零基础学Python-爬虫-1、网络请求Requests【网络操作理论基础与实践·请认真看看理论,理论基础决定后期高度】

本套课程正式进入Python爬虫阶段,具体章节根据实际发布决定,可点击【python爬虫】分类专栏进行倒序观看:
【重点提示:请勿爬取有害他人或国家利益的内容,此课程虽可爬取互联网任意内容,但无任何收益,只为大家学习分享。】
开发环境:【Win10】
开发工具:【Visual Studio 2019】
Python版本:【3.7】
1、Python爬虫的介绍
网络爬虫(又被称为网页蜘蛛(Web Spider),网络机器人,好听点的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网(www)信息的程序或者脚本。
在浏览器中输入地址(网站地址URL:)后,向服务器发送一个请求,服务器经过解析后发送给用户浏览器结果。
爬虫就是通过分析和过滤html代码,从中获取我们想要的资源(文本、图片、音频、视频等)。
2、请求【request】与响应【response】
2.1、服务器处理请求的流程:
(1)服务器每次收到请求时,都会为这个请求开辟一个新的线程。
(2)服务器会把客户端的请求数据封装到request对象中,request就是请求数据的载体!
(3)服务器还会创建response对象,这个对象与客户端连接在一起,它可以用来向客户端发送响应。
2.2、request—封装了客户端所有的请求数据
request的功能可以分为以下几种:
(1)封装了请求头数据;
(2)封装了请求正文数据,如果是GET请求,那么就没有正文;
(3)request是一个域对象,可以把它当成Map来添加获取数据;
(4)request提供了请求转发和请求包含功能。
2.2.1、GET请求和POST请求的区别:
GET请求:
请求参数会在浏览器的地址栏中显示,所以不安全;
请求参数长度限制长度在1K之内;#面试考点,我经常问面试者这个问题
GET请求没有请求体,无法通过request.setCharacterEncoding()来设置参数的编码;
POST请求:
请求参数不会显示浏览器的地址栏,相对安全;#大厂一般请求都会是Post,包括很多read操作。
请求参数长度没有限制;
2.3、response在python中的理解
Python django中我们经常用的response有django中的 JsonResponse, HttpResponse,还有DRF中的Response
在使用的时候,经常会不知道如何什么时候选择用哪个response
下面简单记录下这三个response的区别
2.3.1、HttpResponse
它的返回格式为:HttpResponse(content=响应体, content_type=响应体数据类型, status=状态码)
1)它可以返回普通文本信息
HttpResponse("哈哈哈哈")
2)它可以像文本一样追加内容:
res = HttpResponse("哈哈哈哈")
res.write("恩,我们是一个测试段落")
3)它还可以返回图片,音频,视频等二进制文件信息
img = open(filepath,"rb")
data = img.read()
return HttpResponse(data, content_type="image/png")
2.3.2、JsonResponse
它继承自HttpResponse,它主要用于返回json格式的数据
JsonResponse(jsonData,content_type="application/json")
2.3.3、RestFramework框架封装的Response
它的返回格式为:
Response(data, status=None,template_name=None, header=None, content_type=None)
data:为python內建数据类型,DRF会使用render渲染器处理data
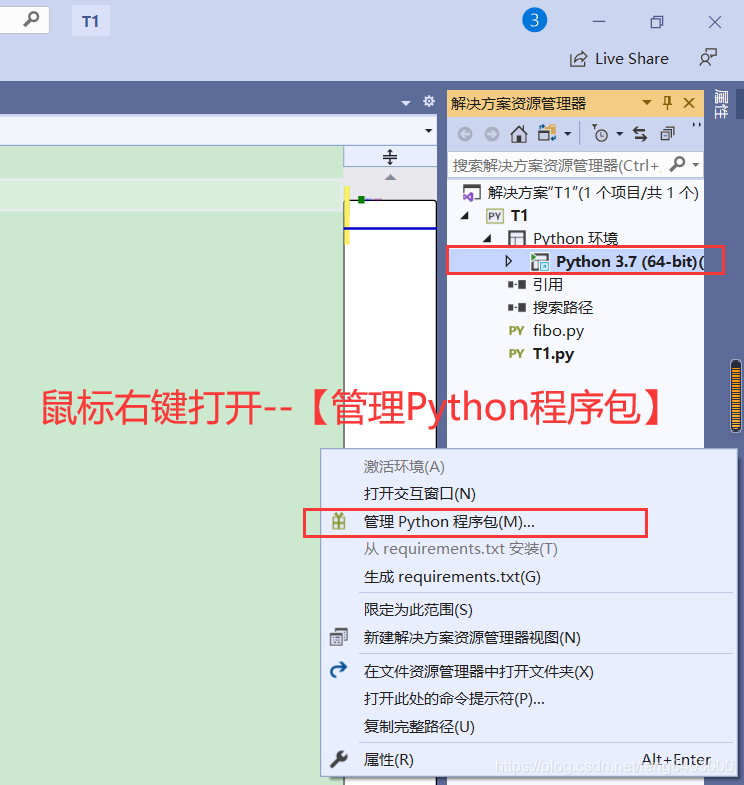
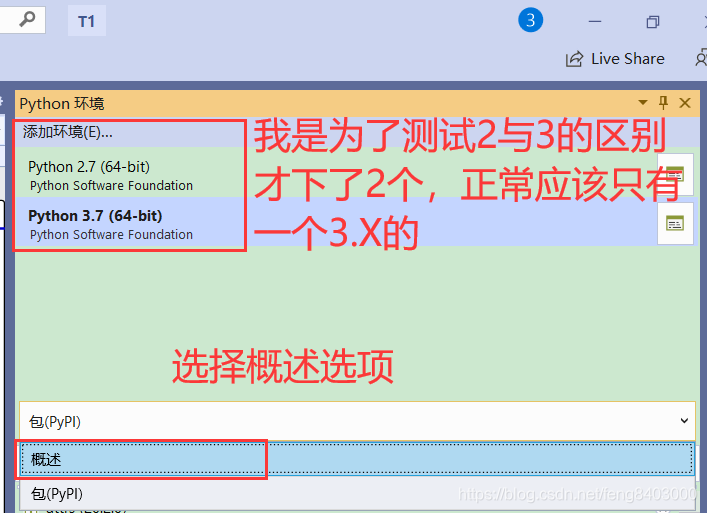
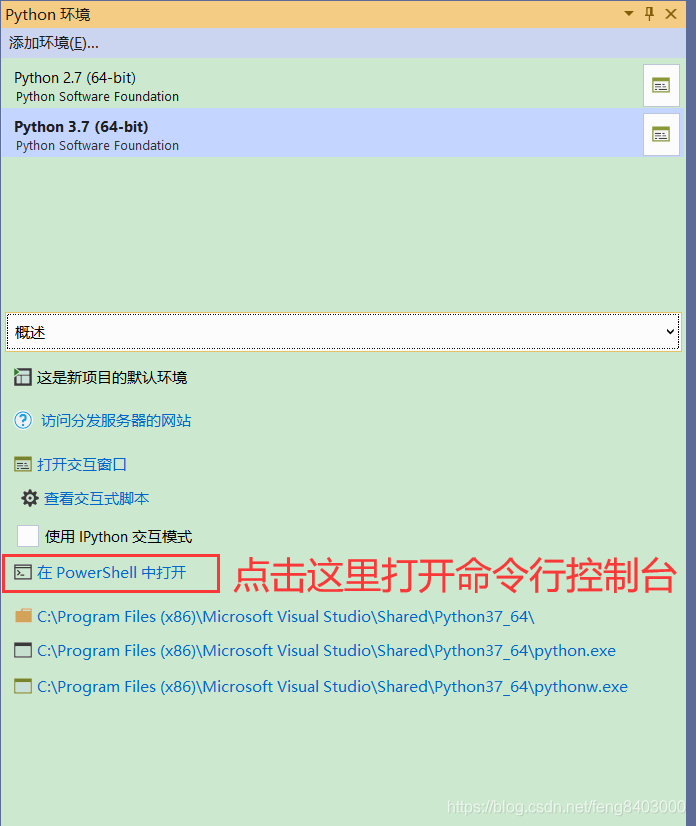
3、修改pip镜像地址为国内地址(请保存此模块)
![]()
![]()
![]()
国内镜像地址
http://pypi.douban.com/simple/ 豆瓣
http://mirrors.aliyun.com/pypi/simple/ 阿里
http://pypi.hustunique.com/simple/ 华中理工大学
http://pypi.sdutlinux.org/simple/ 山东理工大学
http://pypi.mirrors.ustc.edu.cn/simple/ 中国科学技术大学
https://pypi.tuna.tsinghua.edu.cn/simple 清华
安装命令:【赋复制粘贴即可】
pip install --index http://mirrors.aliyun.com/pypi/simple/ pandas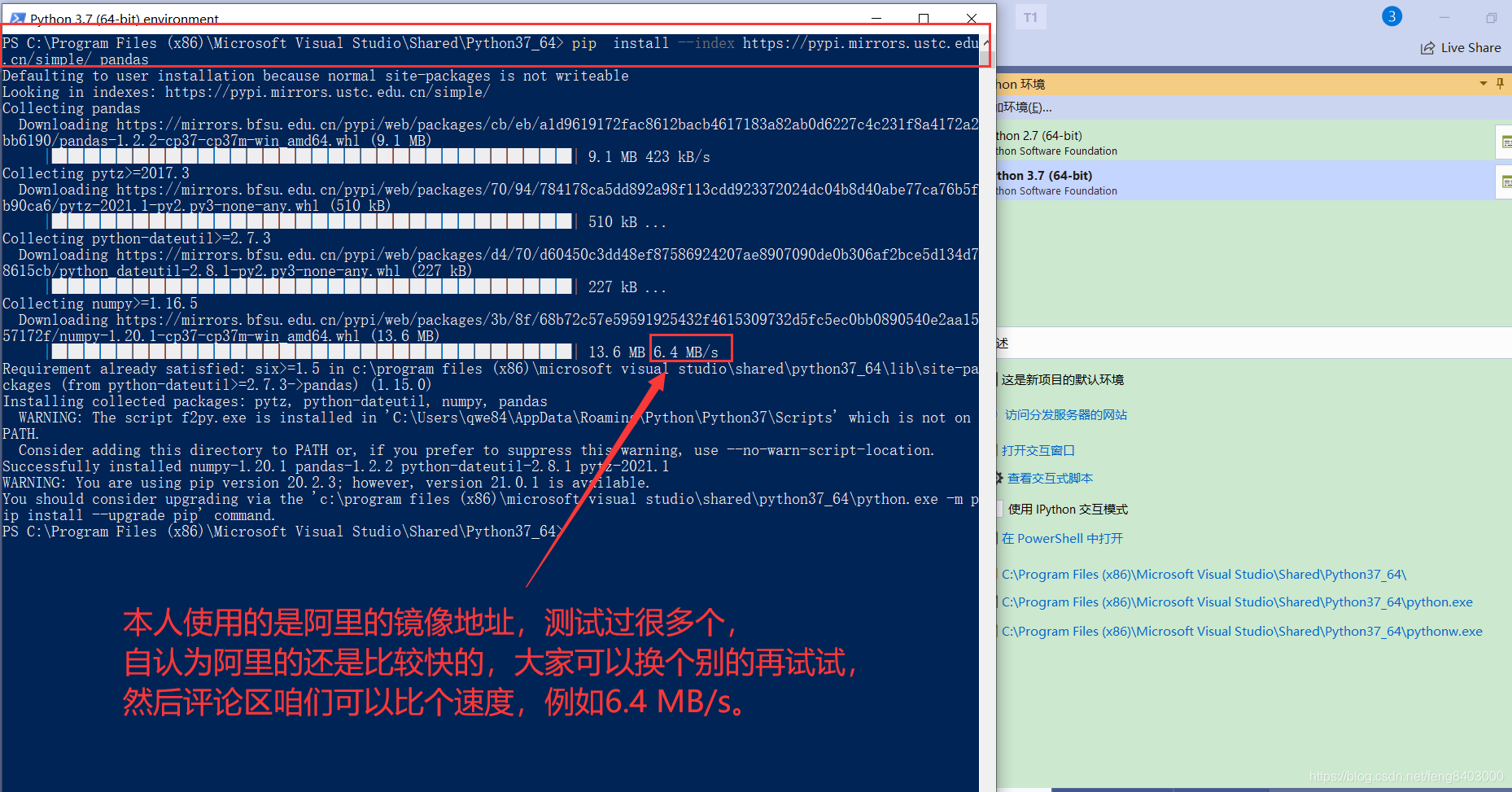
![]()
4、安装pip的requests包(注:如果pip不是最新的请直接所有pip安装最新版本即可)
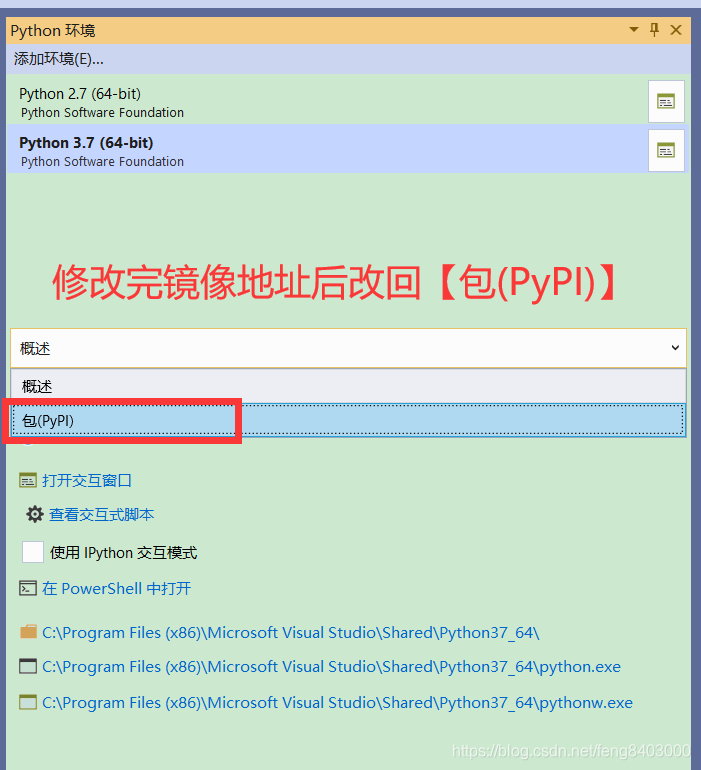
![]()
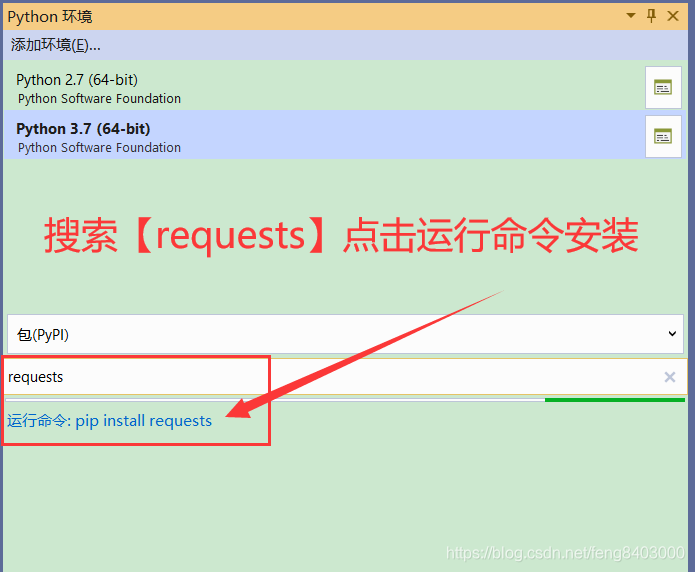
![]()
安装完成后:
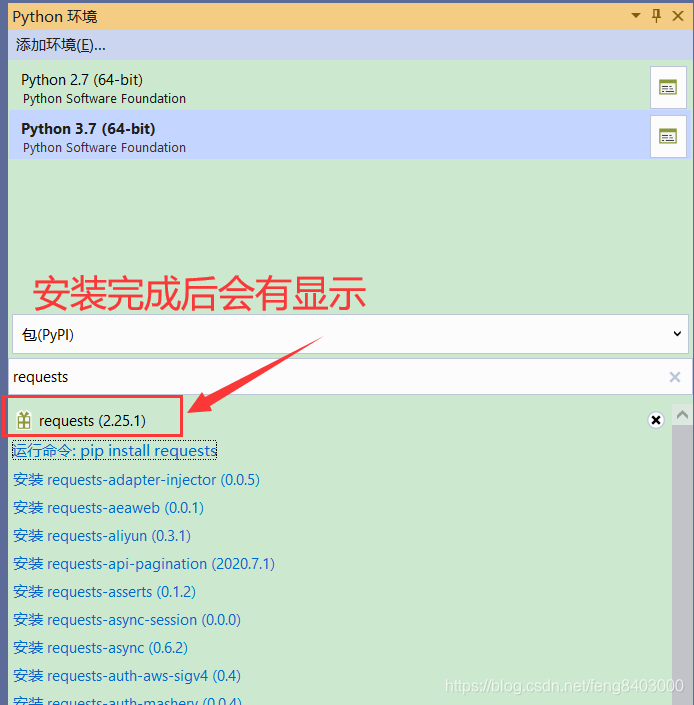
![]()
5、测试【requests】访问网址:(前提是安装了requests模块才能使用import引入)
import requests
#获取请求的响应结果【response】
response=requests.get("http://www.baidu.com")
#类型
print(type(response))
#响应状态【200为成功】
print(response.status_code)
#响应文本类型-一般都是str字符串
print(type(response.text))
#响应文本内容
print(response.text)
#<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
print(response.cookies)
#响应内容
print(response.content)
#修改响应的编码格式
print(response.content.decode("utf-8"))5.1、重点理解
response.text返回的类型是str
response.content返回的类型是bytes,可以通过decode()方法将bytes类型转为str类型
推荐使用:response.content.decode()的方式获取相应的html页面
5.2、扩展理解
-
response.text
解码类型:根据HTTP头部对响应的编码做出有根据的推测,推测的文本编码
如何修改编码方式:response.encoding = 'gbk' -
response.content
解码类型:没有指定
如何修改编码方式:response.content.decode('utf8')

![]()
6、【requests】请求方式:(测试的是阿里的手机地址查询(免费的get接口),只返回gbk编码的数据)
import requests
#获取请求的响应结果【response】
tel=int(input("请输入手机号码:\n"))
url="https://tcc.taobao.com/cc/json/mobile_tel_segment.htm?tel={0}".format(tel)
print(url)
response=requests.get(url)
print(response.text)
print(response.content.decode("gbk"))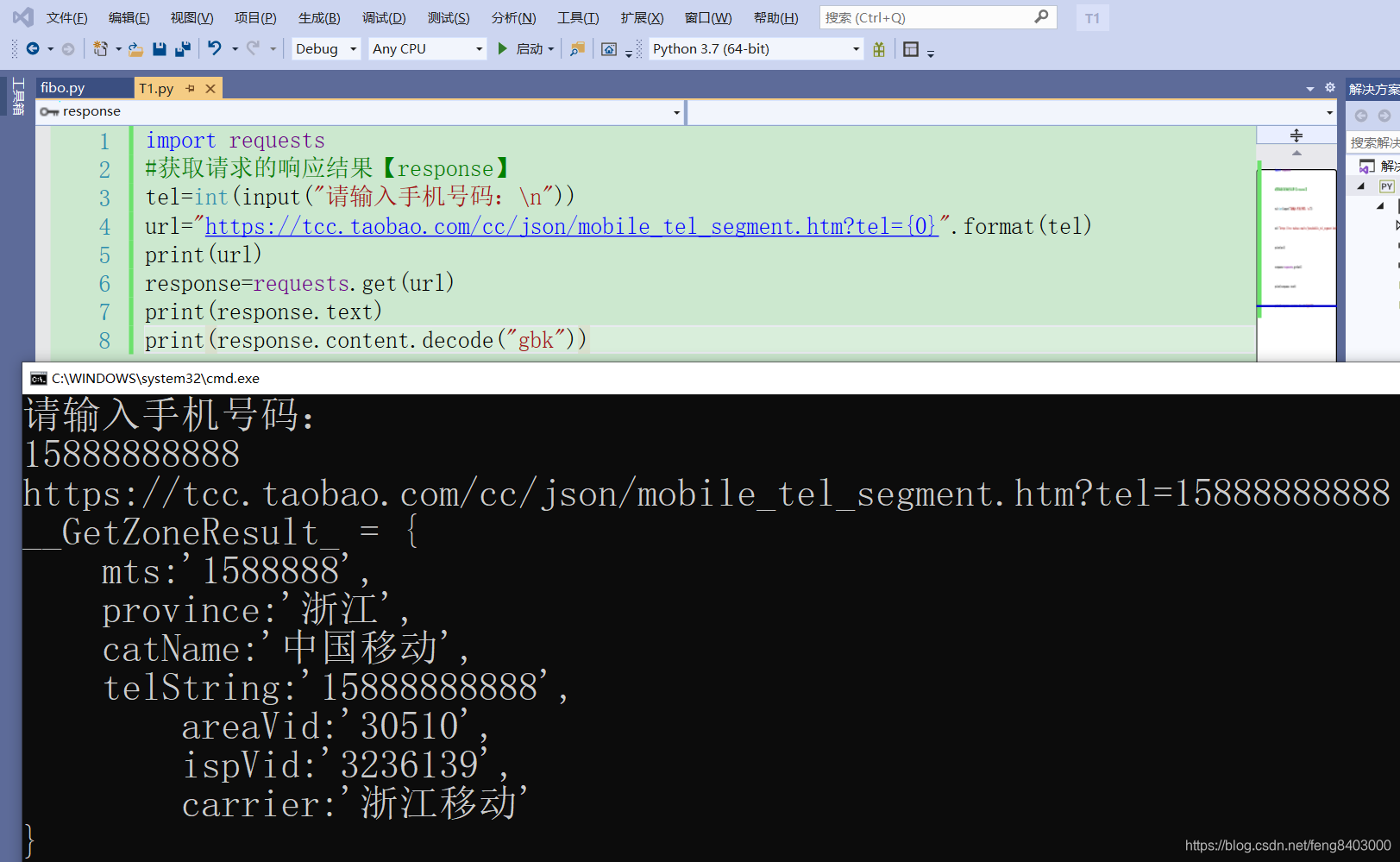
![]()
个人推荐使用【聚合数据】做自己的测试用接口,免费的每天能用100次左右,够你做测试了。有条件的可以使用自己的接口测试,我在【ASP.NET Core中详细的介绍的创建使用上线步骤】
![]()
由于未找到post请求的免费api故而写个例子做展示啊:
import requests
data = {
"name":"小龙女",
"age":16
}
response = requests.post("http://httpbin.org/post",data=data)
print(response.text) 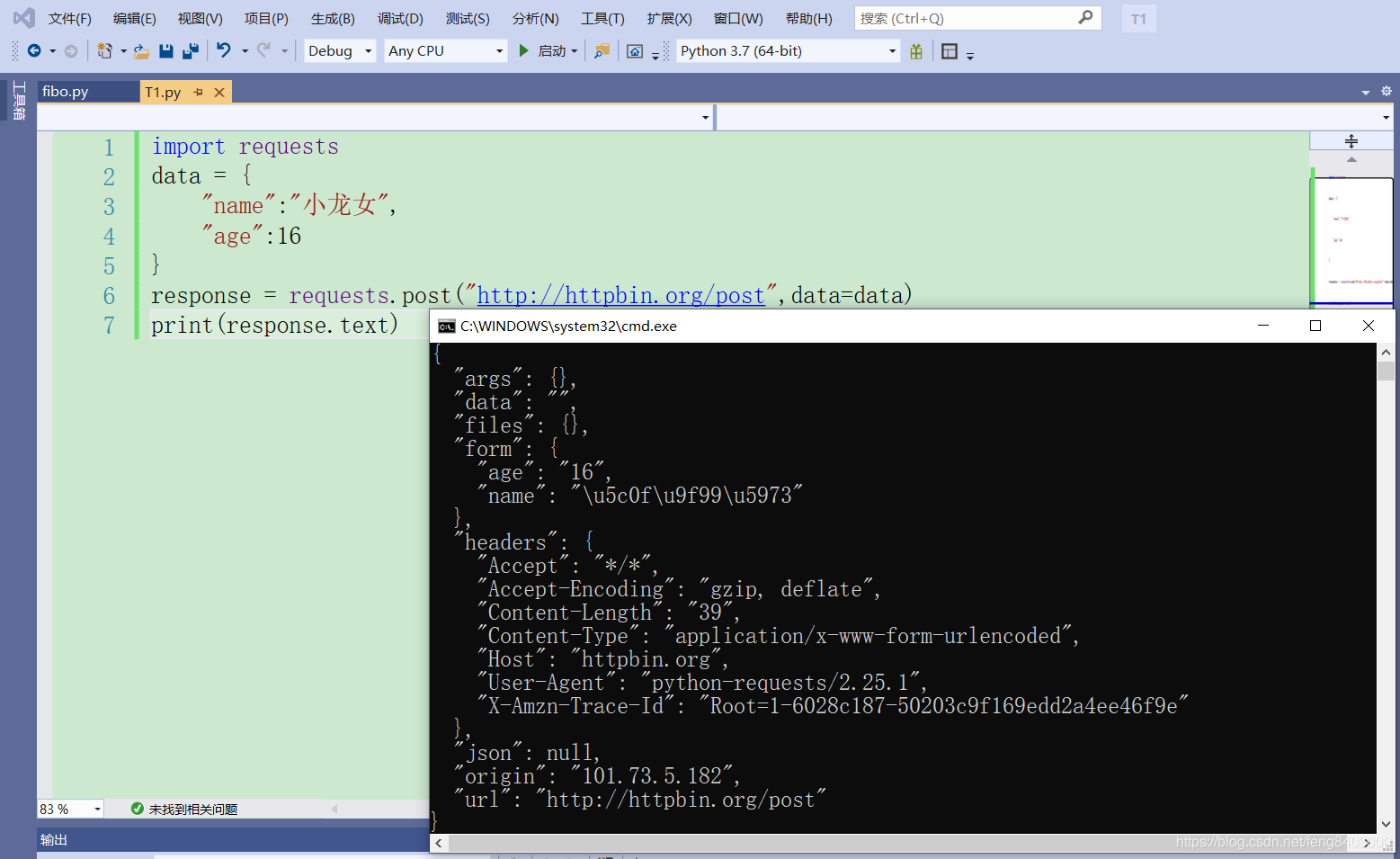
![]()
7、urllib.request与requests区别
通常而言,在我们使用python爬虫时,更建议用requests库,因为requests比urllib更为便捷,requests可以直接构造get,post请求并发起,而urllib.request只能先构造get,post请求,再发起。
8、总结:
a)、本章节主要为让大家了解网络请求的方式,这里主要是【get】与【post】请求,使用的是【requests】模块。
b)、后续所有的访问返回都会使用【requests】请大家好好练习一下这块。
欢迎【点赞】、【评论】、【关注】、【收藏】、【打赏】,为推广知识贡献力量。

- 点赞
- 收藏
- 关注作者
评论(0)