01初识spark

大家好,我是一条~
5小时推开Spark的大门,正式开始,第一个小时,我们主要学习以下内容:
- 什么是Spark?
- Spark和Hadoop什么关系?
- Spark有什么优点?
- Spark适合做什么?
- Spark的核心模块
- Spark的系统架构
一条会用简单通俗的语言帮大家理解spark的一些核心概念,以便于后面的应用。
什么是spark?
我们先开看看官网怎么说。
What is Apache Spark ?
什么是 Apache Spark ?
Apache Spark is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.
Apache Spark是一种多语言引擎,用于在单节点机器或集群上执行数据工程、数据科学和机器学习。
简单来说,Spark是一种大数据计算框架,是一种基于内存快速处理计算大数据的引擎。支持多种语言的API接口,可以单击也可以集群部署,其又提供了用于数据分析,机器学习的库。
Spark和Hadoop什么关系?
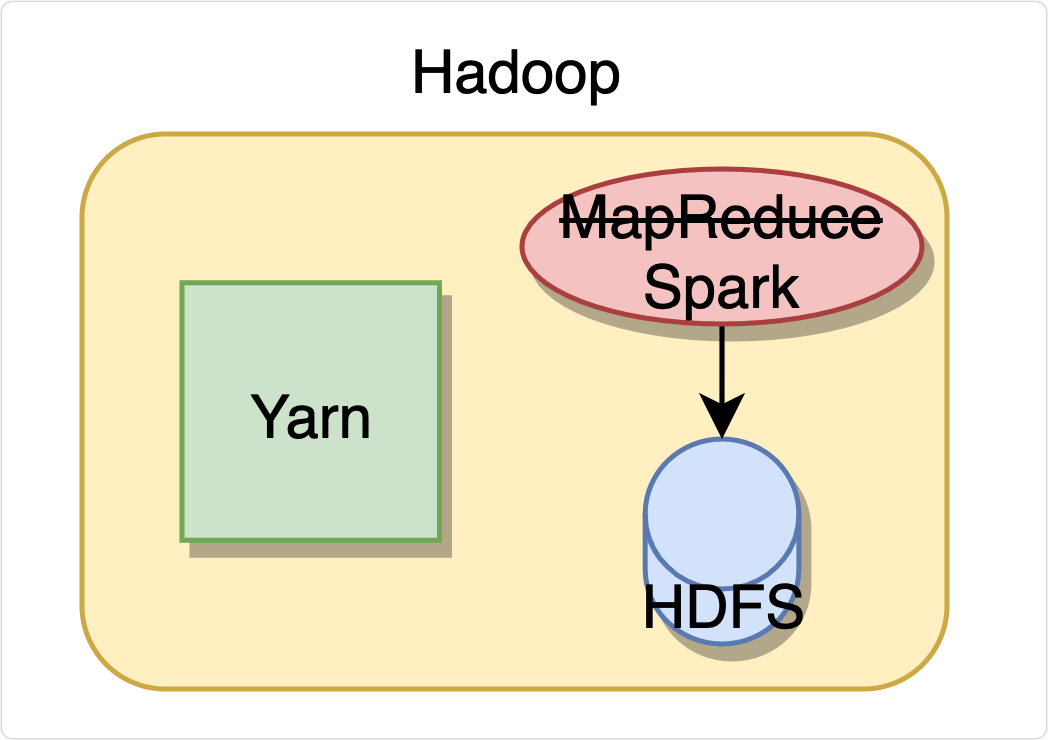
Hadoop只是一套工具的总称,也可以说是一个大数据生态。它包含HDFS,Yarn,MapReduce三部分,分别用来分布式文件存储、资源调度和计算。
这就是早期的大数据处理方案,用Yarn调度资源,读取HDFS内存储的文件内容进行MapReduce计算。
需要用Java代码实现,写起来比较麻烦,所以有了Hive来作为Hadoop的SQL解析和优化器,写一段SQL,解析为Java代码,然后去执行。
这样就完美了吗?
并没有,MapReduce简单来说就是分开处理再合并统计,需要频繁写读文件,就导致它运行起来很慢,这时基于内存的Spark出现了,他是MapReduce的替代品,为的就是提高速度,那Spark为什么快呢,后面会给大家详细讲解。
Spark有什么优点?
一个技术或框架的流行,必然是解决了某些难题,有其独特的优点,我们既要会用,又要知道为什么用。
-
快
刚刚说过,Spark是基于内存的,必然比频繁读写文件的MapReduce要快。
-
容易使用
如官方所说,Spark支持Java、Python、Scala、Sql、R的API,还支持超过80种高级算法。
-
功能全
即Spark的功能非常全面,批处理、交互式查询、流处理、机器学习等。而且这些功能并没有影响Spark的性能。
-
易融合
Spark非常方便的与其他开源产品进行融合。
Spark适合做什么?
Spark是数据计算处理的王者,支持PB级的处理,支持实时场景和离线场景。典型用例如下:
- 日志文件、传感器数据的流处理。
- 机器学习
- 数据分析师做交互式分析
- 各系统间的数据集成和清洗
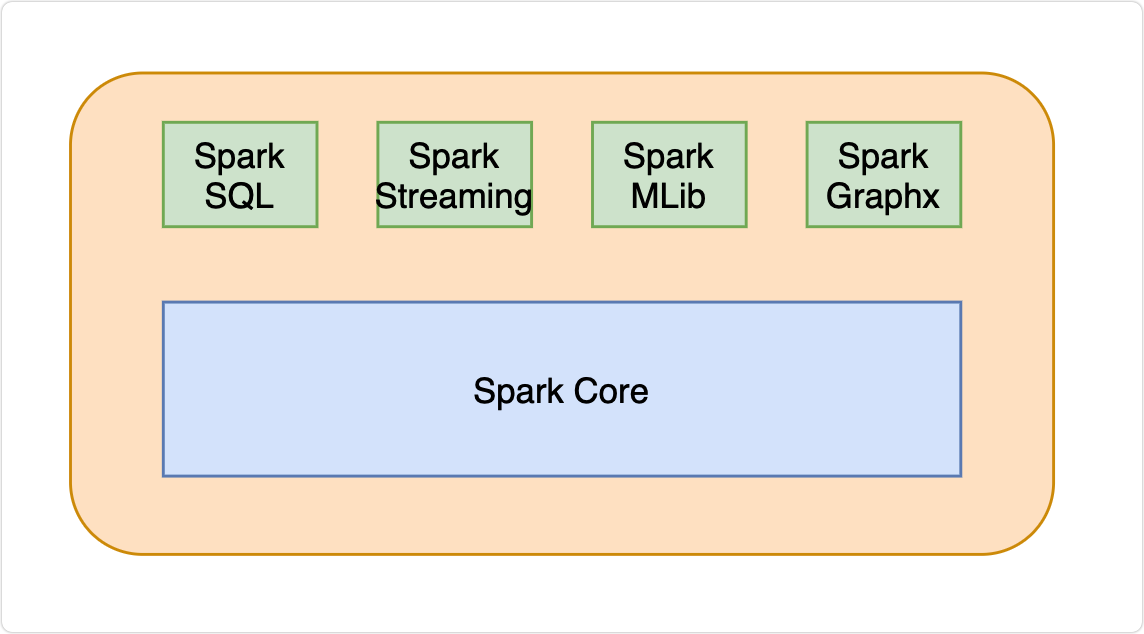
Spark的核心模块
- Spark Core
提供了Spark最基础与最核心的功能,是下面几个功能扩展的基础。
- Spark SQL
可以使用SQL操作结构化数据的组件。
- Spark Streaming
Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的 API。
- Spark MLlib
Spark提供的一个机器学习算法库,提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语,学习起来比较困难。
- Spark GraphX
Spark面向图计算提供的框架与算法库。
Spark的系统架构
关于系统架构,第一天会总体介绍,高屋建瓴,一览群山。
后几天再做详细讲解,步步深入。
Spark架构采用了分布式计算中的Master-Slave模型。Master是对应集群中的含有Master进程的节点,Slave是集群中含有Worker进程的节点。如图:
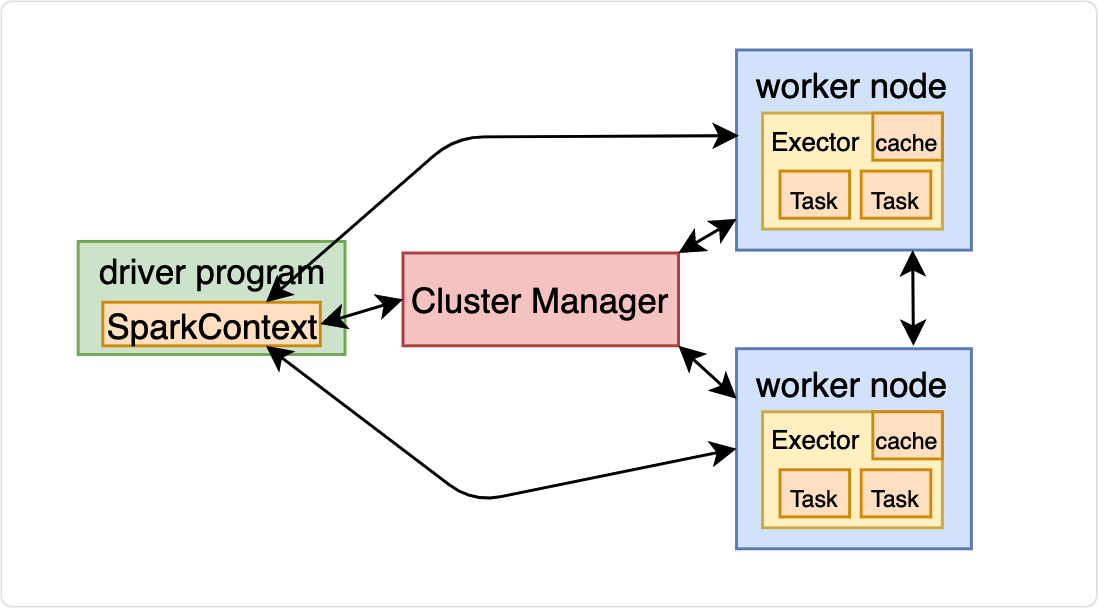
-
ClusterManager:在Standalone模式中即为Master(主节点),控制整个集群,监控Worker。在YARN模式中为资源管理器。
-
Worker:从节点,负责控制计算节点,启动Executor或Driver。在YARN模式中为NodeManager,负责计算节点的控制
-
Driver:运行
Application的main()函数并创建SparkContext。 -
Executor:执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executors。
-
SparkContext:整个应用的上下文,控制应用的生命周期。
最后
快乐的时光总是短暂的,这么快一个小时就过去了,第一天的知识都学废了吗?有些似懂非懂也没有关系,明天带大家上战场,实战Spark。
文章来源: blog.csdn.net,作者:一条coding,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/skylibiao/article/details/122660629

- 点赞
- 收藏
- 关注作者
评论(0)