【Kafka笔记】Kafka API详细解析 Java版本(Producer API,Consumer API,拦截器等)

简介
Kafka的API有Producer API,Consumer API还有自定义Interceptor (自定义拦截器),以及处理的流使用的Streams API和构建连接器的Kafka Connect API。
Producer API
Kafka的Producer发送消息采用的是异步发送的方式。在消息发送过程中,涉及两个线程:main线程和Sender线程,以及一个线程共享变量RecordAccumulator。main线程将消息发送给RecordAccmulator,Sender线程不断地从RecordAccumulator中拉取消息发送给Kafka broker。
这里的ACk机制,不是生产者得到ACK返回信息才开始发送,ACK保证的是生产者不丢失数据。例如:
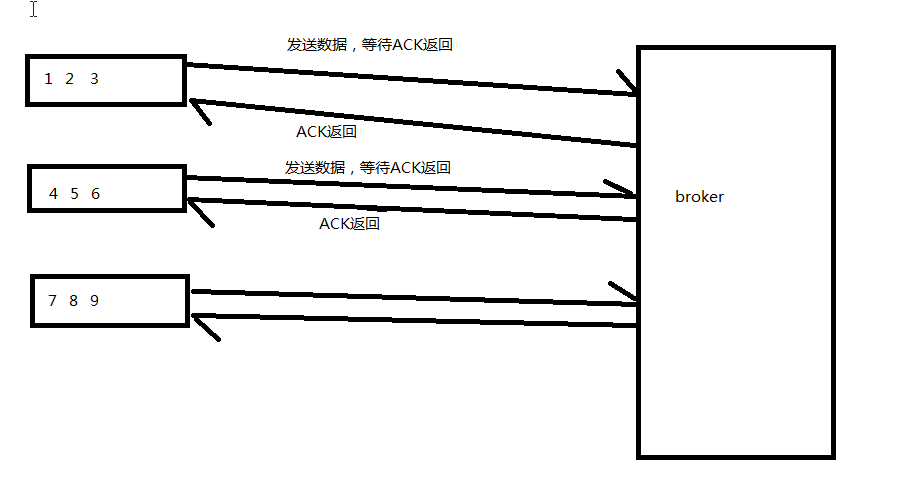
而是只要有消息数据,就向broker发送。
消息发送流程
生产者使用send方法,经过拦截器之后在经过序列化器,然后在走分区器。然后通过分批次把数据发送到PecordAccumulator,main线程到此过程就结束了,然后在回去执行send。
Sender线程不断的获取RecordAccumulator的数据发送到topic。
消息发送流程是异步发送的,并且顺序是一定的拦截器-》序列化器-》分区器
异步发送API
需要用到的类:
KafkaProducer: 需要创建一个生产者对象,用来发送数据
ProducerConfig:获取所需要的一系列配置参数
ProducerRecord:每条数据都要封装成一个ProducerRecord对象
实例:
public class KafkaProducerDemo {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "XXXXXXXXX:9093");//kafka集群,broker-list
props.put("acks", "all");
props.put("retries", 1);//重试次数
props.put("batch.size", 16384);//批次大小
props.put("linger.ms", 1);//等待时间
props.put("buffer.memory", 33554432);//RecordAccumulator缓冲区大小
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建KafkaProducer客户端
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10 ; i++) {
producer.send(new ProducerRecord<>("my-topic","ImKey-"+i,"ImValue-"+i));
}
// 关闭资源
producer.close();
}
}
配置参数说明:
send():方法是异步的,添加消息到缓冲区等待发送,并立即返回。生产者将单个的消息批量在一起发送来提高效率。
ack:是判断请求是否完整的条件(就会判断是不是成功发送了,也就是上次说的ACK机制),指定all将会阻塞消息,性能低但是最可靠。
retries:如果请求失败,生产者会自动重试,我们指定是1次,但是启动重试就有可能出现重复数据。
batch.size:指定缓存的大小,生产者缓存每个分区未发送的消息。值越大的话将会产生更大的批量,并需要更大的内存(因为每个活跃的分区都有一个缓存区)。
linger.ms:指示生产者发送请求之前等待一段时间,设置等待时间是希望更多地消息填补到未满的批中。默认缓冲可以立即发送,即便缓冲空间还没有满,但是如果想减少请求的数量可以设置linger.ms大于0。需要注意的是在高负载下,相近的时间一般也会组成批,即使等于0。
buffer.memory:控制生产者可用的缓存总量,如果消息发送速度比其传输到服务器的快,将会耗尽这个缓存空间。当缓存空间耗尽,其他发送调用将被阻塞,阻塞时间的阈值通过max.block.ms设定,之后将会抛出一个TimeoutException
key.serializer和value.serializer将用户提供的key和value对象ProducerRecord转换成字节,你可以使用附带的ByteArraySerializaer或StringSerializer处理简单的string或byte类型。
运行日志:
[Godway] INFO 2019-11-14 14:46 - org.apache.kafka.clients.producer.ProducerConfig[main] - ProducerConfig values:
acks = all
batch.size = 16384
bootstrap.servers = [XXXXXX:9093]
buffer.memory = 33554432
client.id =
compression.type = none
connections.max.idle.ms = 540000
enable.idempotence = false
interceptor.classes = null
key.serializer = class org.apache.kafka.common.serialization.StringSerializer
linger.ms = 1
max.block.ms = 60000
max.in.flight.requests.per.connection = 5
max.request.size = 1048576
metadata.max.age.ms = 300000
metric.reporters = []
metrics.num.samples = 2
metrics.recording.level = INFO
metrics.sample.window.ms = 30000
partitioner.class = class org.apache.kafka.clients.producer.internals.DefaultPartitioner
receive.buffer.bytes = 32768
reconnect.backoff.max.ms = 1000
reconnect.backoff.ms = 50
request.timeout.ms = 30000
retries = 1
retry.backoff.ms = 100
sasl.jaas.config = null
sasl.kerberos.kinit.cmd = /usr/bin/kinit
sasl.kerberos.min.time.before.relogin = 60000
sasl.kerberos.service.name = null
sasl.kerberos.ticket.renew.jitter = 0.05
sasl.kerberos.ticket.renew.window.factor = 0.8
sasl.mechanism = GSSAPI
security.protocol = PLAINTEXT
send.buffer.bytes = 131072
ssl.cipher.suites = null
ssl.enabled.protocols = [TLSv1.2, TLSv1.1, TLSv1]
ssl.endpoint.identification.algorithm = null
ssl.key.password = null
ssl.keymanager.algorithm = SunX509
ssl.keystore.location = null
ssl.keystore.password = null
ssl.keystore.type = JKS
ssl.protocol = TLS
ssl.provider = null
ssl.secure.random.implementation = null
ssl.trustmanager.algorithm = PKIX
ssl.truststore.location = null
ssl.truststore.password = null
ssl.truststore.type = JKS
transaction.timeout.ms = 60000
transactional.id = null
value.serializer = class org.apache.kafka.common.serialization.StringSerializer
[Godway] INFO 2019-11-14 14:46 - org.apache.kafka.common.utils.AppInfoParser[main] - Kafka version : 0.11.0.3
[Godway] INFO 2019-11-14 14:46 - org.apache.kafka.common.utils.AppInfoParser[main] - Kafka commitId : 26ddb9e3197be39a
[Godway] WARN 2019-11-14 14:46 - org.apache.kafka.clients.NetworkClient[kafka-producer-network-thread | producer-1] - Error while fetching metadata with correlation id 1 : {my-topic=LEADER_NOT_AVAILABLE}
[Godway] INFO 2019-11-14 14:46 - org.apache.kafka.clients.producer.KafkaProducer[main] - Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms.
Process finished with exit code 0
有一条警告{my-topic=LEADER_NOT_AVAILABLE} 提示该topic不存在,但是没有关系kafka会自动给你创建一个topic,不过创建的topic是有一个分区和一个副本:

查看一下该topic的消息:

消息已经在topic里了
上面的实例是没有回调函数的,send方法是有回调函数的:
public class KafkaProducerCallbackDemo {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "XXXXX:9093");//kafka集群,broker-list
props.put("acks", "all");
props.put("retries", 1);//重试次数
props.put("batch.size", 16384);//批次大小
props.put("linger.ms", 1);//等待时间
props.put("buffer.memory", 33554432);//RecordAccumulator缓冲区大小
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建KafkaProducer客户端
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 10; i < 20 ; i++) {
producer.send(new ProducerRecord<String, String>("my-topic", "ImKey-" + i, "ImValue-" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null){
System.out.println("消息发送成功!"+recordMetadata.offset());
}else {
System.err.println("消息发送失败!");
}
}
});
}
producer.close();
}
}
回调函数会在producer收到ack时调用,为异步调用,该方法有两个参数,分别是RecordMetadata和Exception,如果Exception为null,说明消息发送成功,如果Exception不为null说明消息发送失败。
注意: 消息发送失败会自动重试,不需要我们在回调函数中手动重试,使用回调也是无阻塞的。而且callback一般在生产者的IO线程中执行,所以是非常快的,否则将延迟其他的线程消息发送。如果需要执行阻塞或者计算的回调(耗时比较长),建议在callbanck主体中使用自己的Executor来并行处理!
同步发送API
同步发送的意思就是,一条消息发送之后,会阻塞当前的线程,直到返回ack(此ack和异步的ack机制不是一个ack)。
此ack是Future阻塞main线程,当发送完成就返回一个ack去通知main线程已经发送完毕,继续往下走了
public Future<RecordMetadata> send(ProducerRecord<K,V> record,Callback callback)
send是异步的,并且一旦消息被保存在等待发送的消息缓存中,此方法就立即返回。这样并行发送多条消息而不阻塞去等待每一条消息的响应。
发送的结果是一个RecordMetadata,它指定了消息发送的分区,分配的offset和消息的时间戳。如果topic使用的是CreateTime,则使用用户提供的时间戳或发送的时间(如果用户没有指定指定消息的时间戳)如果topic使用的是LogAppendTime,则追加消息时,时间戳是broker的本地时间。
由于send调用是异步的,它将为分配消息的此消息的RecordMetadata返回一个Future。如果future调用get(),则将阻塞,直到相关请求完成并返回该消息的metadata,或抛出发送异常。
Throws:
InterruptException - 如果线程在阻塞中断。
SerializationException - 如果key或value不是给定有效配置的serializers。
TimeoutException - 如果获取元数据或消息分配内存话费的时间超过max.block.ms。
KafkaException - Kafka有关的错误(不属于公共API的异常)。
public class KafkaProducerDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "XXXXX:9093");//kafka集群,broker-list
props.put("acks", "all");
props.put("retries", 1);//重试次数
props.put("batch.size", 16384);//批次大小
props.put("linger.ms", 1);//等待时间
props.put("buffer.memory", 33554432);//RecordAccumulator缓冲区大小
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建KafkaProducer客户端
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 20; i < 30 ; i++) {
RecordMetadata metadata = producer.send(new ProducerRecord<>("my-topic", "ImKey-" + i, "ImValue-" + i)).get();
System.out.println(metadata.offset());
}
producer.close();
}
}
API生产者自定义分区策略
生产者在向topic发送消息的时候的分区规则:
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers)
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value)
public ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers)
public ProducerRecord(String topic, Integer partition, K key, V value)
public ProducerRecord(String topic, K key, V value)
public ProducerRecord(String topic, V value)
根据send方法的参数的构造方法就可以看出来,
- 指定分区就发送到指定分区
- 没有指定分区,有key值,就按照key值的Hash值分配分区
- 没有指定分区,也没有指定key值,轮询分区分配(只分配一次,以后都按照第一次的分区顺序)
自定义分区器
自定义分区器需要实现org.apache.kafka.clients.producer.Partitioner接口。并且实现三个方法
public class KafkaMyPartitions implements Partitioner {
@Override
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
return 0;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
自定义分区实例:
KafkaMyPartitions:
public class KafkaMyPartitions implements Partitioner {
@Override
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
// 这里写自己的分区策略
// 我这里指定为1
return 1;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}
KafkaProducerCallbackDemo:
public class KafkaProducerCallbackDemo {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "XXXXX:9093");//kafka集群,broker-list
props.put("acks", "all");
props.put("retries", 1);//重试次数
props.put("batch.size", 16384);//批次大小
props.put("linger.ms", 1);//等待时间
props.put("buffer.memory", 33554432);//RecordAccumulator缓冲区大小
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 指定自定义分区
props.put("partitioner.class","com.firehome.newkafka.KafkaMyPartitions");
// 创建KafkaProducer客户端
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 20; i < 25 ; i++) {
producer.send(new ProducerRecord<String, String>("th-topic", "ImKey-" + i, "ImValue-" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null){
System.out.printf("消息发送成功!topic=%s,partition=%s,offset=%d \n",recordMetadata.topic(),recordMetadata.partition(),recordMetadata.offset());
}else {
System.err.println("消息发送失败!");
}
}
});
}
producer.close();
}
}
返回日志:
消息发送成功!topic=th-topic,partition=1,offset=27
消息发送成功!topic=th-topic,partition=1,offset=28
消息发送成功!topic=th-topic,partition=1,offset=29
消息发送成功!topic=th-topic,partition=1,offset=30
消息发送成功!topic=th-topic,partition=1,offset=31
可以看到直接发送到了分区1上了。
多线程发送消息
Producer API是线程安全的,直接就可以使用多线程发送消息,实例:
public class KafkaProducerThread implements Runnable {
private KafkaProducer<String,String> kafkaProducer;
public KafkaProducerThread(){
}
public KafkaProducerThread(KafkaProducer kafkaProducer){
this.kafkaProducer = kafkaProducer;
}
@Override
public void run() {
for (int i = 0; i < 20 ; i++) {
String key = "ImKey-" + i+"-"+Thread.currentThread().getName();
String value = "ImValue-" + i+"-"+Thread.currentThread().getName();
kafkaProducer.send(new ProducerRecord<>("th-topic", key, value));
System.out.printf("Thread-name = %s, key = %s, value = %s",Thread.currentThread().getName(),key,value);
}
}
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "XXXXXXXX:9093");//kafka集群,broker-list
props.put("acks", "all");
props.put("retries", 1);//重试次数
props.put("batch.size", 16384);//批次大小
props.put("linger.ms", 1);//等待时间
props.put("buffer.memory", 33554432);//RecordAccumulator缓冲区大小
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建KafkaProducer客户端
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
KafkaProducerThread producerThread1 = new KafkaProducerThread(producer);
//KafkaProducerThread producerThread2 = new KafkaProducerThread(producer);
Thread one = new Thread(producerThread1, "one");
Thread two = new Thread(producerThread1, "two");
System.out.println("线程开始");
one.start();
two.start();
}
}
这里只是一个简单的实例。
Consumer API
kafka客户端通过TCP长连接从集群中消费消息,并透明地处理kafka集群中出现故障服务器,透明地调节适应集群中变化的数据分区。也和服务器交互,平衡均衡消费者。
偏移量和消费者的位置
kafka为分区中的每条消息保存一个偏移量(offset),这个偏移量是该分区中一条消息的唯一标示符。也表示消费者在分区的位置。例如,一个位置是5的消费者(说明已经消费了0到4的消息),下一个接收消息的偏移量为5的消息。实际上有两个与消费者相关的“位置”概念:
消费者的位置给出了下一条记录的偏移量。它比消费者在该分区中看到的最大偏移量要大一个。 它在每次消费者在调用poll(long)中接收消息时自动增长。
“已提交”的位置是已安全保存的最后偏移量,如果进程失败或重新启动时,消费者将恢复到这个偏移量。消费者可以选择定期自动提交偏移量,也可以选择通过调用commit API来手动的控制(如:commitSync 和 commitAsync)。
这个区别是消费者来控制一条消息什么时候才被认为是已被消费的,控制权在消费者。
消费者组和主题订阅
Kafka的消费者组概念,通过进程池瓜分消息并处理消息。这些进程可以在同一台机器运行,也可分布到多台机器上,以增加可扩展性和容错性,相同group.id的消费者将视为同一个消费者组。
分组中的每个消费者都通过subscribe API动态的订阅一个topic列表。kafka将已订阅topic的消息发送到每个消费者组中。并通过平衡分区在消费者分组中所有成员之间来达到平均。因此每个分区恰好地分配1个消费者(一个消费者组中)。所有如果一个topic有4个分区,并且一个消费者分组有只有2个消费者。那么每个消费者将消费2个分区。
消费者组的成员是动态维护的:如果一个消费者故障。分配给它的分区将重新分配给同一个分组中其他的消费者。同样的,如果一个新的消费者加入到分组,将从现有消费者中移一个给它。这被称为重新平衡分组。当新分区添加到订阅的topic时,或者当创建与订阅的正则表达式匹配的新topic时,也将重新平衡。将通过定时刷新自动发现新的分区,并将其分配给分组的成员。
从概念上讲,你可以将消费者分组看作是由多个进程组成的单一逻辑订阅者。作为一个多订阅系统,Kafka支持对于给定topic任何数量的消费者组,而不重复。
这是在消息系统中常见的功能的略微概括。所有进程都将是单个消费者分组的一部分(类似传统消息传递系统中的队列的语义),因此消息传递就像队列一样,在组中平衡。与传统的消息系统不同的是,虽然,你可以有多个这样的组。但每个进程都有自己的消费者组(类似于传统消息系统中pub-sub的语义),因此每个进程都会订阅到该主题的所有消息。
此外,当分组重新分配自动发生时,可以通过ConsumerRebalanceListener通知消费者,这允许他们完成必要的应用程序级逻辑,例如状态清除,手动偏移提交等
它也允许消费者通过使用assign(Collection)手动分配指定分区,如果使用手动指定分配分区,那么动态分区分配和协调消费者组将失效。
发现消费者故障
订阅一组topic,当调用poll(long)时,消费者将自动加入到消费者组中。只要持续调用poll,消费者将一直保持可用,并继续从分配的分区中接收数据。此外,消费者向服务器定时发送心跳。如果消费者崩溃或无法再session.timeout.ms配置的时间内发送心跳,则消费者就被视为死亡,并且其分区将被重新分配。
还有一种可能,消费者可能遇到活锁的情况,它持续的发送心跳,但是没有处理。为了预防消费者在这总情况下一直拥有分区,我们使用max.poll.interval.ms活跃监测机制。在此基础上,如果你调用的poll的频率大于最大间隔,则客户端将主动地离开组,以便其他消费者接管该分区。发生这种情况时,你会看到offset提交失败( 调用commitSync()引发的CommitFailedException )。这是一种安全机制,保障只有活动成员能够提交offset。所以要留在组中,你必须持续调用poll。
消费者提供两种配置设置来控制poll循环:
max.poll.interval.ms:增大poll的间隔,可以为消费者提供更多的时间去处理返回的消息(调用poll(long)返回的消息,通常返回的消息都是一批),缺点是此值越大将会延迟组重新平衡。max.poll.records:此设置限制每次调用poll返回的消息数,这样可以更容易的预测每次poll间隔要处理的最大值。通过调整此值,可以减少poll间隔,减少重新平衡分组的
对于消息处理时间不可预测地情况,这些选项是不够的。 处理这种情况的推荐方法是将消息处理移到另一个线程中,让消费者继续调用poll。 但是必须注意确保已提交的offset不超过实际位置。另外,你必须禁用自动提交,并只有在线程完成处理后才为记录手动提交偏移量。 还要注意, 你需要pause暂停分区,不会从poll接收到新消息,让线程处理完之前返回的消息(如果你的处理能力比拉取消息的慢,那创建新线程将导致机器内存溢出)。
实例:
自动提交偏移量
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers","xxxxxxxxxx:9093");
props.put("group.id","test-6");//消费者组,只要group.id相同,就属于同一个消费者组
props.put("enable.auto.commit","true");//自动提交offset
props.put("auto.commit.interval.ms","1000"); // 自动提交时间间隔
props.put("max.poll.records","5"); // 拉取的数据条数
props.put("session.timeout.ms","10000"); // 维持session的时间。超过这个时间没有心跳 就会剔出消费者组
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 可以写多个topic
consumer.subscribe(Arrays.asList("my-topic"));
while (true){
ConsumerRecords<String, String> records = consumer.poll(5000);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
System.out.println("处理了一批数据!");
}
}
配置说明:
bootstrap.servers: 集群是通过配置bootstrap.servers指定一个或多个broker。不用指定全部的broker,它将自动发现集群中的其余的borker(最好指定多个,万一有服务器故障)
enable.auto.commit: 自动提交偏移量,如果设置了自动提交偏移量,下面这个设置就必须要用到了。
auto.commit.interval.ms:自动提交时间间隔,和自动提交偏移量配合使用
max.poll.records:控制从 broker拉取的消息条数
poll(long time): 当消费者获取不到消息时,就会使用这个参数,为了减轻无效的循环请求消息,消费者会每隔long time的时间请求一次消息,单位是毫秒。
session.timeout.ms: broker通过心跳机器自动检测消费者组中失败的进程,消费者会自动ping集群,告诉进群它还活着。只要消费者能够做到这一点,它就被认为是活着的,并保留分配给它分区的权利,如果它停止心跳的时间超过session.timeout.ms,那么就会认为是故障的,它的分区将被分配到别的进程。
auto.offset.reset:这个属性很重要,一会详细讲解
这里说明一下auto.commit.interval.ms以及何时提交消费者偏移量,经过测试:
-
设置
props.put("auto.commit.interval.ms","60000");自动提交时间为一分钟,也就是你在这一分钟内拉取任何数量的消息都不会被提交消费的当前偏移量,如果你此时关闭消费者(一分钟内),下次消费还是从和第一次的消费数据一样,即使你在一分钟内消费完所有的消息,只要你在一分钟内关闭程序,导致提交不了offset,就可以一直重复消费数据。
-
设置
props.put("auto.commit.interval.ms","3000");但是在消费过程中设置sleep。
public static void main(String[] args) { Properties props = new Properties(); props.put("bootstrap.servers","xxxxxxxxxxxx:9093"); props.put("group.id","test-6");//消费者组,只要group.id相同,就属于同一个消费者组 props.put("enable.auto.commit","true");//自动提交offset props.put("auto.commit.interval.ms","100000"); // 自动提交时间间隔 props.put("max.poll.records","5"); // 拉取的数据条数 props.put("session.timeout.ms","10000"); // 维持session的时间。超过这个时间没有心跳 就会剔出消费者组 props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); props.put("auto.offset.reset", "earliest"); // KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); // 可以写多个topic consumer.subscribe(Arrays.asList("my-topic")); while (true){ ConsumerRecords<String, String> records = consumer.poll(5000); for (ConsumerRecord<String, String> record : records) { System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); } try { Thread.sleep(5000L); System.out.println("等待了5秒了!!!!!!!!!!!!开始等待15秒了"); Thread.sleep(5000L); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("处理了一批数据!"); } }这里如果你消费了第一批数据,在执行第二次
poll的时候,关闭程序也不会提交偏移量,只有在执行第二次poll的时候才会把上一次的最后一个offset提交上去。
auto.offset.reset讲解:
auto.offset.reset的值有三种:earliest,latest,none,代表者不同的意思
earliest:
当各分区下有已经提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费,最常用的值
latest:
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
none:
topic各分区都存在已提交的offset时,从offset后开始消费,只要有一个分区不存在已提交的offset,则抛出异常
!!注意:当使用了latest,并且分区没有已提交的offset时,消费新产生的该分区下的数据,其实是把offset的值直接设置到最后一个消息的位置。例如,有个30条数据的demo的topic,各分区无提交offset,使用了latest,再看offset就会发现已经在30的位置了,所以才只能消费新产生的数据!!!!
手动提交偏移量
不需要定时提交偏移量,可以自己控制offset,当消息已经被我们消费过后,再去手动提交他们的偏移量。这个很适合我们的一些处理逻辑。
手动提交offset的方法有两种:分别是commitSync(同步提交) 和commitAsync(异步提交)。两者的相同点,都会将本次poll的一批数据最高的偏移量提交;不同点是commitSync会失败重试,一直到提交成功(如果有不可恢复的原因导致,也会提交失败),才去拉取新数据。而commitAsync则没有重试机制(提交了就去拉取新数据,不管这次的提交有没有成功),故有可能提交失败。
实例:
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers","XXXXXC:9093");
props.put("group.id","test-11");//消费者组,只要group.id相同,就属于同一个消费者组
props.put("enable.auto.commit","false");//自动提交offset
props.put("auto.commit.interval.ms","1000"); // 自动提交时间间隔
props.put("max.poll.records","20"); // 拉取的数据条数
props.put("session.timeout.ms","10000"); // 维持session的时间。超过这个时间没有心跳 就会剔出消费者组
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
int i= 0;
while (true){
ConsumerRecords<String, String> records = consumer.poll(5000);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
i++;
}
if (i == 20){
System.out.println("i_num:"+i);
// 同步提交
consumer.commitSync();
// 异步提交
// consumer.commitAsync();
}else {
System.out.println("不足二十个,不提交"+i);
}
i=0;
}
}
这些都是全部提交偏移量,如果我们想更细致的控制偏移量提交,可以自定义提交偏移量:
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers","XXXXXXXXXX:9093");
props.put("group.id","test-18");//消费者组,只要group.id相同,就属于同一个消费者组
props.put("enable.auto.commit","false");//自动提交offset
props.put("auto.commit.interval.ms","1000000"); // 自动提交时间间隔
props.put("max.poll.records","5"); // 拉取的数据条数
props.put("session.timeout.ms","10000"); // 维持session的时间。超过这个时间没有心跳 就会剔出消费者组
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
while (true){
ConsumerRecords<String, String> records = consumer.poll(5000);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitAsync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)), new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
for (Map.Entry<TopicPartition,OffsetAndMetadata> entry : map.entrySet()){
System.out.println("提交的分区:"+entry.getKey().partition()+",提交的偏移量:"+entry.getValue().offset());
}
}
});
}
}
}
订阅指定的分区
通过消费者Kafka会通过分区分配分给消费者一个分区,但是我们也可以指定分区消费消息,要使用指定分区,只需要调用assign(Collection)消费指定的分区即可:
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers","XXXXXXXXX:9093");
props.put("group.id","test-19");//消费者组,只要group.id相同,就属于同一个消费者组
props.put("enable.auto.commit","false");//自动提交offset
props.put("auto.commit.interval.ms","1000000"); // 自动提交时间间隔
props.put("max.poll.records","5"); // 拉取的数据条数
props.put("session.timeout.ms","10000"); // 维持session的时间。超过这个时间没有心跳 就会剔出消费者组
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(props);
// 你可以指定多个不同topic的分区或者相同topic的分区 我这里只指定一个分区
TopicPartition topicPartition = new TopicPartition("my-topic", 0);
// 调用指定分区用assign,消费topic使用subscribe
consumer.assign(Arrays.asList(topicPartition));
while (true){
ConsumerRecords<String, String> records = consumer.poll(5000);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitAsync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)), new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
for (Map.Entry<TopicPartition,OffsetAndMetadata> entry : map.entrySet()){
System.out.println("提交的分区:"+entry.getKey().partition()+",提交的偏移量:"+entry.getValue().offset());
}
}
});
}
}
}
一旦手动分配分区,你可以在循环中调用poll。消费者分区任然需要提交offset,只是现在分区的设置只能通过调用assign 修改,因为手动分配不会进行分组协调,因此消费者故障或者消费者的数量变动都不会引起分区重新平衡。每一个消费者是独立工作的(即使和其他的消费者共享GroupId)。为了避免offset提交冲突,通常你需要确认每一个consumer实例的groupId都是唯一的。
注意:
手动分配分区(assgin)和动态分区分配的订阅topic模式(subcribe)不能混合使用。

- 点赞
- 收藏
- 关注作者
评论(0)