深入理解Python内存管理与垃圾回收

面试官:听说你学Python?那你给我讲讲Python如何进行内存管理?
我:???内存管理不太清楚额。。。
面试官:那你知道Python垃圾回收吗?
我:(尴尬一下后,还好我看到过相关博客)Python垃圾回收引用计数为主、标记清除和分代回收为主。
面试官:那你仔细讲讲这三种垃圾回收技术?
我:卒。。。

先看看内存管理
内存的管理简单来说:分配(malloc)+回收(free)。
再我们看文章之前,先思考一下:如果是你设计,会怎么进行内存管理?答:好,不会设计(笔主也不会),会的大佬请绕过。我们一起了解看看Python是怎么设计的。为了提高效率就是:
-
如何高效分配?
-
如何有效回收?
什么是内存
买电脑的配置“4G + 500G / 1T”,这里的4G就是指电脑的内存容量,而电脑的硬盘 500G / 1T。
内存(Memory,全名指内部存储器),自然就会想到外存,他们都硬件设备。
内存是计算机中重要的部件之一,它是外存与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大。
内存就像一本空白的书
首先,您可以将计算机的存储空间比作一本空白的短篇小说。页面上还没有任何内容。最终,会有不同的作者出现。每个作者都需要一些空间来写他们的故事。
由于不允许彼此书写,因此必须注意他们能书写的页面。开始书写之前,请先咨询书籍管理员。然后,管理员决定允许他们在书中写什么。
如果这书已经存在很长时间了,因此其中的许多故事都不再适用。当没有人阅读或引用故事时,它们将被删除以为新故事腾出空间。
本质上,计算机内存就像一本空书。实际上,调用固定长度的连续内存页面块是很常见的,因此这种类比非常适用。
作者就像需要将数据存储在内存中的不同应用程序或进程。决定作者在书中书写位置的管理员就像是各种存储器管理的角色,删除旧故事为新故事腾出空间的人是垃圾收集者(garbage collector)。
以上类比出自此文
内存管理:从硬件到软件
为什么4G内存的电脑可以高效的分析上G的数据,而且程序可以一直跑下去。
在这4G内存的背后,Python都帮助我们做了什么?
内存管理是应用程序读取和写入数据的过程。内存管理器确定将应用程序数据放置在何处。
由于内存有限,类比书中的页面一样,管理员必须找到一些可用空间并将其提供给应用程序。提供内存的过程通常称为内存分配。
其实如果我们了解内存管理机制,以更快、更好的方式解决问题。
看完本篇文章,带您稍微了解Python内存管理的设计哲学。
对象管理
可能我们听过,Python鼎鼎有名的那句“一切皆对象”。是的,在Python中数字是对象,字符串是对象,任何事物都是对象,Cpython下,而Python对象实现的核心就是一个结构体--PyObject。
typedef struct_object{
int ob_refcnt;
struct_typeobject *ob_type;
}PyObject;
PyObject是每个对象必有的内容,可以说是Python中所有对象的祖父,仅包含两件事:
-
ob_refcnt:引用计数(reference count)
-
ob_type:指向另一种类型的指针(pointer to another type)
所以,所以CPython是用C编写的,它解释了Python字节码。这与内存管理有什么关系?
好吧,C中的CPython代码中存在内存管理算法和结构。要了解Python的内存管理,您必须对CPython本身有一个基本的了解。其他我们也不深究,感兴趣的同学自行了解。
CPython的内存管理
注:这一块内容在网上找了很多内容,看了好久也没懂,自己太菜。唯一看懂的就是 Alexander VanTol的文章相关部分内容,搬运过来哦放在此处,有删减,有兴趣的同学建议看原文。
下图的深灰色框现在归Python进程所有。
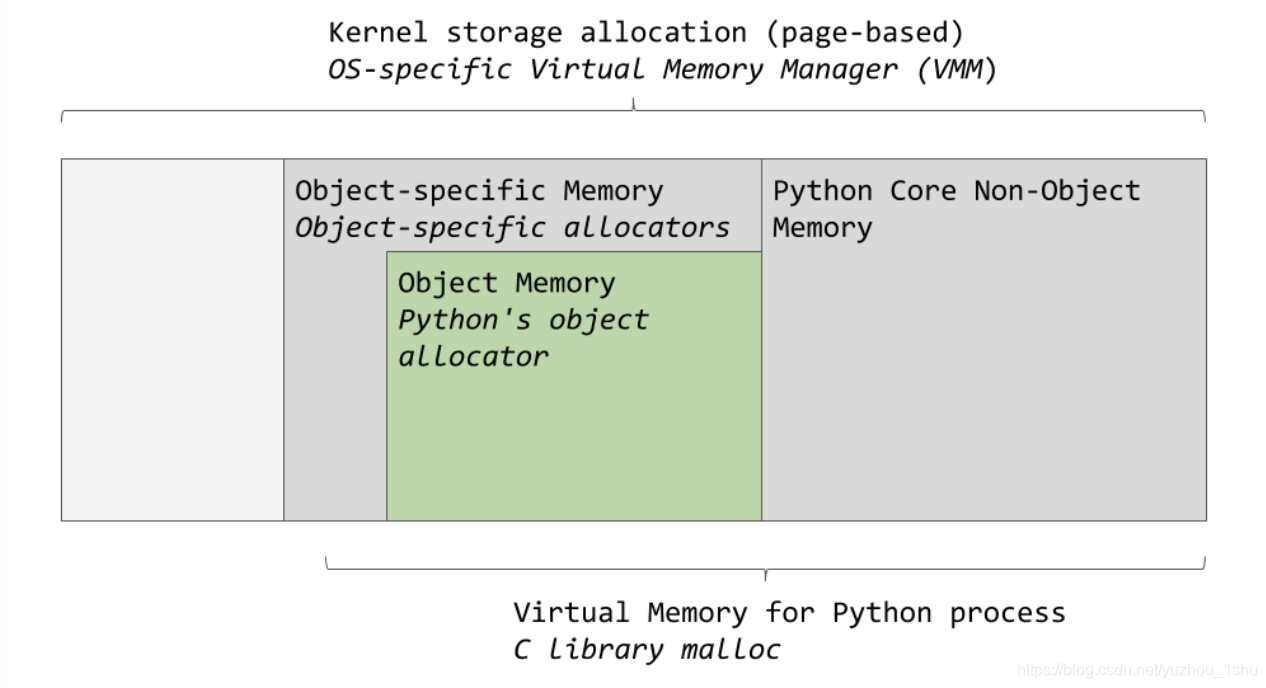
Python将部分内存用于内部使用和非对象内存。另一部分专用于对象存储(您的int,dict等)。请注意,这已被简化。如果您需要全貌,则可以看CPython源代码,所有这些内存管理都在其中进行。
CPython有一个对象分配器,负责在对象内存区域内分配内存。这个对象分配器是大多数魔术发生的地方。每当新对象需要分配或删除空间时,都会调用该方法。
通常,为list和int等Python对象添加和删除数据一次不会涉及太多数据。因此,分配器的设计已调整为可以一次处理少量数据。它还尝试在绝对需要之前不分配内存。
现在,我们来看一下CPython的内存分配策略。首先,我们将讨论这三个主要部分以及它们之间的关系。
Python的内存分配器
内存结构
在Python中,当要分配内存空间时,不单纯使用 malloc/free,而是在其基础上堆放3个独立的分层,有效率地进行分配。

第 0 层往下是 OS 的功能。第 -2 层是隐含和机器的物理性相关联的部分,OS 的虚拟内 存管理器负责这部分功能。第 -1 层是与机器实际进行交互的部分,OS 会执行这部分功能。 因为这部分的知识已经超出了本书的范围,我们就不额外加以说明了。在第 3 层到第 0 层调用了一些具有代表性的函数,其调用图如下。

第0层 通用的基础分配器
以 Linux 为例,第 0 层指的就是 glibc 的 malloc() 这样的分配器,是对 Linux 等 OS 申 请内存的部分。
Python 中并不是在生成所有对象时都调用 malloc(),而是根据要分配的内存大小来改 变分配的方法。申请的内存大小如果大于 256 字节,就老实地调用 malloc();如果小于等 于 256 字节,就要轮到第 1 层和第 2 层出场了。
更细致的过程:垃圾回收机制的算法与实现
第1层 Python低级内存分配器
Python 中使用的对象基本上都小于等于 256 字节,并且净是一些马上就会被废弃的对象。请看下面的例子。
for x in range(100):
print(x)
上述 Python 脚本是把从 0 到 99 的非负整数 A 转化成字符串并输出的程序。这个程序会大量使用一次性的小字符串。
在这种情况下,如果逐次查询第 0 层的分配器,就会发生频繁调用 malloc() 和 free() 的情况,这样一来效率就会降低。
因此,在分配非常小的对象时,Python 内部会采用特殊的处理。实际执行这项处理的就是第 1 层和第 2 层的内存分配器。
当需要分配小于等于 256 字节的对象时,就利用第 1 层的内存分配器。在这一层会事先 从第 0 层开始迅速保留内存空间,将其蓄积起来。第 1 层的作用就是管理这部分蓄积的空间。
第1层处理的信息的内存结构
根据所管理的内存空间的作用和大小的不同,我们称最小 的单位为 block,最终返回给申请者的就是这个 block 的地址。比 block 大的单位的是 pool, pool 内部包含 block。pool 再往上叫作 arena。
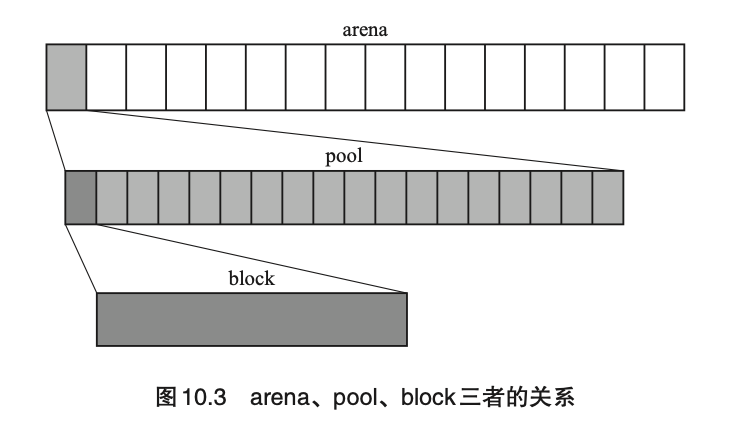
也就是说 arena > pool > block,感觉很像俄罗斯套娃吧。为了避免频繁调用 malloc() 和 free(),第 0 层的分配器会以最大的单位 arena 来保留 内存。pool 是用于有效管理空的 block 的单位。arena 这个词有“竞技场”的意思。大家可以理解成竞技场里有很多个 pool,pool 里面漂 浮着很多个 block,这样或许更容易理解一些。
arena
Arenas是最大的内存块,并在内存中的页面边界上对齐。页面边界是操作系统使用的固定长度连续内存块的边缘。Python假设系统的页面大小为256 KB。
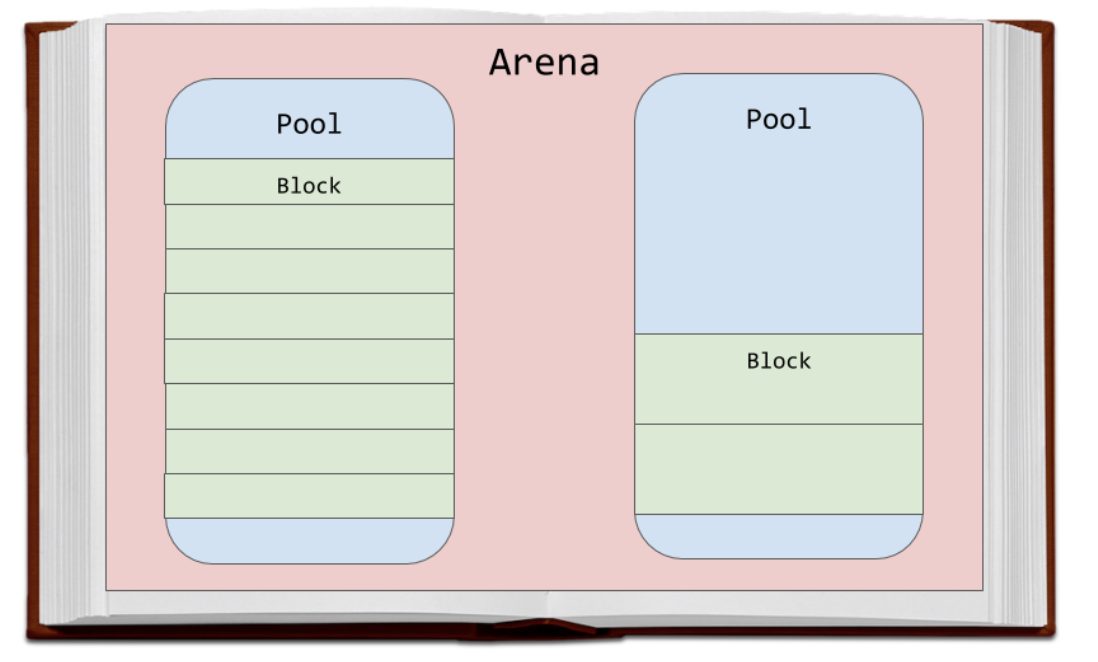
Arenas内有内存池,池是一个虚拟内存页(4 KB)。这些就像我们书中类比的页面。这些池被分成较小的内存块。
给定池中的所有块均具有相同的“大小等级”。给定一定数量的请求数据,大小类定义特定的块大小。下图直接取自源代码注释:
这一点可以看Pymalloc
-
针对小对象(<= 512 bytes),Pymalloc会在内存池中申请内存空间
-
> 512bytes,则会PyMem_RawMalloc()和PyMem_RawRealloc()来申请新的内存空间
例如,如果请求42个字节,则将数据放入48字节大小的块中。
pool
arena 内部各个 pool 的大小固定在 4K 字节。因为几乎对所有 OS 而言,其虚拟内存的页 面大小都是 4K 字节,所以我们也相应地把 pool 的大小设定为 4K 字节。
第1层总结
第 1 层的任务可以用一句话来总结,那就是“管理 arena”。
第2层 Python对象分配器
第 2 层的分配器负责管理 pool 内的 block。这一层实际上是将 block 的开头地址返回给申请者,并释放 block 等。 那么我们来看看这一层是如何管理 block 的吧。
block
pool 被分割成一个个的 block。我们在 Python 中生成对象时,最终都会被分配这个 block (在要求大小不大于 256 字节的情况下)。以 block 为单位来划分,这是从 pool 初始化时就决定好的。这是因为我们一开始利用 pool 的时候就决定了“这是供 8 字节的 block 使用的 pool”。pool 内被 block 完全填满了,那么 pool 是怎么进行 block 的状态管理的呢?block 只有以下三种状态。
-
已经分配
-
使用完毕
-
未使用
第3层 对象特有的分配器
对象有列表和元组等多种多样的型,在生成它们的时候要使用各自特有的分配器。
分配器的总结
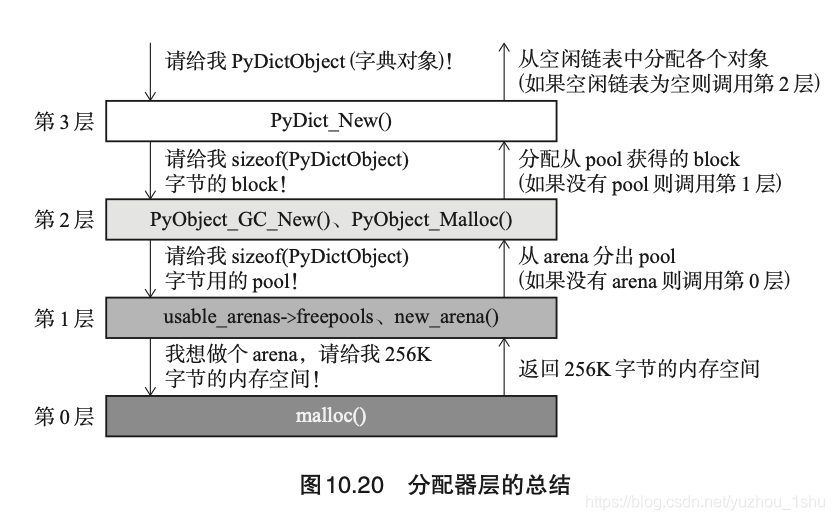
赋值语句内存分析
我们可以通过使用id()函数来查看某个对象的内存地址,每个人的电脑内存地址不一样。
a = 1
id(a) # Output: 4566652048
b = 2
id(b) # Output: 4566652080
c = 8
id(c) # Output: 4566652272
d = 8
id(d) # Output: 4566652272
使用 ==来查看对象的值是否相等,is判断对象是否是同一个对象
c == d # Output: True
c is d # Output: True
e = 888888888
id(e) # Output: 4569828784
f = 888888888
id(f) # Output: 4569828880
e == f # Output: True
e is f # Output: False
解释:我们可以看到,
-
c == d输出 True 和c is d也输出True,这是因为,对一个小一点的int变量赋值,Python在内存池(Pool)中分配给c和d同一块内存地址, -
而
e == f为 True,值相同;e is f输出 False,并不少同一个对象。
这是因为Python内存池中分配空间,赋予对象的类别并赋予其初始的值。从-5到256这些小的整数,在Python脚本中使用的非常频繁,又因为他们是不可更改的,因此只创建一次,重复使用就可以了。
e 和 f数字比较大,所以只能重新分配地址来。其实-5到256之间的数字,Python都已经给我安排好了。
>>> i = 256
>>> j = 256
>>> i is j
True
>>> i = 257
>>> j = 257
>>> i is j
False
>>> i = -5
>>> j = -5
>>> i is j
True
>>> i = -6
>>> j = -6
>>> i is j
False
Java 也有这样的机制 缓存范围是 -128 ~ 127** Cache to support the object identity semantics of autoboxing for values between*** -128 and 127 (inclusive) as required by JLS.*
接着,看对象的内存分析:
li1 = []
li2 = []
li1 == li2 # Output: True
li1 is li2 # Output: False
x = 1
y = x
id(x) # Output: 4566652048
id(y) # Output: 4566652048
y = 2
id(y) # Output: 4566652080
x == y # Output: False
x is y # Output: False
再来看看垃圾回收

垃圾回收机制
来看一下Python中的垃圾回收技术:
-
引用计数为主
-
标记清除和分代回收为辅
如果一个对象的引用计数为0,Python解释器就会回收这个对象的内存,但引用计数的缺点是不能解决循环引用的问题,所以我们需要标记清除和分代回收。
什么是引用计数
-
每个对象都有存有指向该对象的引用总数
-
查看某个对象的引用计数
sys.getrefcount() -
可以使用del关键字删除某个引用
import sys
l = []
print(sys.getrefcount(l)) # Output: 2
l2 = l
l3 = l
l4 = l3
print(sys.getrefcount(l)) # Output: 5
del l2
print(sys.getrefcount(l)) # Output: 4
i = 1
print(sys.getrefcount(i)) # Output: 140
a = i
print(sys.getrefcount(i)) # Output: 141
当对象的引用计数达到零时,解释器会暂停,来取消分配它以及仅可从该对象访问的所有对象。即满足引用计数为0的时候,会启动垃圾回收。
但是引用计数不能解决循环引用的问题,就如下的代码不停跑就能把电脑内存跑满:
>>> a = []
>>> b = []
>>> while True:
... a.append(b)
... b.append(a)
...
[1] 31962 killed python
标记清除
标记清除算法作为Python的辅助垃圾收集技术主要处理的是一些容器对象,比如list、dict、tuple,instance等,因为对于字符串、数值对象是不可能造成循环引用问题。标记清除和分代回收就是为了解决循环引用而生的。
它分为两个阶段:第一阶段是标记阶段,GC会把所有的活动对象打上标记,第二阶段是把那些没有标记的对象非活动对象进行回收。
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。
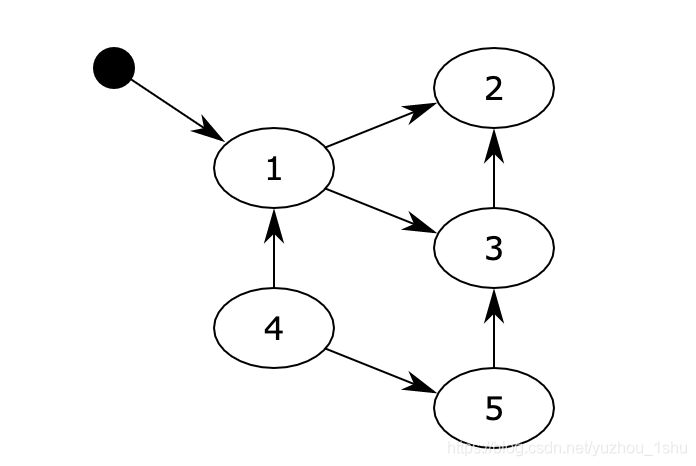
在上图中,可以从程序变量直接访问块1,并且可以间接访问块2和3。程序无法访问块4和5。第一步将标记块1,并记住块2和3以供稍后处理。第二步将标记块2,第三步将标记块3,但不记得块2,因为它已被标记。扫描阶段将忽略块1,2和3,因为它们已被标记,但会回收块4和5。
标记清除算法作为Python的辅助垃圾收集技术,主要处理的是一些容器对象,比如list、dict、tuple等,因为对于字符串、数值对象是不可能造成循环引用问题。
Python使用一个双向链表将这些容器对象组织起来。不过,这种简单粗暴的标记清除算法也有明显的缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
分代回收(自动)
分代回收是建立在标记清除技术基础之上的,是一种以空间换时间的操作方式。
-
Python将所有的对象分为0,1,2 三代
-
所有的新建的对象都是0代对象
-
当某一代对象经历过垃圾回收,依然存活,那么它就被归入下一代对象。
同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象。
Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。
当两者的差值高于某个阈值时,垃圾回收才会启动
-
查看阈值gc.get_threshold()
import gc
print(gc.get_threshold()) # Output: (700, 10, 10)
get_threshold()返回的(700, 10, 10)返回的两个10。也就是说,每10次0代垃圾回收,会配合1次1代的垃圾回收;而每10次1代的垃圾回收,才会有1次的2代垃圾回收。理论上,存活时间久的对象,使用的越多,越不容易被回收,这也是分代回收设计的思想。
手动回收
具体参考gc模块。
-
gc.collect()手动回收
-
objgraph模块中的count()记录当前类产生的实例对象的个数
import gc
result = gc.collect()
print(result)
import objgraph
class Person(Object):
pass
class Cat(object):
pass
p = Person()
c = Cat()
p.name ='yuzhou1su'
c.master = p
print(sys.getrefcount(p))
print(sys.getfefcount(c))
del p
del c
gc.collect()
print(objgraph.count('Person'))
print(objgraph.count('Cat'))
当定位到哪个对象存在内存泄漏,就可以用show_backrefs查看这个对象的引用链。
内存池(memory pool)机制
频繁 申请、消耗 会导致大量的内存碎片,致使效率变低。
内存池的概念就是在内存中申请一定数量的,大小相等的内存块留作备用。
内存池池由单个大小类的块组成。每个池维护一个到相同大小类的其他池的双向链接列表。这样,即使在不同的池中,该算法也可以轻松找到给定块大小的可用空间。
当有新的内存需求时,就会先从内存池中分配内存留给这个需求。内存不够再申请新的内存。
内存池本身必须处于以下三种状态之一:
-
已使用
-
已满
-
或为空。
优点:减少内存碎片,提高效率。
总结
内存管理是计算机的一个非常重要的组成部分。 Python 跟 Java、Go 一样,帮助开发者从语言设计层面解决了这个问题,使得我们不用手动分配和释放内存,这也是这类语言的优势。
本文主要解释了:
-
什么是内存管理,管理方式的方式
-
Cpython 的内存管理方式
-
垃圾回收机制
-
Python 的引用计数、标记清楚和分代回收的垃圾自动回收方法。
-
最后介绍了手动回收的包和为了提高内存有效使用的内存池机制
希望看完这篇文章的读者能对内存管理和垃圾回收有所兴趣,下一篇文章再见~
参考文章:
对内存管理有兴趣的强烈推荐阅读: Memory Management in Python
https://www.cnblogs.com/TM0831/p/10599716.html
https://www.cnblogs.com/xybaby/p/7491656.html
https://www.jianshu.com/p/c2c960481011

- 点赞
- 收藏
- 关注作者
评论(0)