零基础学Python-爬虫-5、下载网络视频

【摘要】 本套课程正式进入Python爬虫阶段,具体章节根据实际发布决定,可点击【python爬虫】分类专栏进行倒序观看:【重点提示:请勿爬取有害他人或国家利益的内容,此课程虽可爬取互联网任意内容,但无任何收益,只为大家学习分享。】开发环境:【Win10】开发工具:【Visual Studio 2019】Python版本:【3.7】目标:【百度-->视频-->好看视频:好看视频--轻松有收获】1、查...
本套课程正式进入Python爬虫阶段,具体章节根据实际发布决定,可点击【python爬虫】分类专栏进行倒序观看:
【重点提示:请勿爬取有害他人或国家利益的内容,此课程虽可爬取互联网任意内容,但无任何收益,只为大家学习分享。】
开发环境:【Win10】
开发工具:【Visual Studio 2019】
Python版本:【3.7】
目标:【百度-->视频-->好看视频:】
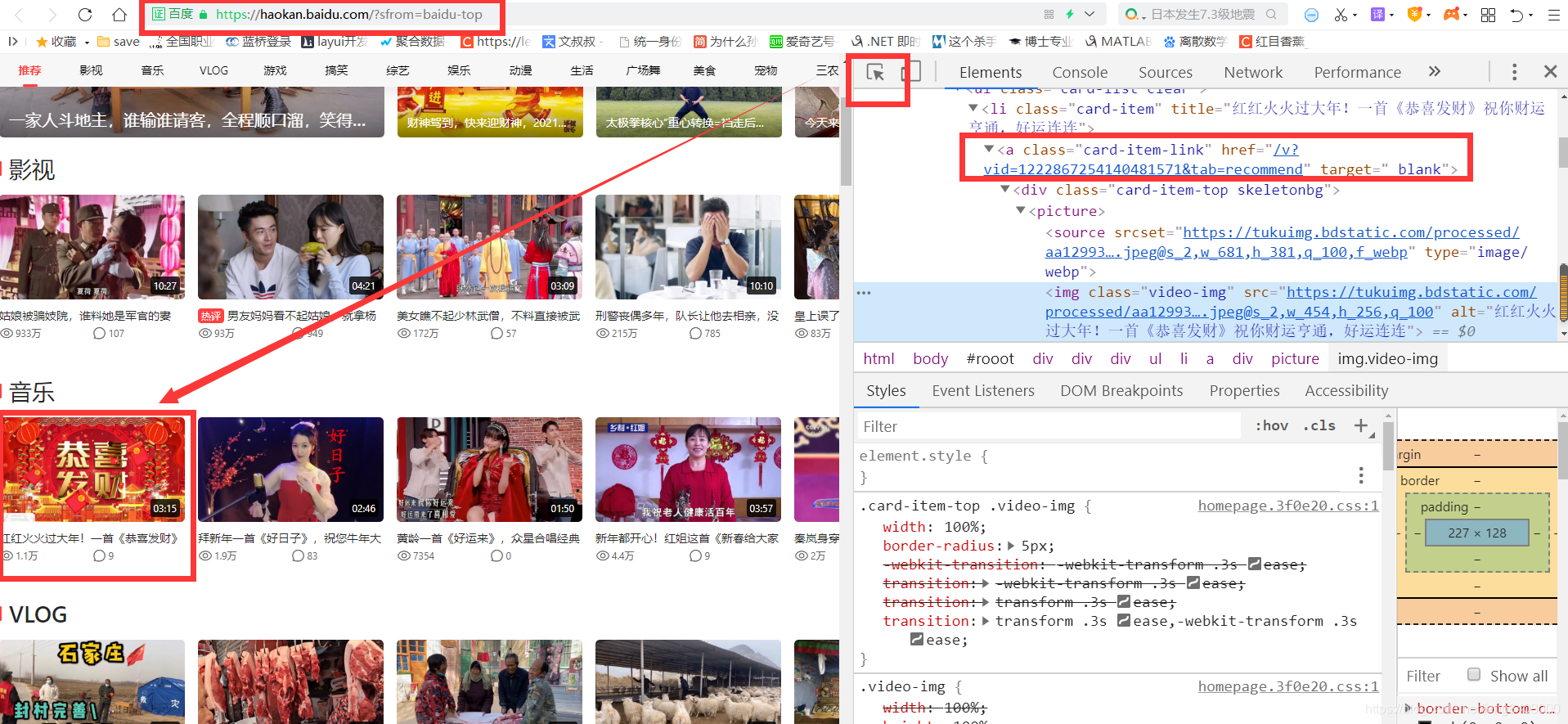
1、查找视频访问位置:
1.1、外层地址:
![]()
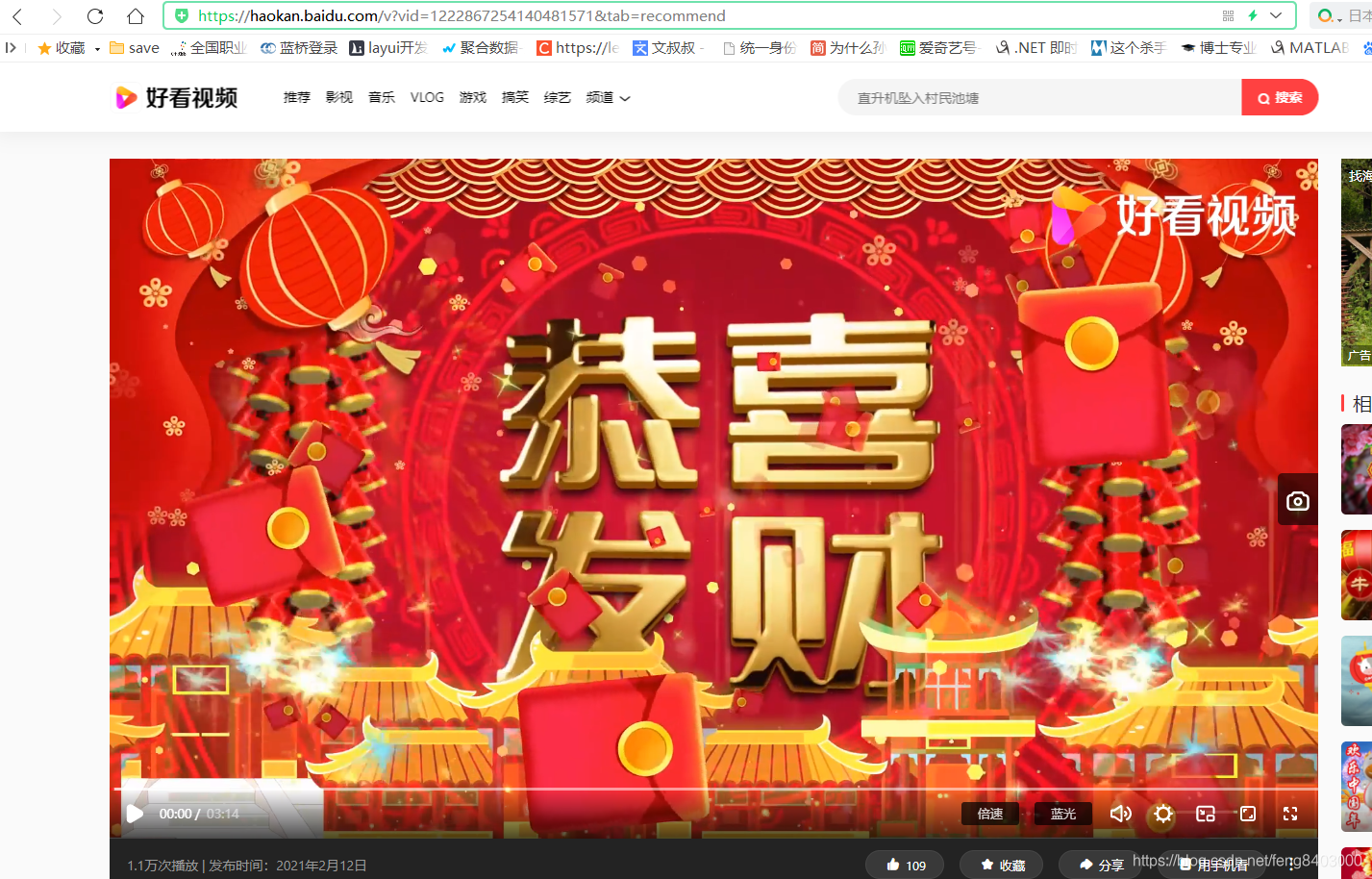
地址拼接测试:域名+a标签的href地址:【】
访问成功:
![]()
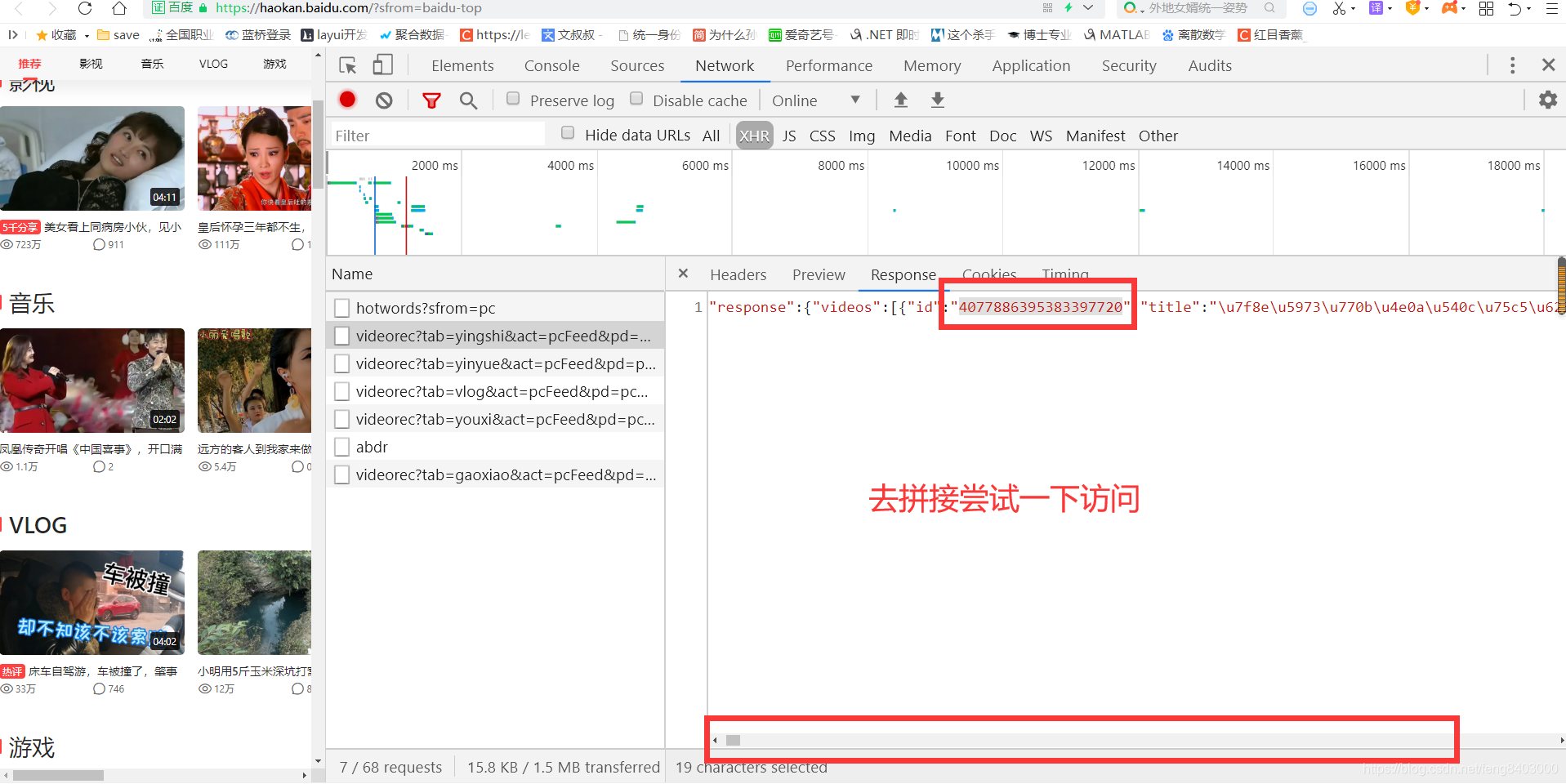
那么是否有现成的数据集呢?咱们去网络里看看:
![]()
尝试成功:【】
问题是打开的页面更换了个视频的vid~~~~拿到json集体试一试吧。
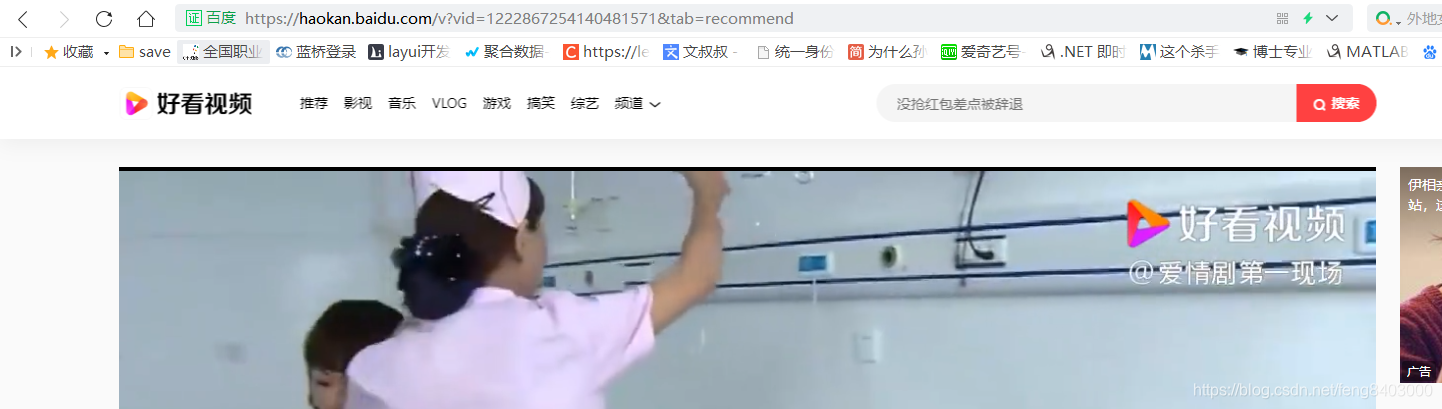
![]()
获取json:
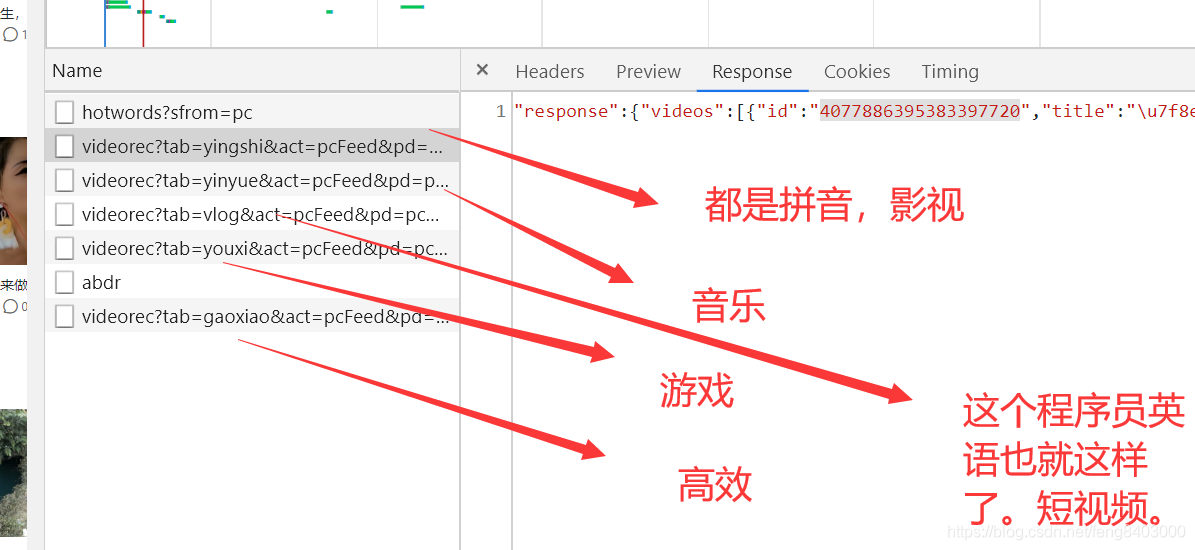
![]()
2、获取json数据:
音乐:【】
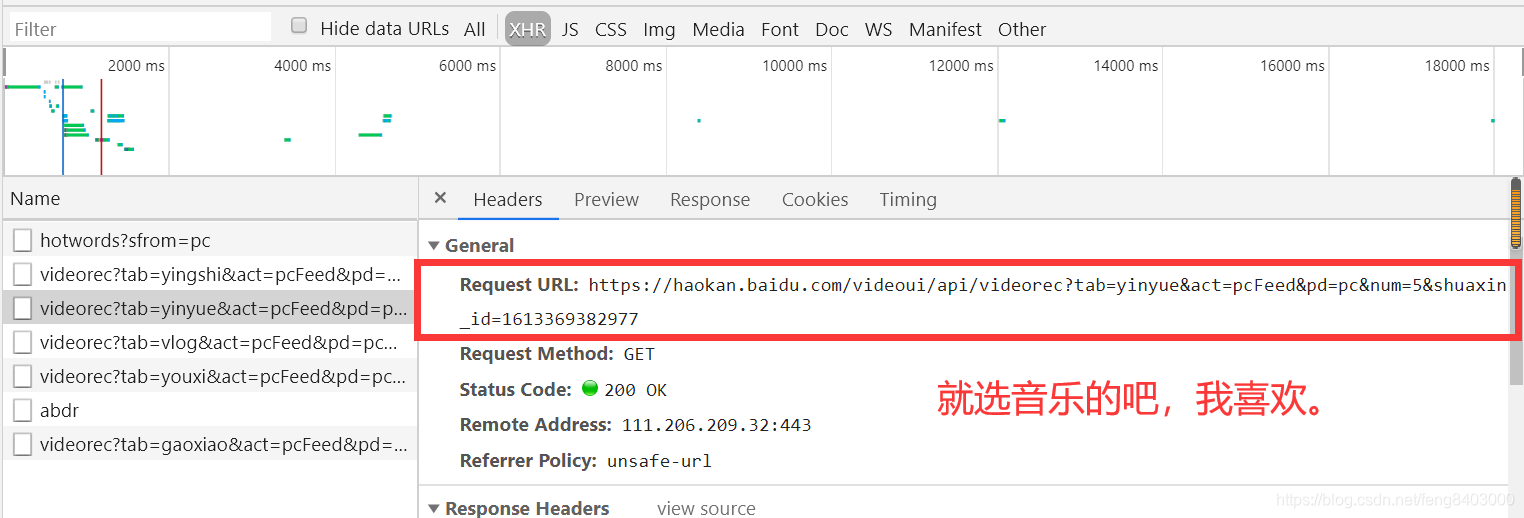
![]()
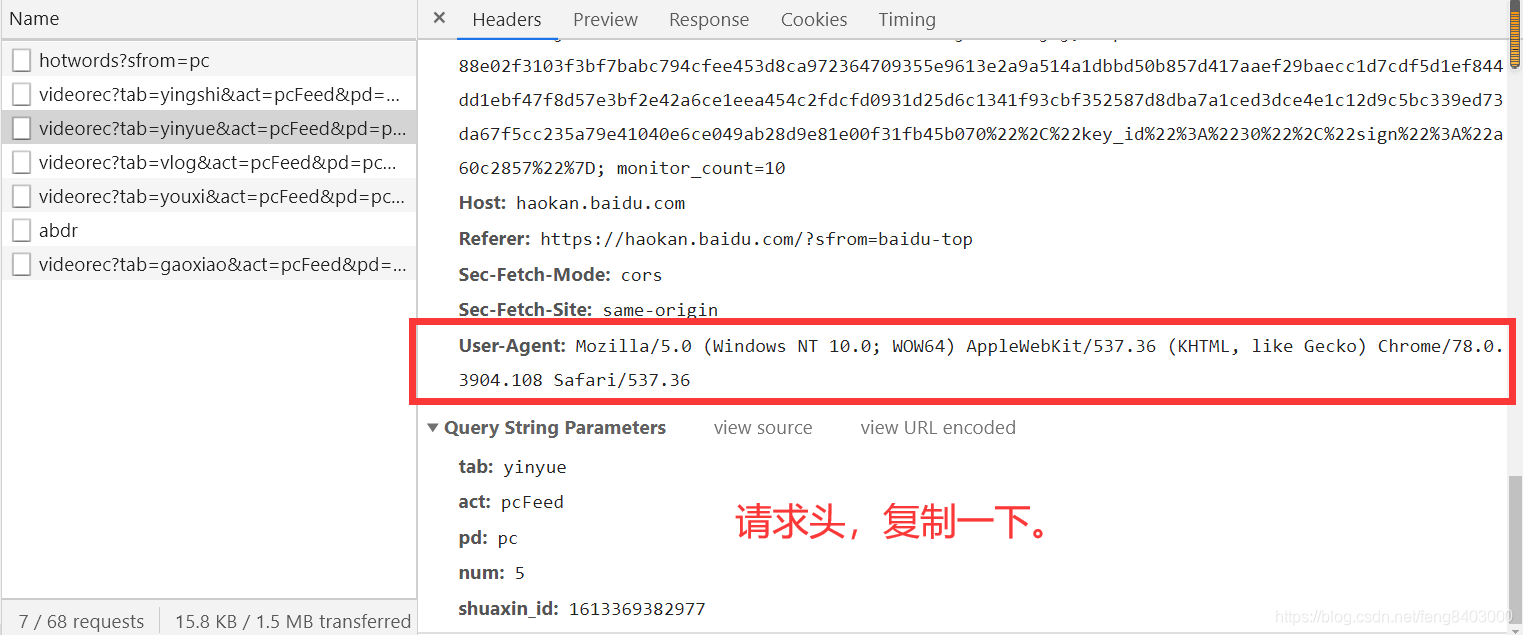
![]()
获取测试:
import requests
import uuid
import random
import time
#可更换
url ="https://haokan.baidu.com/videoui/api/videorec?tab=yinyue&act=pcFeed&pd=pc&num=5&shuaxin_id=1613369382977"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
resp = requests.get(url, headers=headers)
resp_json = resp.json()
print(resp_json)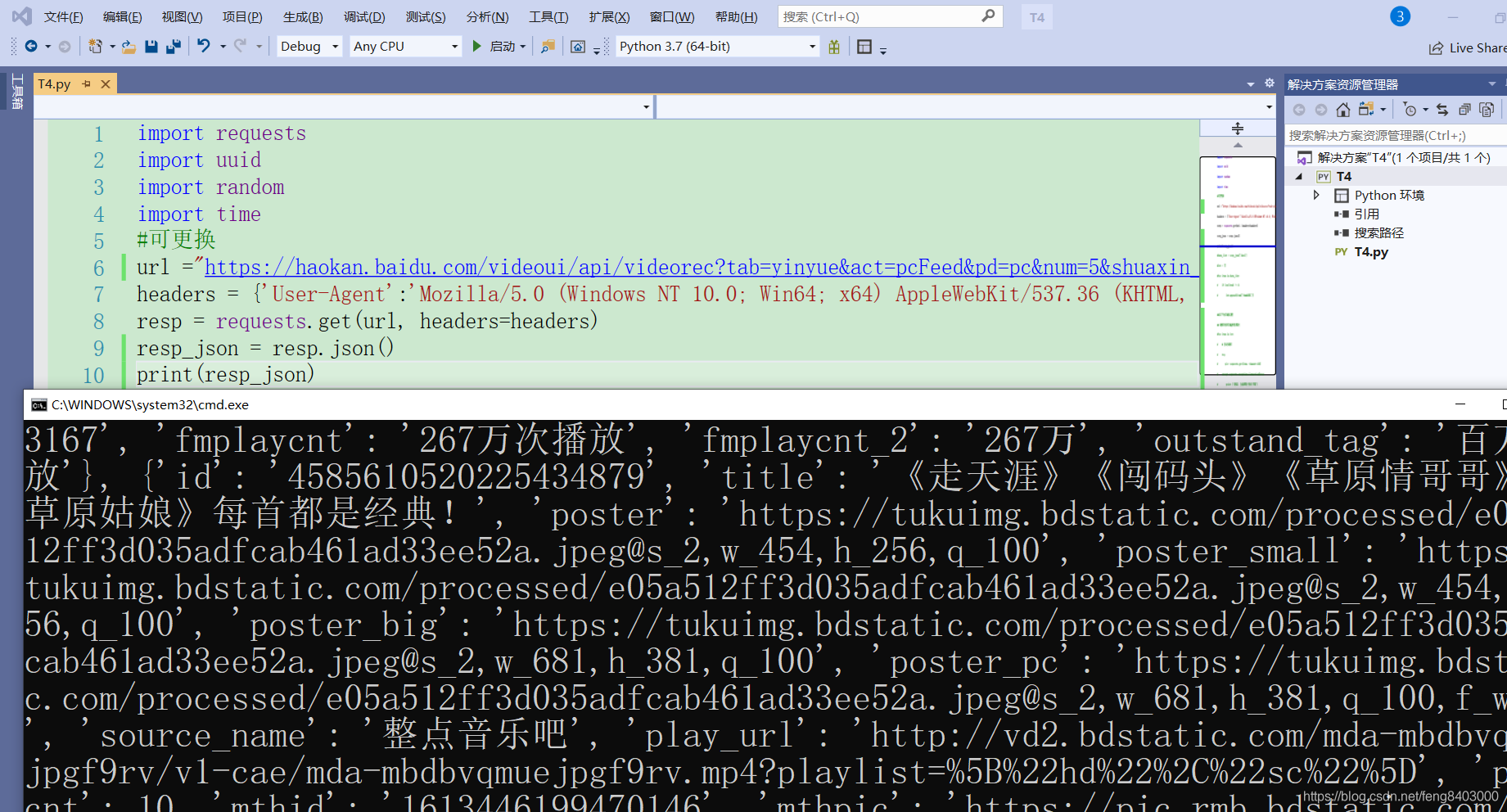
![]()
3、解析json数据:
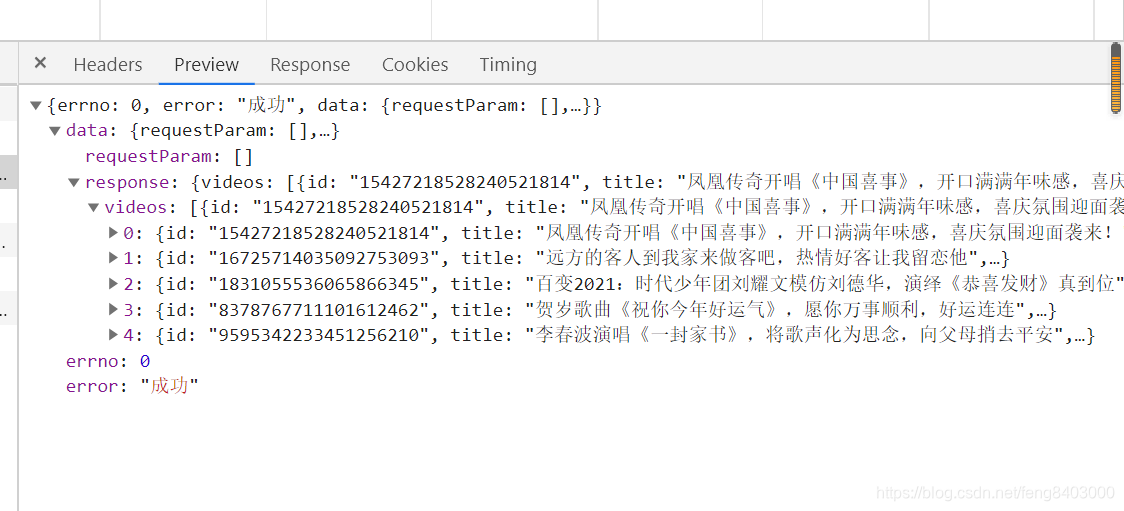
![]()
我们主要要id和title就行,但是,我发现了好东西:【play_url】,明显的代表程序员sql查询的时候直接【select *】处理的。
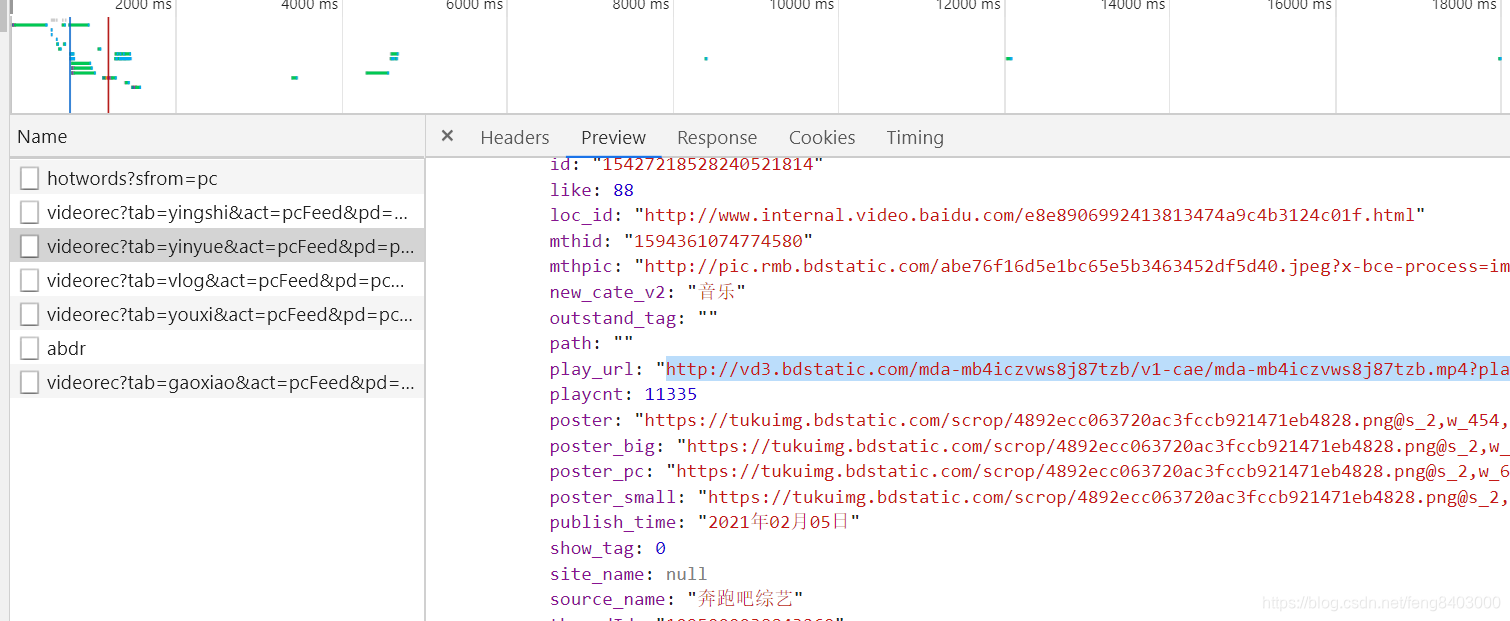
![]()
有了地址就可以直接获取下载了:
import requests
import uuid
import random
import time
#可更换参数:tab={}&num={}我这里不多下载,10个就可以了。
url ="https://haokan.baidu.com/videoui/api/videorec?tab=yinyue&act=pcFeed&pd=pc&num=10&shuaxin_id=1613369382977"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
resp = requests.get(url, headers=headers)
resp_json = resp.json()
data_list = resp_json['data']['response']['videos']
for x in data_list:
print(x["play_url"])
print(x["title"])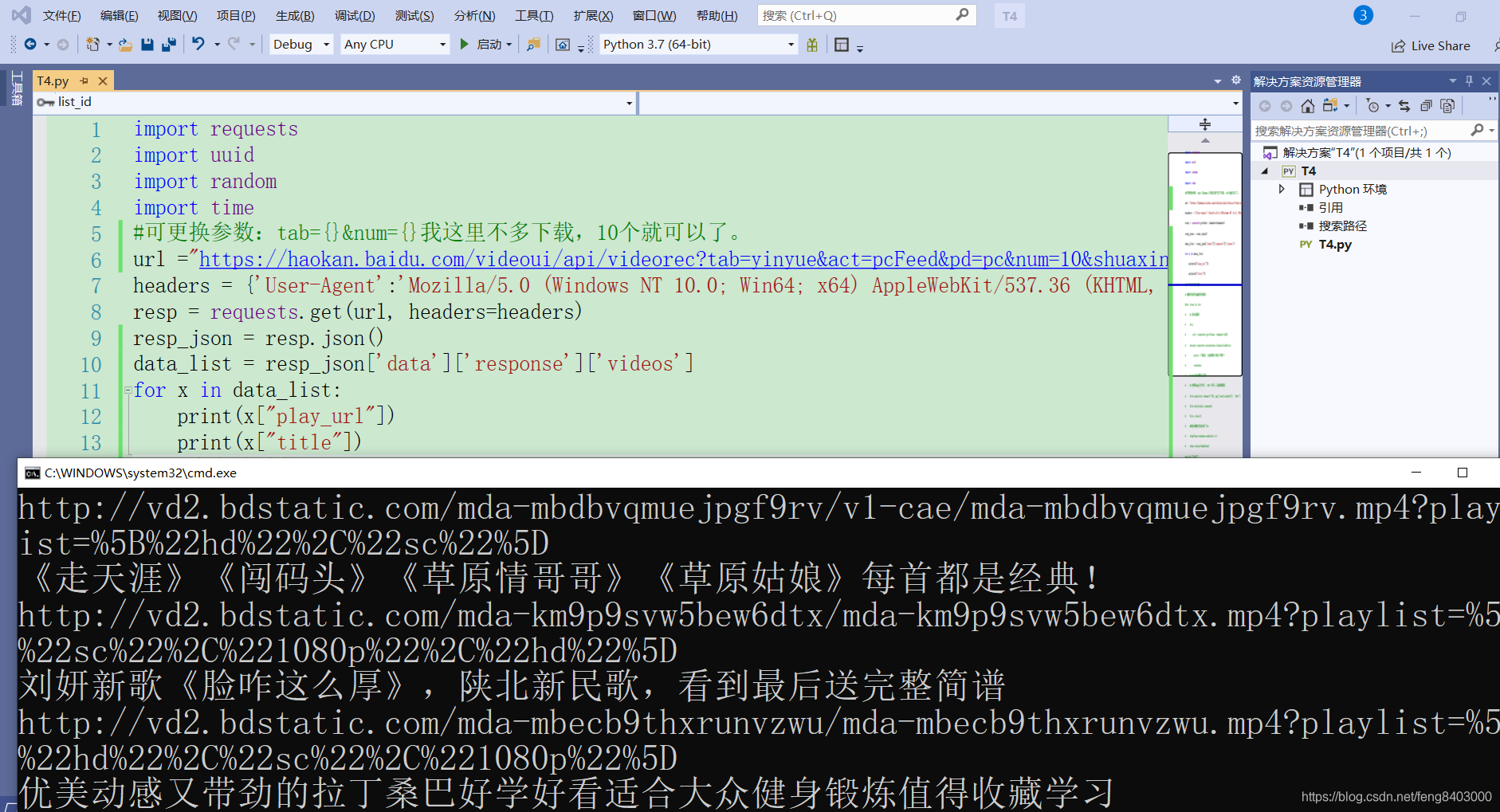
![]()
4、视频下载到本地:
import requests
import uuid
import random
import time
#可更换参数:tab={}&num={}我这里不多下载,10个就可以了。
url ="https://haokan.baidu.com/videoui/api/videorec?tab=yinyue&act=pcFeed&pd=pc&num=10&shuaxin_id=1613369382977"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
resp = requests.get(url, headers=headers)
resp_json = resp.json()
data_list = resp_json['data']['response']['videos']
lst=[]
for x in data_list:
lst.append({"play_url":x["play_url"],"title":x["title"]})
#以下为存储过程
# 遍历列表存储所有图片
for item in lst:
# 发送请求
try:
pic= requests.get(item["play_url"], timeout=100)
except requests.exceptions.ConnectionError:
print ('错误:当前视频无法下载')
continue
# uuid4为图片名称
#,创建img文件夹, wb+:写入二进制数据
file=open(str.format("{0}.mp4",item["title"]), 'wb+')
file.write(pic.content)
file.close()
print(item["title"],"下载完毕")
#每次操作完休息1~3s
timeStop=random.randint(1,4)
time.sleep(timeStop)
print("完成")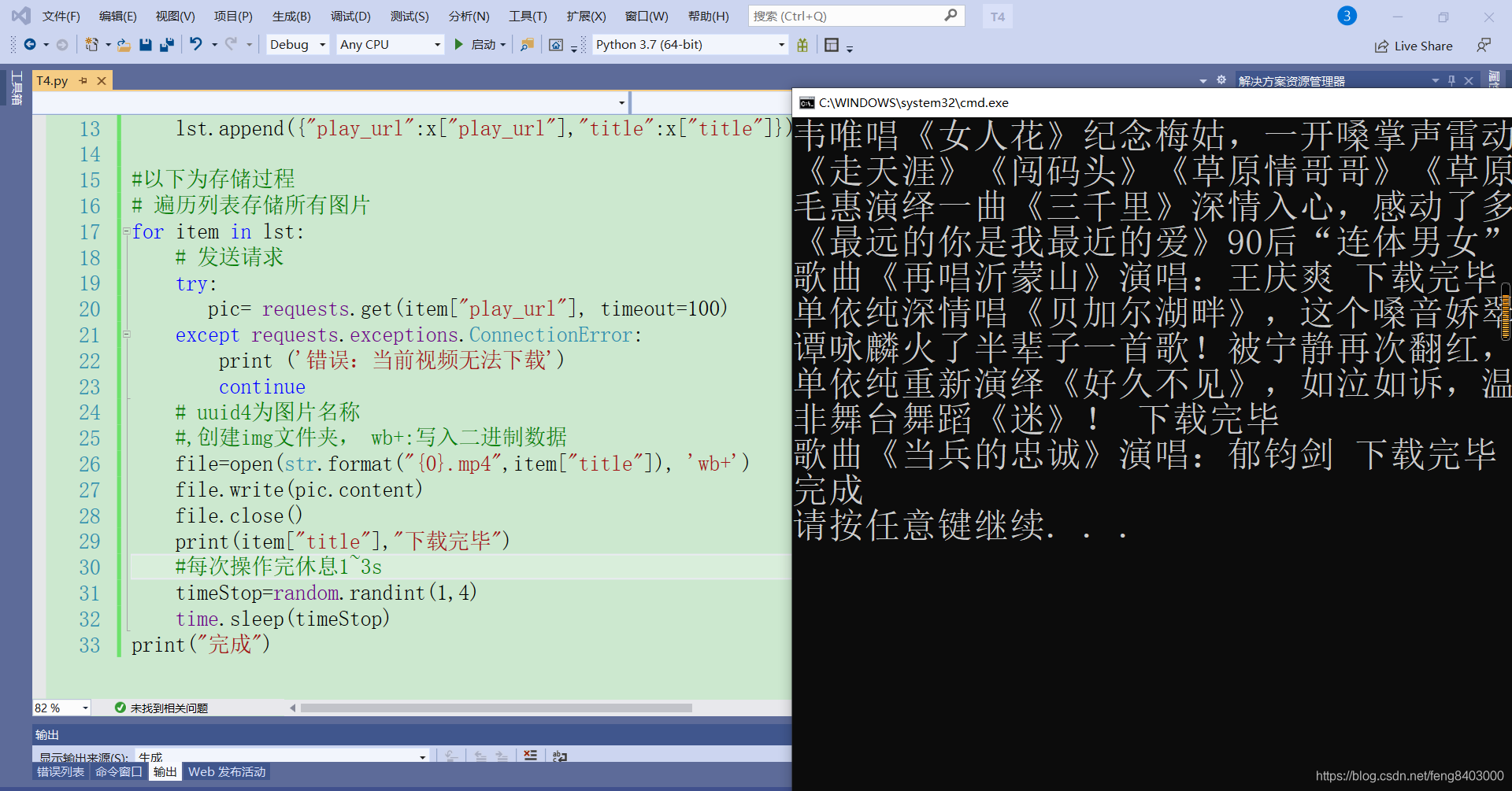
![]()
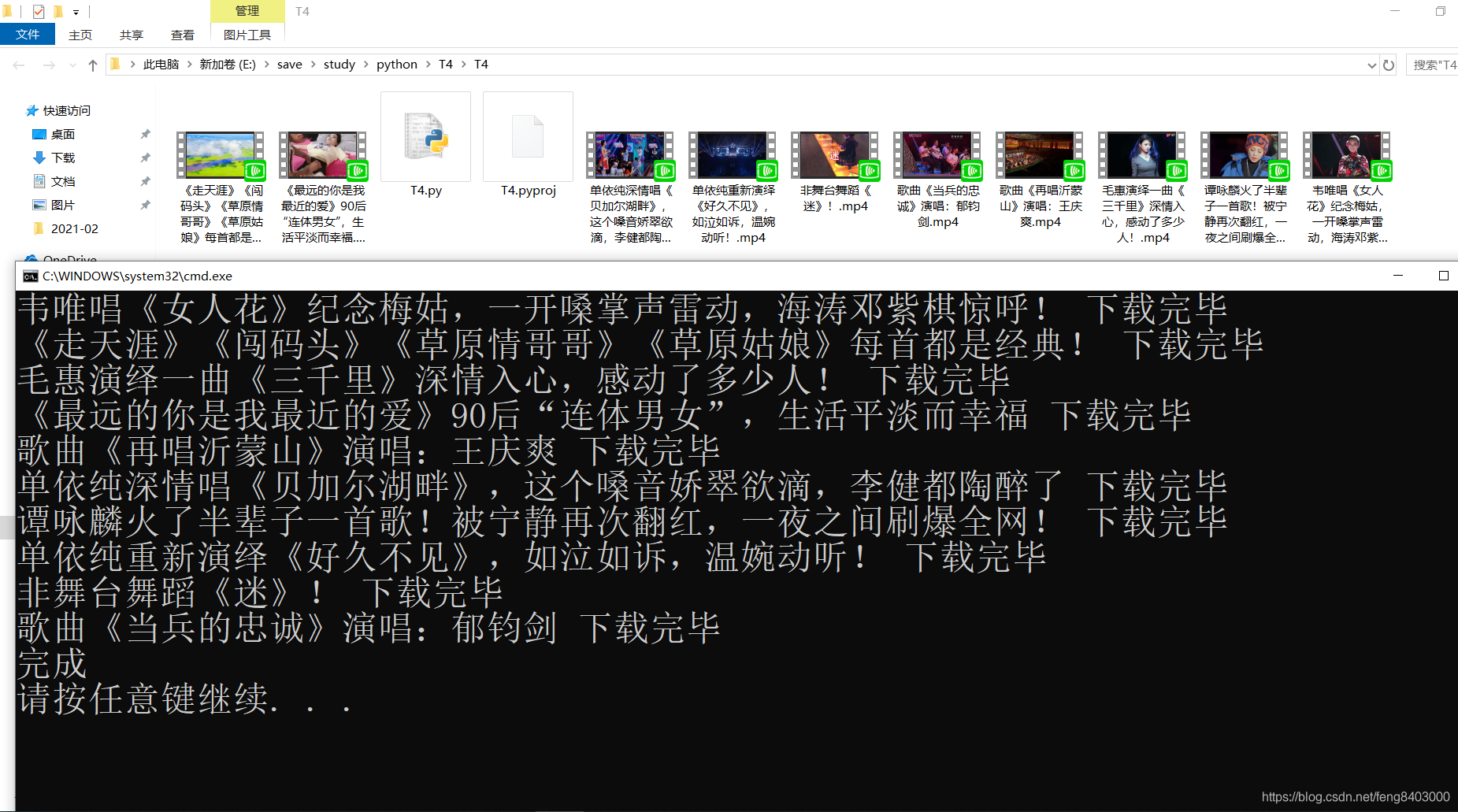
![]()
5、总结:
a)、百度视频 竟然各种不加密,让人感到很迷惑。
b)、可以保存保存点资源,毕竟流量都是包月的,哈哈。
欢迎【点赞】、【评论】、【关注】、【收藏】、【打赏】,为推广知识贡献力量。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)