* ************************************/
class Student{
public:
void setName(string _name){
m_strName=_name;
}
string getName(){
return m_strName;
}
void setGender(string _gender){
m_strGender = _gender;
}
string getGender(){
return m_strGender;
}
int getScore(){
return m_iScore;
}
void initScore(){
m_iScore=0;
}
void study(int _score){
m_iScore += _score;
}
private:
string m_strName;
string m_strGender;
int m_iScore;
};
int main(){
Student stu;
stu.initScore();//如果这里不进行初始化,m_iScore的值就不可控
stu.setName("Zhangsan");
stu.setGender("女");
stu.study(5);//学习一门学分为5分的课程
stu.study(3);//学习一门学费为3分的课程
cout<<stu.getName()<<" "<<stu.getGender()<<" "<<stu.getScore()<<endl;
system("pause");
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51

1.4 类内定义与类外定义
(1)类内定义
将成员函数的函数体写在类的内部。
类内定义与内联函数的关系
类内定义的成员函数,编译器会将其优先编译为内联函数,
但对于复杂的成员函数无法编译成内联函数的,就编译成普通的函数。
普通函数和内联函数的区别:
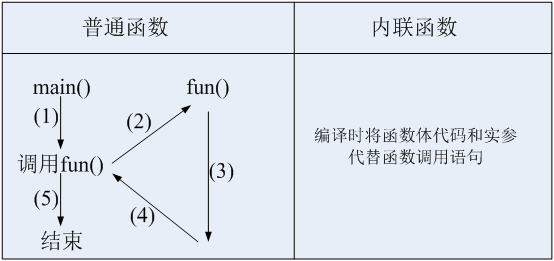
上面的步骤即体现了内联函数是省掉了(2)和(4)步骤,可以为调用节省很多时间(尤其对于循环调用时省时)。
(2)类外定义
即将成员函数的函数体写在类的外面。
分为:同文件类外定义、分文件类外定义
1.同文件类外定义
注意开头写上类名和::

2.分文件类外定义(重点)
几乎所有的C++项目都会将类的定义分文件完成。
头文件,类名建议和文件名写成一样。
class Car{
public:
void run();
void stop();
void changeSpeed();
};
- 1
- 2
- 3
- 4
- 5
- 6
在另一个文件的开头记得将头文件Car.h写上:
#include "Car.h"
void Car::run(){}
void Car::stop(){}
void Car::changeSpeed(){}
- 1
- 2
- 3
- 4
1.5 对象的构造
学习前的思考:
(1)实例化的对象是如何在内存中存储的?
(2)类中的代码又是如何存储的?
(3)数据和代码之间的关系是咋样的?
(1)对象结构
内存中按照用途被划分的5个区域
int x=0;int *p=NULL;//存储在栈
int *p=new int[20];//存储在堆区,注意这里的数组名为p,而不是int(关键字int)
存储全局变量和静态变量//全局区
string str="hello";//常量区
存储逻辑代码的二进制//代码区
- 1
- 2
- 3
- 4
- 5
栈区:内存由系统进行控制(程序员不需要关心其分配和回收)
堆区:new分配一段内存(会分配在堆区),需要我们自己用delete回收这段内存。
全局区:全局变量、静态变量
常量区:字符串、常量
代码区:存储编译后的二进制代码
定义一个Car类,在类被实例化前是不会用到堆or栈中的内存的,
class Car{
private:
int wheelCount;
public:
int getWheelCout(){
return wheelCount;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
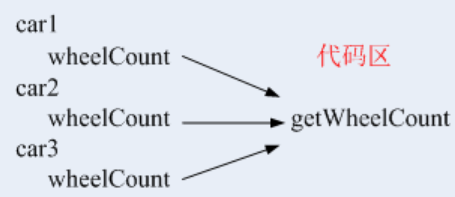
但当它实例化后,如实例化出car1、car2、car3对象,每个对象都存储会在【栈】中(不同对象在栈中位置不同),但是逻辑代码却只编译出一份(放在代码区)。
当需要的时候,这个代码区中的代码供所有的对象使用。
(2)对象初始化
上面的实例化三个对象后,每个对象中的数据都不可控(因为没有对数据初始化)。
栗子:
定义坦克类,只描述位置,实例化一个坦克对象t1后,通过t1调用初始化函数(init)。
class Tank{
private:
int m_iPosX;
int m_iPosY;
Public:
void init(){
m_iPosX=0;
m_iPosY=0;
}
};
int main(){
Tank t1;
t1.init();
Tank t2;
t2.init();
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
对象的初始化:可能有且仅有一次 or 根据条件初始化多次。
(3)构造函数
有时需要有且仅有一次的初始化操作,为了防止0次或者多次调用初始化函数,C++推出构造函数。
构造函数:在对象实例化时被自动调用(仅被调用一次)。
相关规则:
(1)构造函数与类同名;
(2)没有返回值;
(3)可以有多个重载形式;
(4)在实例化对象时,即使有多个构造函数,也仅用到其中的一个构造函数;
(5)当用户没有定义构造函数时,编译器将自动生成一个构造函数。
1)无参构造函数
class Student{
public:
Student(){
m_strName="Keiven";
}
private:
string m_strName;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在Student类中,构造函数没有任何返回值,构造函数内部对数据成员进行赋值操作(初始化)。
2)有参构造函数
class Student{
public:
Student(string name){
m_strName=name;
}
private:
string m_strName;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这种构造函数即在用户实例化一个Student对象时可以传进一个name作初始值。
(4)构造函数代码实践
先定义头文件,注意下面的类里的构造函数参数中age=40是在设置默认参数——如果没有传参年龄,即只传参了名字也会直接调用第二个构造函数,而年龄默认为40(设置默认参数)。
头文件:
#include<iostream>
#include<string>
using namespace std;
class Teacher{
public:
Teacher();//申请无参构造函数
//Teacher(string name,int age);//申请有参构造函数
Teacher(string name,int age=40);
void setName(string name);
string getName();
void setAge(int age);
int getAge();
private:
string m_strName;
int m_iAge;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
主函数如下:
#include"Teacher.h"
#include<stdlib.h>
#include<iostream>
#include<stdio.h>
using namespace std;
/* ************************************************************************/
/* 定义一个Teacher类,具体要求如下:
/* 自定义无参构造函数
/* 自定义有参构造函数
/* 数据成员:
/* 名字
/* 年龄
/* 成员函数:
/* 数据成员的封装函数
/* ************************************************************************/
//自定义无参构造函数
Teacher::Teacher(){
m_strName="Keiven";
m_iAge=20;
cout<<"Teacher()"<<endl;
}
//自定义有参构造函数
Teacher::Teacher(string name,int age){
m_strName=name;
m_iAge=age;
cout<<"Teacher(string name,int age)"<<endl;
}
void Teacher::setName(string _name){
m_strName=_name;
}
string Teacher::getName(){
return m_strName;
}
void Teacher::setAge(int _age){
m_iAge=_age;
}
int Teacher::getAge(){
return m_iAge;
}
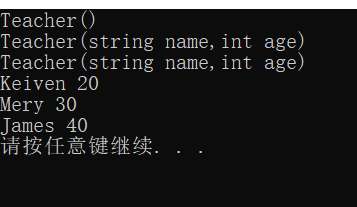
int main(){
Teacher t1;//调用无参构造函数
Teacher t2("Mery",30);//调用有参构造函数
Teacher t3("James");
//检查上面3个构造函数是否有初始化数据成员
cout<<t1.getName()<<" "<<t1.getAge()<<endl;
cout<<t2.getName()<<" "<<t2.getAge()<<endl;
cout<<t3.getName()<<" "<<t3.getAge()<<endl;
system("pause");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
输出结果为:
注意:
构造函数除了可以重载,还可以给参数赋值默认值,
但不能随意的赋值默认值,有时会引起编译时不通过——因为实例化对象时,编译器不知道调用哪一个构造函数。
(5)默认构造函数
默认构造函数:在实例化对象时,不需要传递参数的构造函数。
class Student{
public:
Student(){}
Student(string name="Keiven");
private:
string m_strName;
};
int main(){
Student stu1;
Student *p=NULL;
p=new Student();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
实例化2个对象:一个是stu1(从堆中实例化对象),
另一个是用p指针指向实例化的一个对象所在的栈空间(从堆中实例化一个对象)。
无论是从栈中还是堆中实例化对象,共同特点:调用的构造函数都不用传参——如上面代码有两种情况都不用传参:
Student(){}
Student(string name="Keiven");
- 1
- 2
(6)构造函数初始化列表
在这个例子中,我们定义了一个学生Student的类,在这个类中,我们定义了两个数据成员(一个名字,一个年龄),名字和年龄都通过初始化列表(即红色标记部分)进行了初始化。姓名和年龄都通过初始化列表进行初始化
注意
(1)构造函数后需要冒号隔开,多个数据成员之间则是用逗号隔开
(2)赋值用括号赋值,而非等号
class Student{
public:
Student():m_strName("Keiven"),m_iAge(30){}
private:
string m_strName;
int m_iAge;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1)特点
(1)初始化列表先于构造函数执行
(2)初始化列表只能用于构造函数
(3)初始化列表可同时初始化多个数据成员
2)必要性(牛逼处)
(1)会报错的栗子:
在这个例子中,我们定义了一个圆Circle的类,在这个类中定义了一个pi值,因为pi是不变的,我们用const来修饰,从而pi就变成了一个常量。我们如果用构造函数来初始化这个常量(像上面那样),这样的话编译器就会报错,而且会告诉我们,因为pi是常量,不能再给它进行赋值。也就是说,我们用构造函数对pi进行赋值,就相当于第二次给pi赋值了。那如果我们想给这个pi赋值,并且又不导致语法错误,怎么办呢?唯一的办法就是通过初始化列表来实现(如下)。这个时候,编译器就可以正常工作了。
class Circle{
public:
Circle(){m_dPi=3.14;}
private:
const double m_dPi;
};
- 1
- 2
- 3
- 4
- 5
- 6
原因:const修饰的m_dPi是常量,即编译器会因为不能给他进行赋值而报错(二次赋值),而唯一办法是通过初始化列表解决。
(2)不报错(解决)
class Circle{
public:
Circle(){m_dPi=3.14;}
private:
const double m_dPi;
};
- 1
- 2
- 3
- 4
- 5
- 6
(7)初始化列表代码实践
描述:定义一个Teacher类,自定义有参默认构造函数,适用初始化列表初始化数据;数据成员包含姓名和年龄;成员函数为数据成员的封装函数;拓展:定义可以带最多学生的个数,此为常量。
Teacher.h头文件:
#include<iostream>
#include<string>
using namespace std;
class Teacher{
public:
Teacher(string name="Keiven",int age=20,int m=100);
//申明有参默认构造函数,带有初始值
void setName(string name);
string getName();
void setAge(int age);
int getAge();
int getMax();
private:
string m_strName;
int m_iAge;
const int m_iMax;//常量(只能通过初始化列表进行初始化
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
源文件:
#include"Teacher.h"
#include<iostream>
#include<stdlib.h>
using namespace std;
/* ************************************************************************/
/* 定义一个Teacher类,具体要求如下:
/* 自定义有参默认构造函数
/* 适用初始化列表初始化数据
/* 数据成员:
/* 名字
/* 年龄
/* 成员函数:
/* 数据成员的封装函数
/* 拓展:
/* 定义可以带最多学生的个数,此为常量
/* ************************************************************************/
Teacher::Teacher(string name,int age,int m):m_strName(name),m_iAge(age),m_iMax(m){
//初始化列表形式定义有参构造函数
cout<<"Teacher(string name,int age)"<<endl;
}
int Teacher::getMax(){
return m_iMax;
}
void Teacher::setName(string _name){
m_strName=_name;
}
string Teacher::getName(){
return m_strName;
}
void Teacher::setAge(int _age){
m_iAge=_age;
}
int Teacher::getAge(){
return m_iAge;
}
int main(){
Teacher t1("Mery",30,150);
//看2个构造函数是否完成数据成员的初始化
cout<<t1.getName()<<" "<<t1.getAge()<<" "<<t1.getMax()<<endl;
system("pause");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
(8)拷贝构造函数
实例化三个对象,本以为会打印出3个student,而结果只打印了一个:
class Student{
public:
Student(){//默认构造函数
cout<<"Student"<<endl;
}
private:
string m_strName;
};
int main(){
Student stu1;
Student stu2=stu1;
Student stu3(stu1);
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
因为第2、3个实例化对象调用的不是上面定义的默认构造函数,而是一种特殊的构造函数——拷贝构造函数。
1)定义格式
定义格式:类名(const 类名 & 变量名)
class Student{
public:
Student(){//默认构造函数
m_strName="Keiven";
}
Student(const Student &stu){}//拷贝构造函数
private:
string m_strName;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
首先要加一个const关键字,其次传入的是一个引用,这个引用还是一个与自己的数据类型完全相同(也就是说,也是一个Student的一个对象)的引用。
通过这样的定义方式,我们就定义出了一个拷贝构造函数。
如果我们将相应的代码写在拷贝构造函数的实现的部分,那么我们再采用上面两种实例化对象的方式,就会执行拷贝构造函数里面的相应代码。
在实例化stu2和stu3的时候,我们并没有去定义拷贝构造函数,但是仍然可以将这两个对象实例化出来。
可见,拷贝构造函数与普通的构造函数一样。
(1)如果没有自定义拷贝构造函数,则系统会自动生成一个默认的拷贝构造函数。
(2)当采用直接初始化或复制初始化实例化对象时,系统自动调用拷贝构造函数(如引例)。
(9)构造函数小结
(1)所有的无参数构造函数都是默认构造函数。
(2)系统会自动生成一些函数——分为普通构造函数 and 拷贝构造函数。
如果自定义了普通构造函数,系统就不会再自动生成默认构造函数;
如果自定义了拷贝构造函数,系统就不会再自动生成拷贝函数。
(3)初始化列表,只能连接在普通构造函数或者拷贝构造函数的后面。
PS:显然拷贝构造函数不能重载(参数是确定的,类-型)。
1.6 对象的析构
(1)析构函数
在对象销毁时会被自动调用,归还系统的资源。
(因其没有参数,所以析构函数就不能重载;另外注意析构函数没有返回值)
定义格式:~类名()
class Student{
public:
Student(){
cout<<"Student"<<endl;
}
~Student(){//不允许加任何参数
cout<<"~Student"<<endl;
}
private:
string m_strName;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1)析构函数的必要性
class Student{
public:
Student(){
m_pName=new char[20];
}
private:
char *m_pName;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
以Student学生类,对于数据成员姓名,我们不用string型,而是使用字符数组。
我们改用指针,并且在其构造函数中,让这个指针指向堆中分配(new出来的)的一段内存;
在该对象销毁时,就必须释放掉这段内存,否则会造成内存泄漏。
要释放内存,最好的时机是对象被销毁之前,如果销毁早了则其他要用到这些资源的程序会报错。
so->设计一个对象销毁之前被自动调用的函数就非常有必要(即析构函数)。
2)析构的特点
(1)如果没有自定义析构函数,系统就会自动生成。
(2)析构函数在对象销毁时被自动调用(相对的是:构造函数,即在对象实例化时被自动调用)。
(2)对象的生命历程
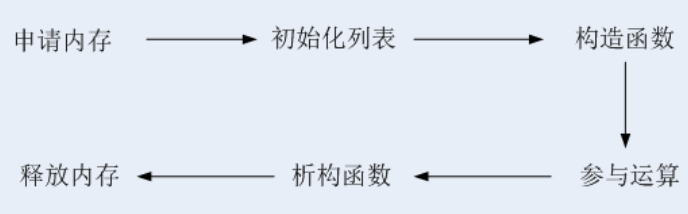
(3)析构函数代码实践
定义一个Teacher类,自定义析构函数;
对于普通方式实例化的对象,在销毁对象时是否自动调用析构函数;(会)
对于拷贝构造函数实例化的对象,在销毁对象时是否自动调用析构函数;(会)
头文件:
#include<iostream>
#include<string>
using namespace std;
class Teacher{
public:
Teacher(string name="Keiven",int age=20);
//申明有参 默认构造函数,带有初始值
Teacher(const Teacher &tea);//申明拷贝构造函数
~Teacher();
void setName(string name);
string getName();
void setAge(int age);
int getAge();
int getMax();
private:
string m_strName;
int m_iAge;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
主函数:
#include"Teacher.h"
#include<iostream>
#include<stdlib.h>
#include<string>
using namespace std;
/* ************************************************************************/
/* 定义一个Teacher类,具体要求如下:
/* 1、自定义析构函数
/* 2、对于普通方式实例化的对象,在销毁对象时是否自动调用析构函数
/* 3、通过拷贝构造函数实例化的对象,在销毁对象时是否自动调用析构函数
/* 数据成员:
/* 名字
/* 年龄
/* 成员函数:
/* 数据成员的封装函数
/* ************************************************************************/
Teacher::Teacher(string name,int age):m_strName(name),m_iAge(age){
//初始化列表形式定义有参构造函数
cout<<"Teacher(string name,int age)"<<endl;
}
//拷贝构造函数
Teacher::Teacher(const Teacher &tea){
cout<<"Teacher(const Teacher &tea)"<<endl;
}
//析构函数
Teacher::~Teacher(){
cout<<"~Teacher()"<<endl;
}
void Teacher::setName(string _name){
m_strName=_name;
}
string Teacher::getName(){
return m_strName;
}
void Teacher::setAge(int _age){
m_iAge=_age;
}
int Teacher::getAge(){
return m_iAge;
}
int main(){
Teacher t1;//在栈上实例化一个对象
Teacher t2(t1);//通过拷贝构造函数实例化对象
Teacher *p=new Teacher();//在堆上实例化一个对象
delete p;
system("pause");
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
结果:

- 对于普通方式实例化的对象,在销毁对象时是否自动调用析构函数;(会)
- 对于拷贝构造函数实例化的对象,在销毁对象时是否自动调用析构函数;(会)
二、封装篇(下)
4.1 对象数组与对象成员
(1)对象数组
很多时候我们不止需要一个对象,而是一组对象,如一个班50个学生,那就可以使用对象数组。

【对象数组代码实践】
题目:定义一个坐标(Coordinate)类,其数据成员包含横坐标和纵坐标,分别从栈和堆中实例化长度为3的对象数组,给数组中的元素分别赋值,最后遍历两个数组。

头文件:
class Coordinate{
public:
Coordinate();
~Coordinate ();
public:
int m_iX;
int m_iY;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
源程序:
#include<iostream>
#include<stdlib.h>
#include"Coordinate.h"
using namespace std;
/* 对象数组
/* 要求
1. 定义Coordiante类
2. 数据成员:m_iX、m_iY
3. 分别从栈和堆中实例化长度为3的对象数组
4. 给数组中的元素分别赋值
5. 遍历两个数组
/* *****************************************/
Coordinate::Coordinate(){
cout <<"Coordinate()"<<endl;
}
Coordinate::~Coordinate (){
cout <<"~Coordinate()"<< endl;
}
int main(){
Coordinate coor[3]; //从栈上实例化对象数组
coor[0].m_iX =3;
coor[0].m_iY =5;
Coordinate *p =new Coordinate[3];
p->m_iX = 7; //直接写p的话,就说明是第一个元素
p[0].m_iY =9; //等价于 p->m_iY = 9
p++; //将指针后移一个位置,指向第2个元素
p->m_iX = 11;
p[0].m_iY = 13; //这里p指向的是第二个元素,p[0]就是当前元素,等价于p->m_iY = 13
p[1].m_iX = 15;//第3个元素的横坐标
p++; //将指针后移一个位置,指向第3个元素
p[0].m_iY = 17;//这里p指向的是第三个元素,p[0]就是当前元素,等价于p->m_iY = 17
for(int i = 0; i < 3; i++){
cout <<"coor_X: "<< coor[i].m_iX <<endl;
cout <<"coor_Y: "<< coor[i].m_iY <<endl;
}
for(int j = 0; j < 3; j++){
//如果上面p没有经过++操作,就可以按下面来轮询
//cout <<"p_X: " << p[i].m_iX <<endl;
//cout <<"p_Y: " << p[i].m_iY <<endl;
//但是,上面我们对p做了两次++操作,实际p已经指向了第3个元素,应如下操作
cout <<"p_X: "<< p->m_iX <<endl;
cout <<"p_Y: "<< p->m_iY <<endl;
p--;
}
//经过了三次循环后,p指向了一个非法内存,不能直接就delete,而应该让p再指向我们申请的一个元素的,如下
p++; //这样p就指向了我们申请的内存
delete []p;
p = NULL;
system("pause");
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
结果 :
Coordinate()
Coordinate()
Coordinate()
Coordinate()
Coordinate()
Coordinate()
coor_X: 3
coor_Y: 5
coor_X: -858993460
coor_Y: -858993460
coor_X: -858993460
coor_Y: -858993460
p_X: 15
p_Y: 17
p_X: 11
p_Y: 13
p_X: 7
p_Y: 9
~Coordinate()
~Coordinate()
~Coordinate()
请按任意键继续. . .
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
从运行结果来看,首先看到的是打印出六行“Coordinatre()”,这是因为分别从栈实例化了长度为3的对象数组和从堆实例化了长度为3的对象数组,每实例化一个对象就要调用一次默认构造函数。
最后只打印出三行“~Coordinate()”,那是不是只是从堆上实例化的对象销毁时调用了析构函数,而从栈实例化的对象销毁时,也有调用函数
——从栈实例化的对象在销毁时,系统自动回收内存,即自动调用析构函数,只是当我们按照提示“请按任意键结束”,按下任何键后,屏幕会闪一下,就在这闪的过程中,会出现三行“~Coordinate()”的字样,只是我们不容易看到而已。
(2)对象成员
上面说的类的数据成员都是基本的数据类型,比如汽车类,我们只声明了汽车轮子个数,显然还不够,因为轮子本身就是一个对象,汽车上还有发动机、座椅等等对象。
如下的直角坐标,起点A和终点B,要定义这样的线段类和点坐标类
【对象成员代码实践 】
定义两个类:
(1)坐标类:Coordinate
数据成员:横坐标m_iX,纵坐标m_iY
成员函数:构造函数、析构函数,数据成员的封装函数
(2)线段类:Line
数据成员:点A m_coorA,点B m_coorB
成员函数:构造函数,析构函数,数据成员的封装函数,信息打印函数
头文件Coordinate.h:
class Coordinate{
public:
Coordinate();
~Coordinate();
void setX(int x);
int getX();
void setY(int y);
int getY();
private:
int m_iX;
int m_iY;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
头文件Line.h:
#include "Coordinate.h"
class Line{
public:
Line();
~Line();
void setA(int x, int y);
void setB(int x, int y);
void printInfo();
private:
Coordinate m_coorA;
Coordinate m_coorB;
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
源程序Coordinate.cpp:
#include <iostream>
#include "Coordinate.h"
using namespace std;
Coordinate::Coordinate (){
cout <<"Coordinate()"<<endl;
}
Coordinate::~Coordinate (){
cout <<"~Coordinate()"<<endl;
}
void Coordinate::setX(int x){
m_iX = x;
}
int Coordinate::getX(){
return m_iX;
}
void Coordinate::setY(int y){
m_iY = y;
}
int Coordinate::getY(){
return m_iY;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
源程序Line.h:
#include<iostream>
#include "Line.h"
//#include "Coordinate.h"
using namespace std;
Line::Line(){
cout <<"Line()"<< endl;
}
Line::~Line(){
cout <<"~Line()"<< endl;
}
void Line::setA(int x, int y){
m_coorA.setX(x);
m_coorA.setY(y);
}
void Line::setB(int x, int y){
m_coorB.setX(x);
m_coorB.setY(y);
}
void Line::printInfo(){
cout << "(" << m_coorA.getX() <<","<< m_coorA.getY()<< ")" <<endl;
cout << "(" << m_coorB.getX() <<","<< m_coorB.getY()<< ")" <<endl;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
源程序demo.cpp:
//我们首先来实例化一个线段类的对象,如下
#include <iostream>
#include "Line.h"
using namespace std;
int main(){
Line *p = new Line();
delete p;
p = NULL;
system("pause");
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
从运行结果来看,先连续调用了两次坐标类的构造函数,再调用了一次线段类的构造函数,这就意味着先创建了两个坐标类的对象,这两个坐标类的对象就是A点和B点,然后才调用线段这个对象,线段这个对象是在A点和B点初始化完成之后才被创建。
而在销毁时,先调用的是线段类的析构函数,然后连续调用两次坐标类的析构函数。可见,对象成员的创建与销毁的过程正好相反,也验证了我们之前给出的结论。
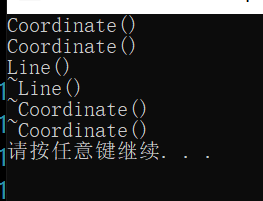
作为一条线段来说,我们希望的是,在这条线段创建的时候就已经将线段的起点和终点确定下来。为了达到这个目的,我们往往希望线段这个类的构造函数是带有参数的,并且这个参数将来能够传给这两个点,所以可以进一步完善这个程序。
4.2 深拷贝与浅拷贝
【栗子1】

在这个例子中,我们定义了一个数组的类(Array),在这个类中,定义了一个数据成员(m_iCount),并且定义了构造函数,在其中对数据成员赋了初值5,另外还定义了一个拷贝构造函数。在这个拷贝构造函数是这样实现的,传入的参数是arr,这个参数的数据类型也是Array,所以其肯定也含有数据成员m_iCount,在这个拷贝构造函数中,我们将arr的数据成员m_iCount赋值给本身的m_icount。
当我们使用时,先用Array arr1来实例化一个arr1的时候,就会调用到arr1的构造函数,也就是说将arr1中的数据成员m_icount赋了初值5。而我们使用Array arr2 = arr1的时候,也就是用arr1去初始化arr2——这时实例化arr2的时候就会调用到它的拷贝构造函数,拷贝构造函数中的参数arr其实就是arr1,里面代码实现的时候,就相当于将arr1的数据成员m_icount赋值给arr2的数据成员m_icount。
【栗子2】
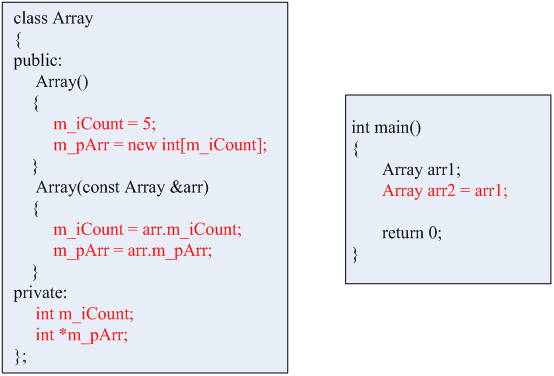
在这个例子中,我们新加了一个数据成员,它是int型的指针m_pArr,其在构造函数中,从堆中申请了一段内存,并且指向了申请的这段内存,内存的大小就是m_icount。而拷贝构造函数中,我们将arr的数据成员m_iCount赋值给本身的m_icount,同时将arr的数据成员m_pArr赋值给本身的m_pArr。当我们使用时,先用Array arr1来实例化一个arr1的时候,就会调用到arr1的构造函数,也就是说将arr1中的数据成员m_icount赋了初值5。
而我们使用Array arr2 = arr1的时候,也就是用arr1去初始化arr2,这时实例化arr2的时候就会调用到它的拷贝构造函数,于是就将arr1的数据成员m_icount赋值给arr2的数据成员m_icount,将arr1的数据成员m_pArr赋值给arr2的数据成员m_pArr。
在这两个例子中,有共同的特点,那就是,只是将数据成员的值作了简单的拷贝,我们就把这种拷贝模式称为浅拷贝。但是对于第一个例子来说,使用浅拷贝的方式来实现拷贝构造函数并没有任何问题,而对于第二个例子来说,肯定是有问题的。我们来思考一下,经过浅拷贝之后,对象arr1中的指针和对象arr2中的指针势必会指向同一块内存(因为我们将arr1的数据成员m_pArr赋值给arr2的数据成员m_pArr),这里假设指向的地址是0x00FF00(如下图所示)。

在这个时候,如果我们先给arr1的m_pArr赋了一些值,也就是说在这段内存中就写了一些值,然后我们再给arr1的m_pArr去赋值的时候,这段内存就会被重写,而覆盖掉了之前给arr1的m_pArr所赋的一些值。这一点还不是最严重的问题,更严重的问题是,当我们去销毁arr1这个对象的时候,我们为了避免内存泄漏,肯定会释放掉m_pArr所指向的这段内存。如果我们已经释放掉了这段内存,我们再去销毁arr2这个对象时,我们肯定也会以同样的方式去释放掉arr2中m_pArr这个指针所指向的这段内存,那么就相当于,同一块内存被释放了两次,那么这种问题肯定是有问题的。面对这种问题,计算机会以崩溃的方式来向你抗议。
所以我们希望拷贝构造函数所完成的工作是这样的,两个对象的指针所指向的应该是两个不同的内存,拷贝的时候不是将指针的地址简单的拷贝过来,而是将指针所指向的内存当中的每一个元素依次的拷贝过来,这才是我们真正想要的。(如下图所示)

为了实现刚才的效果,我们需要如下修改:

这段代码与之前的代码的区别在于其拷贝构造函数,其中的m_pArr不是直接赋值arr中的m_pArr,而是先分配一段内存(这段内存分配成功与否,这里没有判断,因为这个不是这里要将的重点),重点是下面的一段for循环语句。我们应该将arr中的m_pArr的每一个元素都拷贝到当前的m_pArr所指向的相应的内存当中去。这样的拷贝方式与之前所讲到的拷贝方式是有本质区别的。
总结:当进行对象拷贝时,不是简单的做值的拷贝,而是将堆中内存的数据也进行了拷贝,那么就称这种拷贝模式为深拷贝。
【深浅拷贝代码实践】
-
定义一个Array类。
- 数据成员:
m_iCount - 成员函数:构造函数、拷贝构造函数,析构函数
- 数据成员的封装函数
- 要求通过这个例子体会浅拷贝原理
- 数据成员:
-
在1的基础上增加一个数据成员:
m_pArr- 并增加m_pArr地址查看函数
- 同时改造构造函数、拷贝构造函数和析构函数
- 要求通过这个例子体会深拷贝的原理和必要性
4.3 对象指针、对象成员指针
(1)对象指针

定义了一个坐标的类(Coordinate),其有两个数据成员(一个表示横坐标,一个表示纵坐标)。当我们定义了这个类之后,我们就可以去实例化它了。如果我们想在堆中去实例化这个对象呢,就要如下所示:
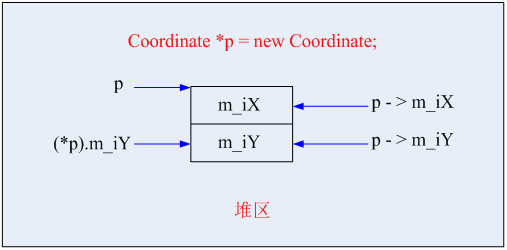
通过new运算符实例化一个对象后(这个对象就会执行它的构造函数),而对象指针p就会指向这个对象。我们的重点是要说明p与这个对象在内存中的相关位置以及它们之间的对应关系。
当我们通过这样的方式实例化一个对象后,它的本质就是在内存中分配出一块空间,在这块空间中存储了横坐标(m_iX)和纵坐标(m_iY),此时m_iX的地址与p所保存的地址应该是一致的,也就是说p所指向的就是这个对象的第一个元素(m_iX)。如果想用p去访问这个元素,很简单,就可以这样来访问(p -> m_iX或者p -> m_iY),也可以在p前加上*,使这个指针变成一个对象,然后通过点号(.)来访问相关的数据成员(如(*p).m_iY)。

注意:这里的new运算符可以自动调用对象的构造函数,而C语言中的malloc则只是单纯的分配内存而不会自动调用构造函数。
(2)对象指针代码实践
定义Coordinate类:
- 数据成员:
m_iX和m_iY - 声明对象指针,并通过指针操控对象
- 计算两个点,横、纵坐标的和
- 1
(3)对象成员指针
对象成员,就是作为一个对象来说,它成为了另外一个类的数据成员。而对象成员指针呢,则是对象的指针成为了另外一个类的数据成员了。
(4)内存中的对象成员指针

当实例化line这个对象的时候,那么两个指针(m_pCoorA和m_pCoorB)也会被定义出来,由于两个指针都是指针类型,那么都会占4个基本内存单元。如果我们在构造函数当中,通过new这样的运算符从堆中来申请内存,实例化两个Coordinate这样的对象的话呢,这两个Coordinate对象都是在堆中的,而不在line这个对象当中,所以刚才我们使用sizeof的时候呢,也只能得到8,这是因为m_pCoorA占4个基本内存单元,m_pCoorB占4个基本内存单元,而右边的两个Coordinate对象并不在line这个对象的内存当中。当我们销毁line对象的时候呢,我们也应该先释放掉堆中的内存,然后再释放掉line这个对象。
(5)对象成员指针代码实践
定义两个类:
坐标类:Coordinate
数据成员:m_iX和m_iY
成员函数:构造函数、西沟函数、数据成员封装函数
线段类:Line
数据成员:点A指针 m_pCoorA,点B指针m_pCoorB
成员函数:构造函数、析构函数、信息打印函数
4.4 this指针
this指针就是指向其自身数据的指针。

【this指针代码实践】
定义一个Array类:
数据成员:m_iLen 表示数组长度
成员函数:构造函数 析构函数 m_iLen的封装函数
信息打印函数printInfo

4.5 const进阶

4.6 常指针和常引用
(1)对象的引用和对象的指针
(2)对象的常引用和常指针
文章来源: andyguo.blog.csdn.net,作者:山顶夕景,版权归原作者所有,如需转载,请联系作者。
原文链接:andyguo.blog.csdn.net/article/details/122764129

- 点赞
- 收藏
- 关注作者
评论(0)