python jieba库用法

【摘要】 结巴分词支持以下3种分词模式:精确模式。试图将句子最精确地切开,适合文本分析。全模式。将句子中所有的可能成词的词语都扫描出来,速度非常快,但是不能解决歧义。搜索引擎模式。在精确模式的基础上,对长词再次切分,提高召回率,适用于搜索引擎分词。结巴分词使用的算法是基于统计的分词方法,主要有如下3种方法:基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图采用了动态规划...
结巴分词支持以下3种分词模式:
精确模式。试图将句子最精确地切开,适合文本分析。
全模式。将句子中所有的可能成词的词语都扫描出来,速度非常快,但是不能解决歧义。
搜索引擎模式。在精确模式的基础上,对长词再次切分,提高召回率,适用于搜索引擎分词。
结巴分词使用的算法是基于统计的分词方法,主要有如下3种方法:
基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图
采用了动态规划查找最大概率路径,找出基于词频的最大切分组合。
对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法
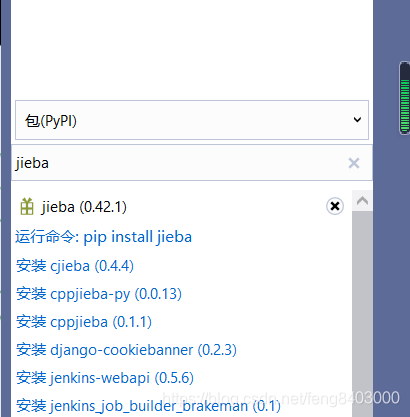
1、安装【jieba】库【pip install jieba】
![]()
2、jieba精确模式分词使用lcut()函数,类似cut()函数,其参数和cut()函数是一致的,只不过返回结果是列表而不是生成器,默认使用精确模式。
默认模式。句子精确地切开,每个字符只会出席在一个词中,适合文本分析;
import jieba
string = '真正的程序员的程序不会在第一次就正确运行,但是他们愿意守着机器进行若干个小时的调试改错。'
result = jieba.lcut(string)
print(len(result), '/'.join(result))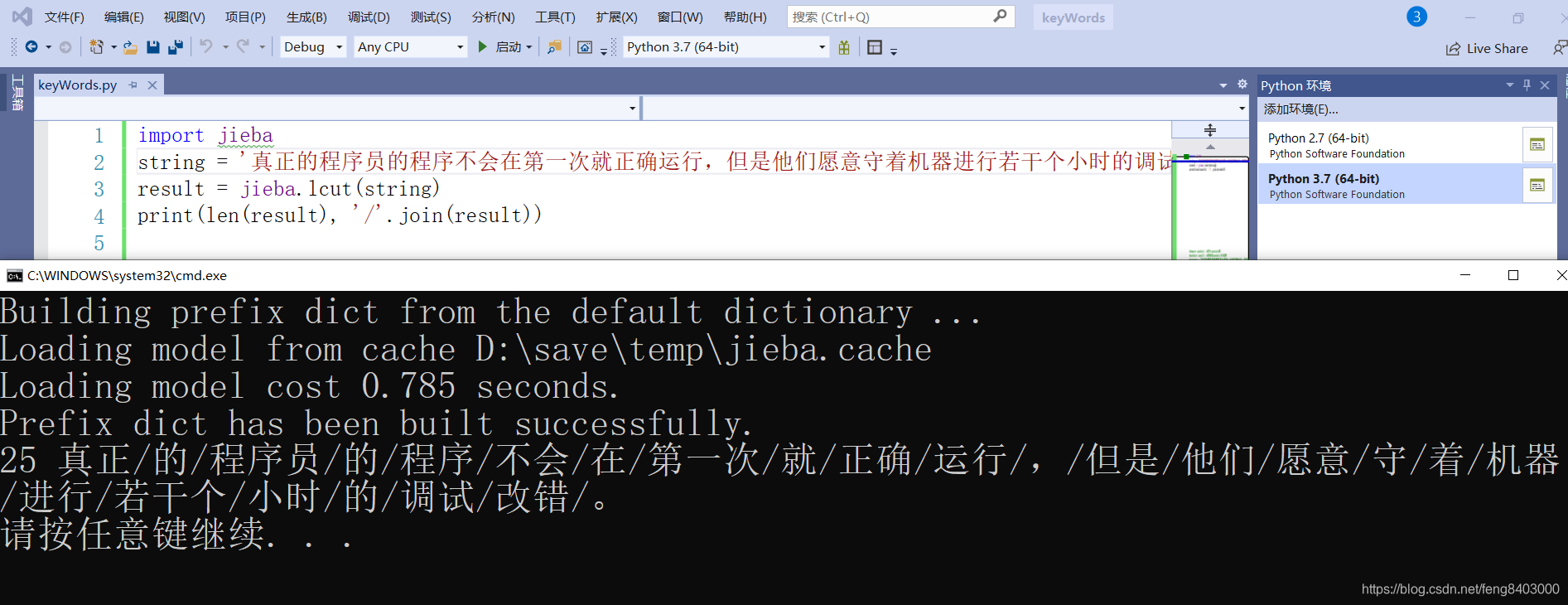
![]()
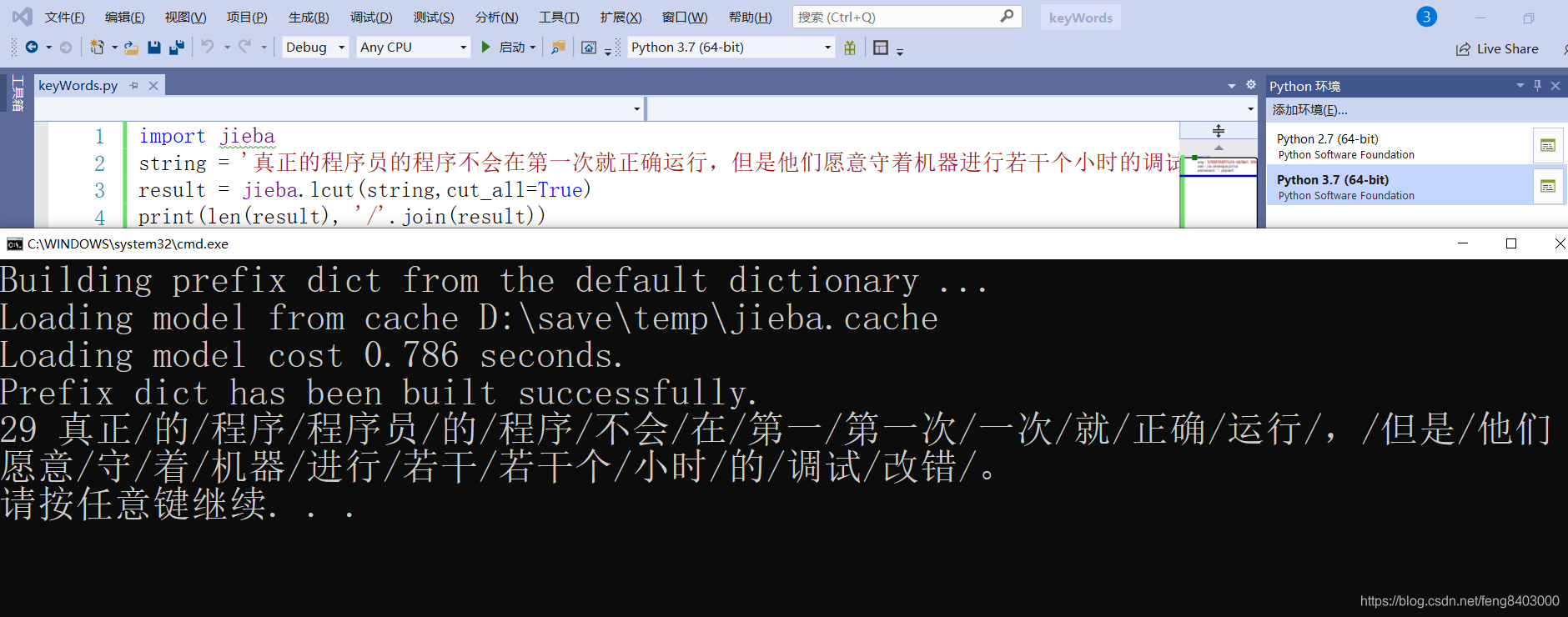
3、全模式【cut_all=True】
把句子中所有词都扫描出来, 速度非常快,有可能一个字同时分在多个词
import jieba
string = '真正的程序员的程序不会在第一次就正确运行,但是他们愿意守着机器进行若干个小时的调试改错。'
result = jieba.lcut(string,cut_all=True)
print(len(result), '/'.join(result))
![]()
4、搜索引擎模式【lcut_for_search()】
在精确模式的基础上,对长度大于2的词再次切分,召回当中长度为2或者3的词,从而提高召回率,常用于搜索引擎。
import jieba
string = '真正的程序员的程序不会在第一次就正确运行,但是他们愿意守着机器进行若干个小时的调试改错。'
result = jieba.lcut_for_search(string)
print(len(result), '/'.join(result))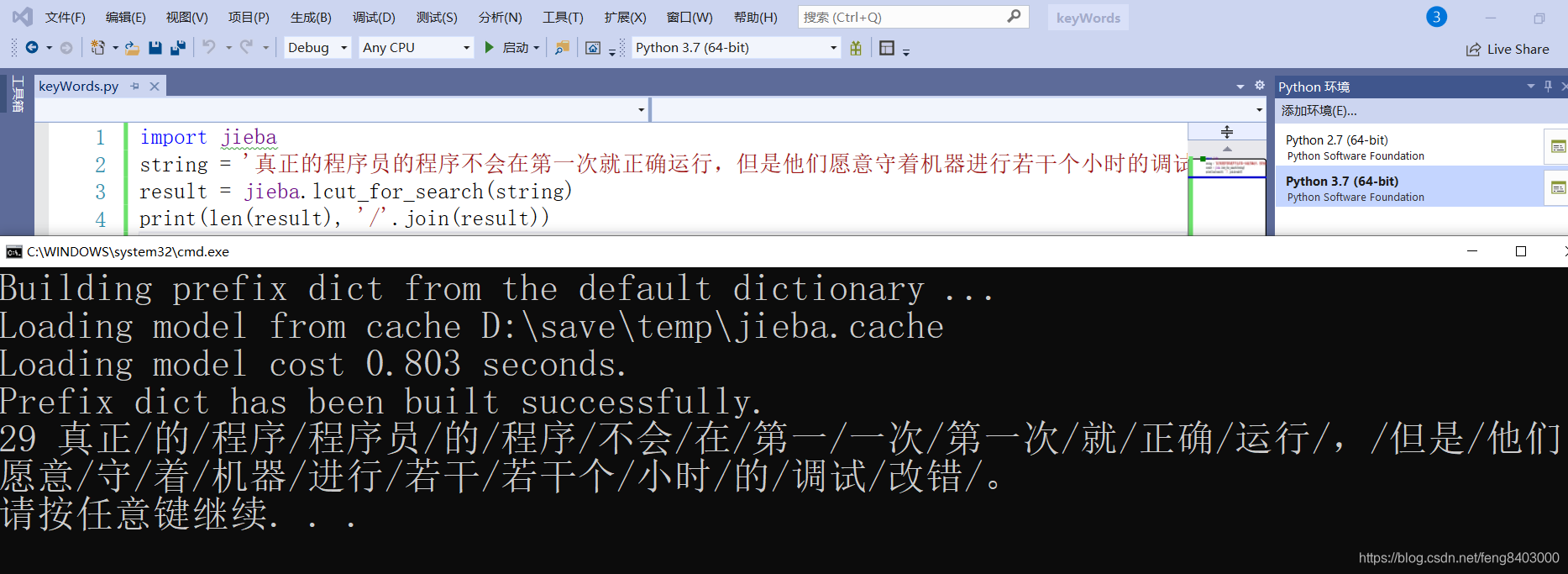
![]()
希望对大家有所帮助。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)