零基础学Python-爬虫-4、下载网络图片

【摘要】 本套课程正式进入Python爬虫阶段,具体章节根据实际发布决定,可点击【python爬虫】分类专栏进行倒序观看:【重点提示:请勿爬取有害他人或国家利益的内容,此课程虽可爬取互联网任意内容,但无任何收益,只为大家学习分享。】开发环境:【Win10】开发工具:【Visual Studio 2019】Python版本:【3.7】1、创建项目:2、寻找目标:直接百度搜图片url有共同部分,可以...
本套课程正式进入Python爬虫阶段,具体章节根据实际发布决定,可点击【python爬虫】分类专栏进行倒序观看:
【重点提示:请勿爬取有害他人或国家利益的内容,此课程虽可爬取互联网任意内容,但无任何收益,只为大家学习分享。】
开发环境:【Win10】
开发工具:【Visual Studio 2019】
Python版本:【3.7】
1、创建项目:
![]()
2、寻找目标:直接百度搜图片
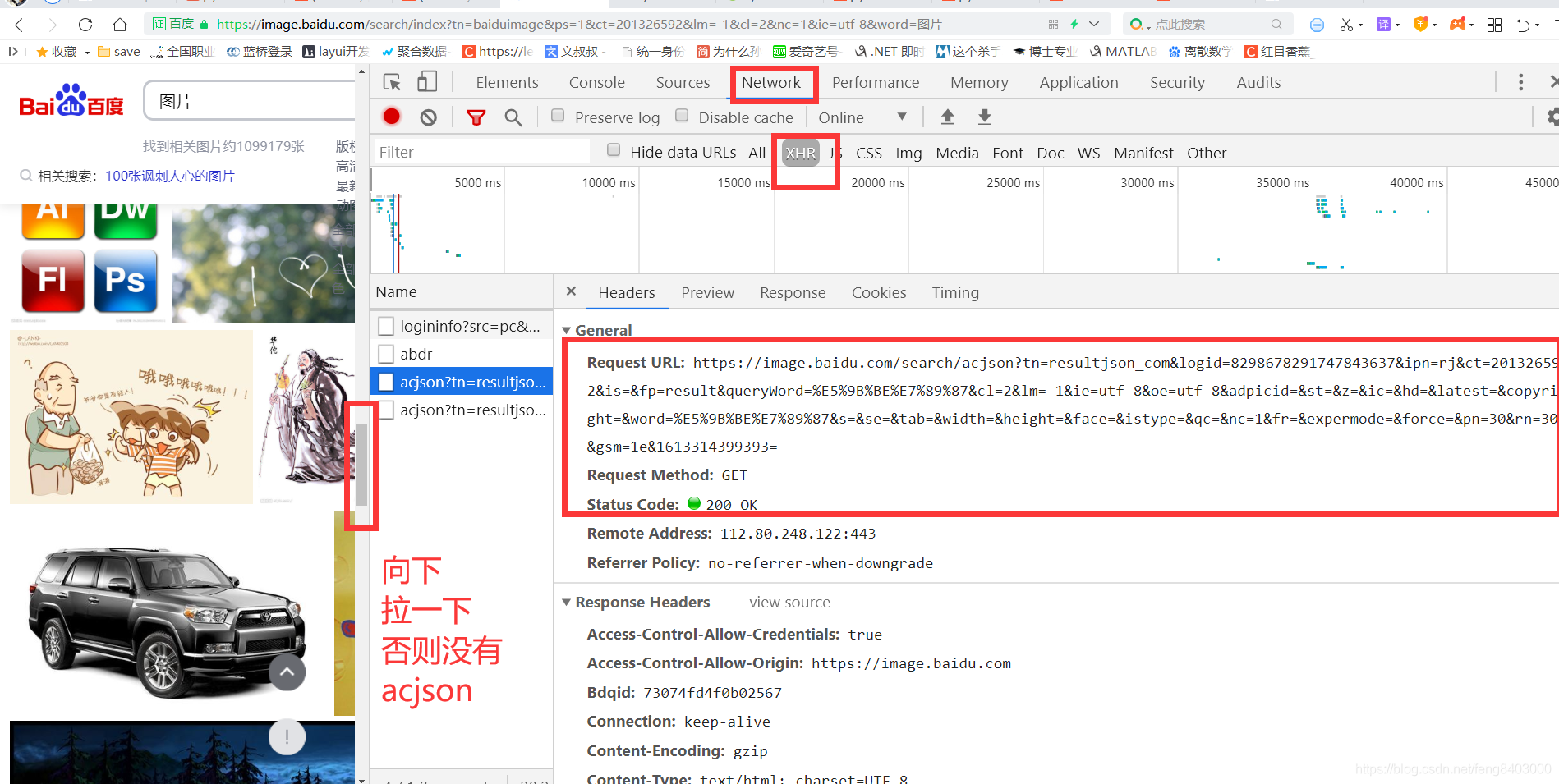
![]()
url有共同部分,可以理解成步长为30,也就是每页30张图片


3、获取图片路径列表:使用路径为【】自己更换即可。
由于是json数据,直接解析处理即可:(写死的路径,)
import requests
url ="https://image.baidu.com/search/acjson?tn=resultjson_com&logid=7266558810577433352&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E9%98%BF%E5%87%A1%E8%BE%BE&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word=%E9%98%BF%E5%87%A1%E8%BE%BE&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=60&rn=30&gsm=3c&1613315170875="
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
resp = requests.get(url, headers=headers)
resp_json = resp.json()
data_list = resp_json['data']
lst = []
for item in data_list:
if len(item) != 0:
lst.append(item['thumbURL'])
for x in lst:
print(x)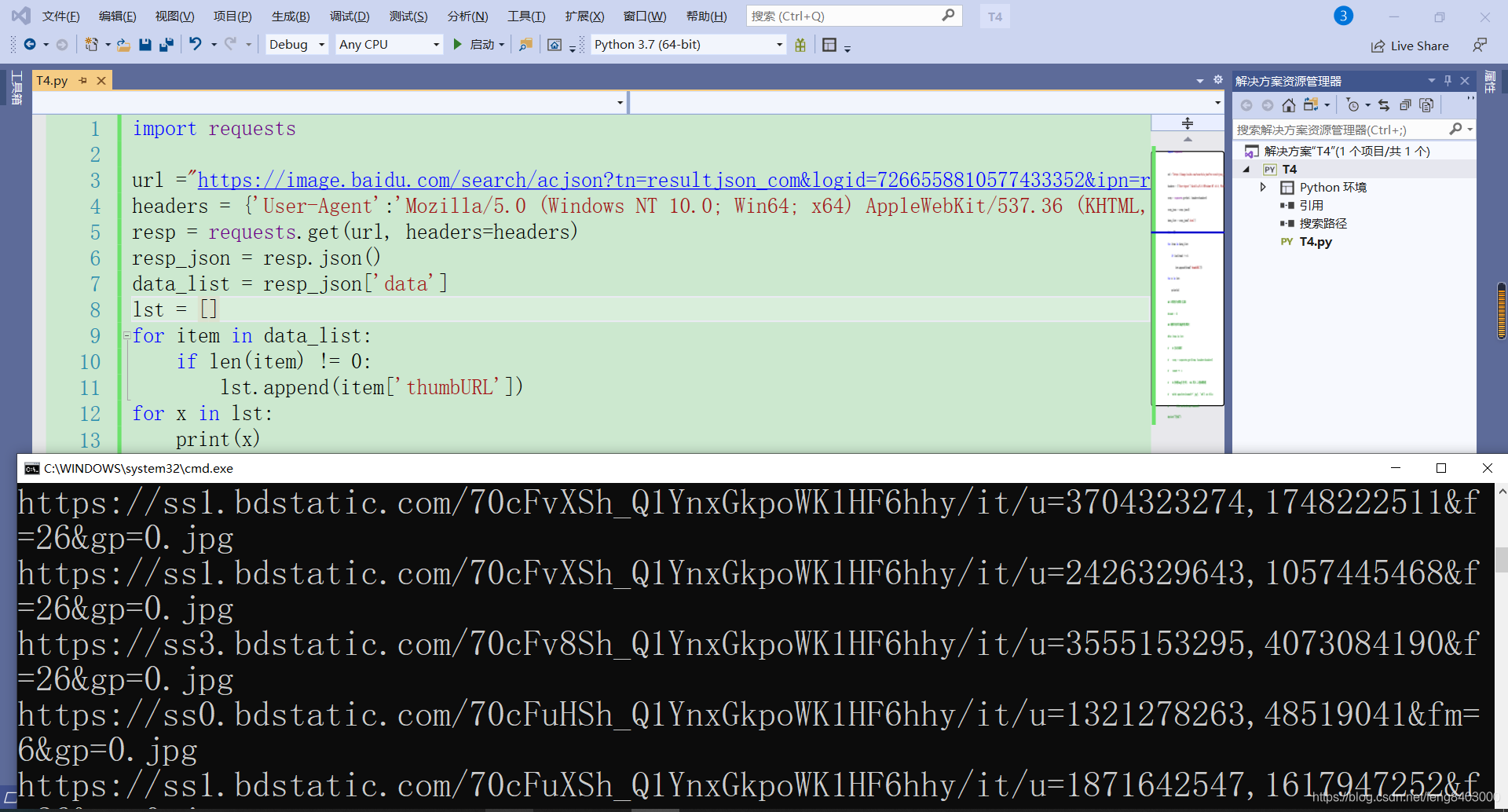
![]()
4、保存图片:
import requests
import uuid
import random
import time
url ="https://image.baidu.com/search/acjson?tn=resultjson_com&logid=7266558810577433352&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E9%98%BF%E5%87%A1%E8%BE%BE&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word=%E9%98%BF%E5%87%A1%E8%BE%BE&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=60&rn=30&gsm=3c&1613315170875="
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
resp = requests.get(url, headers=headers)
resp_json = resp.json()
data_list = resp_json['data']
lst = []
for item in data_list:
if len(item) != 0:
lst.append(item['thumbURL'])
#以下为存储过程
# 遍历列表存储所有图片
for item in lst:
# 发送请求
try:
pic= requests.get(item, timeout=100)
except requests.exceptions.ConnectionError:
print ('错误:当前图片无法下载')
continue
# uuid4为图片名称
#,创建img文件夹, wb+:写入二进制数据
file=open(str.format("{0}.jpg",uuid.uuid4()), 'wb+')
file.write(pic.content)
file.close()
#每次操作完休息1~3s
timeStop=random.randint(1,4)
time.sleep(timeStop)
print("完成")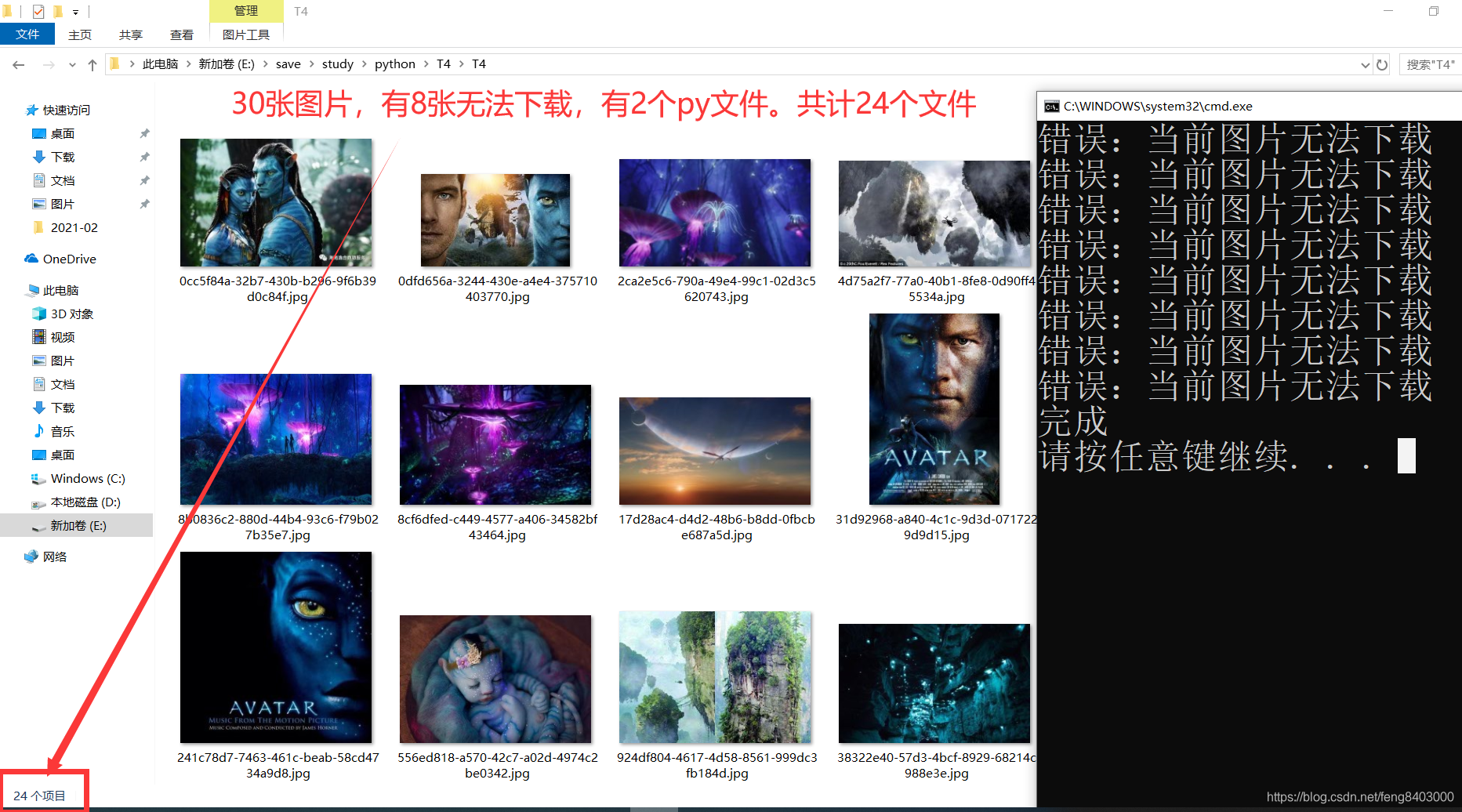
![]()
5、总结
a)、有的时候你会发现,可以直接处理json数据,很爽的哦。
b)、但是大多时候还得一点点的拆。诶,任重道远啊,慢慢练吧。
欢迎【点赞】、【评论】、【关注】、【收藏】、【打赏】,为推广知识贡献力量。
本章内容应该是全网暂时下载百度图片比较靠谱的了,如果想根据搜索词下载图片,直接改参数即可。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)