05 RDD

大家好,我是一条~
5小时推开Spark的大门,最后一小时,聊聊提了这么久的RDD。
话不多说,开干!
什么是RDD
Spark为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。分别是:
-
RDD : 弹性分布式数据集
-
累加器:分布式共享只写变量
-
广播变量:分布式共享只读变量
当前的很多框架对迭代式算法场景与交互性数据挖掘场景的处理性能非常差, 这个是RDD的提出的动机。
接下来我们重点看看RDD是如何在数据处理中使用的。
它代表一个不可变、只读的,被分区的数据集。操作 RDD 就像操作本地集合一样,有很多的方法可以调用,使用方便,而无需关心底层的调度细节。
五大特性
RDD总共有五个特征,三个基本特征,两个可选特征。
- 分区(partition):有一个数据分片列表,可以将数据进行划分,切分后的数据能够进行并行计算,是数据集的原子组成部分。
- 函数(compute):对于每一个分片都会有一个函数去迭代/计算执行它。
- 依赖(dependency):每一个RDD对父RDD有依赖关系,源RDD没有依赖,通过依赖关系建立来记录它们之间的关系。
- 优先位置(可选):每一个分片会优先计算位置(prefered location)。即要执行任务在哪几台机器上好一点(数据本地性)。
- 分区策略(可选):对于key-value的RDD可以告诉它们如何进行分片。可以通过repartition函数进行指定。
执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑),执行时,需要将计算资源和计算模型进行协调和整合。
Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
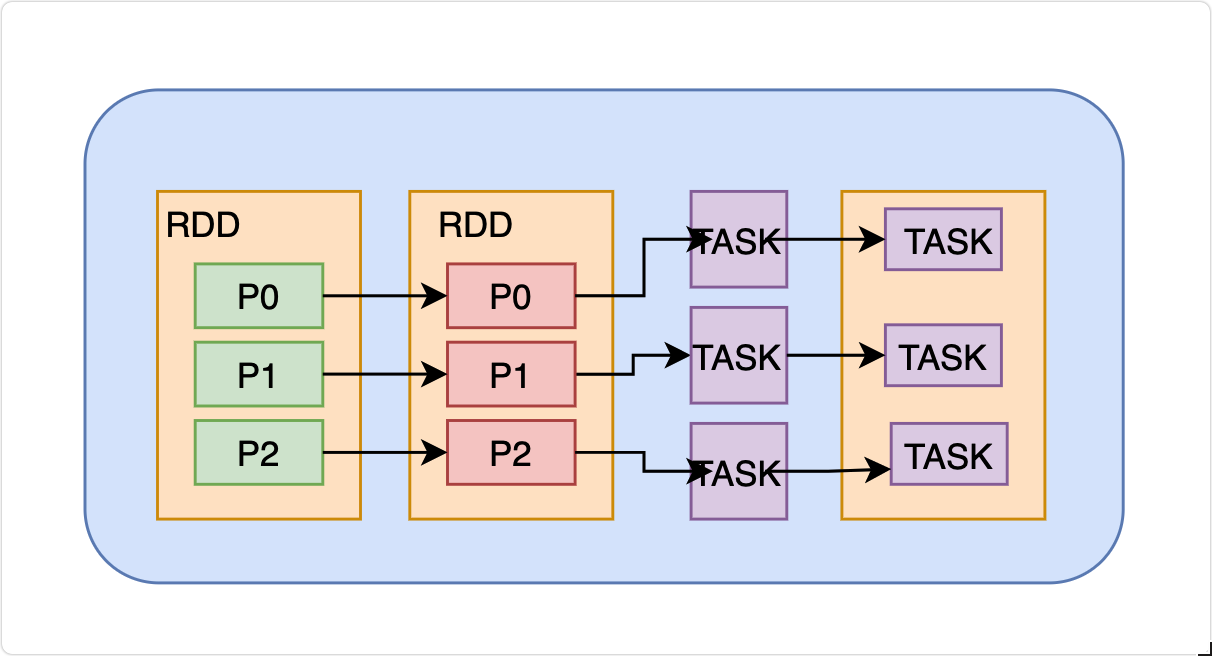
创建RDD
在 Spark 中创建 RDD 的创建方式可以分为四种。
打开IDEA,创建一个Scala Class。
1.从内存中创建RDD
Spark 主要提供了两个方法:parallelize 和 makeRDD
import org.apache.spark.{SparkConf, SparkContext}
object Rdd {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sparkContext = new SparkContext(sparkConf)
val rdd1 = sparkContext.parallelize(
List(1,2,3,4)
)
val rdd2 = sparkContext.makeRDD(
List(1,2,3,4)
)
rdd1.collect().foreach(println)
rdd2.collect().foreach(println)
sparkContext.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
输出结果

从底层代码实现来讲,makeRDD方法其实就是parallelize方法。
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.从外部存储(文件)创建 RDD
由外部存储系统的数据集创建 RDD 包括:本地的文件系统,所有 Hadoop 支持的数据集,比如 HDFS、HBase 等。
和第二节提到的读取文件,统计有多少行是一样的。如果Windows系统执行如下代码出现问题,可回顾一下第二节去Spark Shell创建。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Rdd {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("spark")
val sparkContext = new SparkContext(sparkConf)
val fileRDD = sparkContext.textFile("src/main/java/test.txt")
fileRDD.collect().foreach(println)
sparkContext.stop()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出结果

3.从其他RDD创建
主要是通过一个 RDD 运算完后,再产生新的 RDD。
4.直接创建RDD
使用 new 的方式直接构造 RDD,一般由 Spark 框架自身使用。
最后
恭喜坚持到这里的各位同学,通过5天约5个小时的学习,同学们对Spark有个简单的了解,还完成了大数据入门经典案例——WordCount。
但是,想要学好Spark仍然任重而道远,送给同学们我本人很喜欢的一句话:
道阻且长,行则将至。
流水不争先,争的是川流不息。
感谢各位5天的支持,在此谢过!最后,祝同学们新年快乐!
文章来源: blog.csdn.net,作者:一条coding,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/skylibiao/article/details/122725661

- 点赞
- 收藏
- 关注作者
评论(0)