特征工程之One-Hot编码、label-encoding、自定义编码

目录
One-Hot编码
到目前为止,表示分类变量最常用的方法就是使用 one-hot 编码(one-hot-encoding)或N 取一编码(one-out-of-N encoding), 也叫虚拟变量(dummy variable)。 虚拟变量背后的思想是将一个分类变量替换为一个或多个新特征,新特征取值为 0 和 1。对于线性二分类(以及 scikit-learn 中其他所有模型)的公式而言, 0 和 1 这两个值是有意义的,我们可以像这样对每个类别引入一个新特征,从而表示任意数量的类别。
使用One-Hot编码的好处,可以忽略数值大小对模型所造成的的影响,比如说有一个特征,是性别,我们都知道性别一般只有男女之分,那么男女是一个文本的数据,需要我们用数值型的数据进行替换,这个时候就可以使用One-Hot编码,将男女自动编码。
那么有的小伙伴可能会有疑虑,为什么不直接将男编码为1,女编码为2;原因是有些模型是基于距离度量来计算的,比如支持向量机(SVM),如果自定义数值编码会对模型造成一定的数据干扰,同时也会带来一些形式问题。

代码实现
在pandas里面有一种十分简单的方法就是get_dummies函数,它可以直接转换文本类型的数据
pandas的方法
pd.get_dummies(pd.Series(list('abcaa')))

sklearn中的方法
-
from sklearn import preprocessing
-
enc = preprocessing.OneHotEncoder()
-
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]) # fit来学习编码
-
enc.transform([[0, 1, 3]]).toarray() # 进行编码
-
data : array-like,Series或DataFrame,简单点就是数据
prefix :string,字前缀,不说这么复杂的概念,就是前缀
prefix_sep : string,分隔符也就是前缀后面的一坨东西
dummy_na : bool,默认为False如果忽略False NaN,则添加一列以指示NaN。
columns : 类似列表,默认为无;要编码的DataFrame中的列名称。
sparse : bool,默认为False伪编码列是否应由SparseArray(True)或常规NumPy数组(False)支持。
drop_first : bool,默认为False是否通过删除第一级别从k分类级别获得k-1个假人。(版本0.18.0中的新功能。)
dtype: D型,默认np.uint8新列的数据类型。只允许一个dtype。
介绍了什么是One-Hot编码,下面我们来看看它的优缺点
独热编码(哑变量 dummy variable)是因为大部分算法是基于向量空间中的度量来进行计算的,为了使非偏序关系的变量取值不具有偏序性,并且到圆点是等距的。
使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。将离散型特征使用one-hot编码,会让特征之间的距离计算更加合理。
离散特征进行one-hot编码后,编码后的特征,其实每一维度的特征都可以看做是连续的特征。就可以跟对连续型特征的归一化方法一样,对每一维特征进行归一化。比如归一化到[-1,1]或归一化到均值为0,方差为1。
为什么特征向量要映射到欧式空间?
将离散特征通过one-hot编码映射到欧式空间,是因为,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。
One-Hot编码优缺点
优点:独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用,它的值只有0和1,不同的类型存储在垂直的空间。
缺点:当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA来减少维度。而且one hot encoding+PCA这种组合在实际中也非常有用。
One-Hot编码使用场景
独热编码用来解决类别型数据的离散值问题
将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码。
有些基于树的算法在处理变量时,并不是基于向量空间度量,数值只是个类别符号,即没有偏序关系,所以不用进行独热编码。 Tree Model不太需要one-hot编码: 对于决策树来说,one-hot的本质是增加树的深度。
归一化适用场景
基于参数的模型或基于距离的模型,都是要进行特征的归一化。
基于树的方法是不需要进行特征的归一化,例如随机森林,bagging 和 boosting等。
简而言之,对于树模型,一般都不需要做One-Hot编码和归一化
one-hot可以解决线性可分问题 但是比不上label econding,下面我们就介绍一种新的编码方式
label encoding
label encoding就是序列化标签编码,如果是无序变量,则两种方法在很多情况下差别不大,但是在实际使用中label encoding的效果一般要比one hot encoding要好。这是因为在树模型中,label encoding至少可以完成one hot encoding同样的效果,而多出来的那部分信息则是label encoding后的数值本身是有排序作用的,它可以起到类别变量合并的效果,这种效果在类别较多的变量中更明显。
这种编码方式在实际的应用场景中比较的多,一般在基于距离度量的情况下,这种编码比较的受欢迎,另外就是需要注意的是有序变量,如果不是有序变量,那么特征工程出来的数据,反而会扰动我们的模型的准确性和评估值。

举一个简单的例子
假如现在提供的是学业数据,需要你来预测它的购房能力,如果此时有一列数据已经排序好,并且该数据列是一种至于学历排名的,依次是小学、初中、大专、高中、大学、硕士、博士,那么基于这样的数据采用label encoding 编码最合适不过了,因为学历对经济能力有一定的辅助作用,一般高学历的人后期的经济水平肯定比低学历的好,那么购房能力也就相应的强。
代码实现
-
from sklearn.preprocessing import LabelEncoder,OneHotEncoder,Binarizer
-
# 根据需要编码的数据列索引进行编码,文本数据
-
for x in [3,4,5,7,8,9,10,11,12]:
-
le=LabelEncoder()
-
data_test_whw.iloc[:,x]=le.fit_transform(data_test_whw.iloc[:,x])
这里需要提前获取得知到,文本数据也就是需要编码的列的索引
-
#dType = String的做labelEncoder
-
labelEncoder = LabelEncoder()
-
for index,dtype in enumerate(X.dtypes) :
-
if dtype=="object" :
-
X.iloc[:,index] = labelEncoder.fit_transform(X.iloc[:,index])
这种自动识别文本列数据进行编码的方法,更加的智能(推荐)
One-Hot与label encoding对比
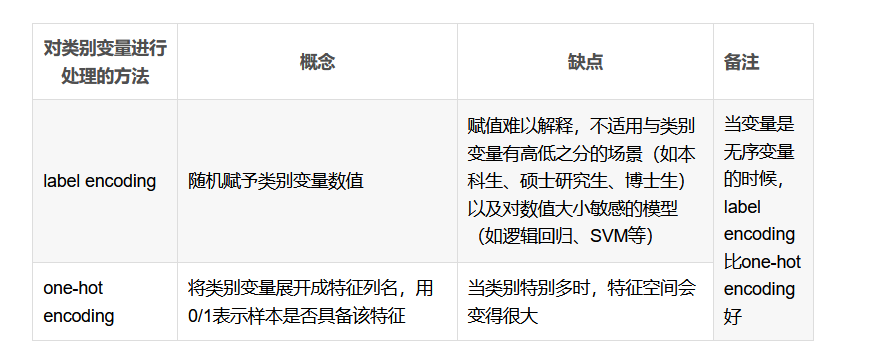
至于如何真正的去编码和实现,需要自己反复的去斟酌,并且结合模型的适用度,那么当我们需要有序变量,而且数据的编码大小对模型的扰动会比较的大比如我们使用SVM,逻辑回归,等基于距离度量的模型,我们应该怎么做?
这个时候我们就可以使用自定义编码的方式,按照自己的编码思想可以将文本编码为数值,将连续的数值,变化为离散的数值,在一些模型中这样的好处可谓是如虎添翼。
自定义编码
说到自定义编码的方式,那么就需要探究python的语法,和基础的一些代码了,这也是为什么前期需要学好Python基础语法的原因。
利用字典编码
-
# dicts={"Male":0,"Female":1}
-
# df[["性别"]]=df["性别"].map(dicts)
自定义函数
-
def age_encoder(x):
-
x=int(x)
-
if x<10:
-
return 0
-
elif 10<=x<=20:
-
return 1
-
elif 20<x<=30:
-
return 2
-
elif 30<x<=40:
-
return 3
-
elif 40<x<=50:
-
return 4
-
elif 50<x<=60:
-
return 5
-
elif 60<x<=70:
-
return 6
-
elif 70<x<=80:
-
return 7
-
elif 80<x<=90:
-
return 8
-
else:
-
return 0
-
# data["Age"]=data[["Age"]].apply(age_encoder,axis=1)
-
# data["Age"].unique().tolist()
这样你就可以自己根据数据的特性去编码这些文本数据以及连续数据离散化
每文一语
如果希望不可以破灭,那么留给你的只有坚持
文章来源: wxw-123.blog.csdn.net,作者:王小王-123,版权归原作者所有,如需转载,请联系作者。
原文链接:wxw-123.blog.csdn.net/article/details/122706251

- 点赞
- 收藏
- 关注作者
评论(0)