Python监督学习之分类算法的概述

初入机器学习,无论是在书本上,还是在学习平台上,第一个介绍的就是监督学习,那么什么是监督学习呢?监督——顾名思义,把你“看着学习”,说的直白一点就是让你的计算机明白一种规律,并且按照这种规律进行大量的学习,最后通过该规律进行预测或者分类。
生活中有垃圾分类,也有物品的好坏分类,在这个世界上凡事存在的东西,我们都会给它定义一个属性,人也不例外,有好人坏人之称,也有穷人富人之别,一个事物可以被定义多个属性。

在监督学习里面,又分为:分类和回归,这里简单的介绍一下什么是分类,什么样的数据适合做分类,分类又分为多少种?
分类:适用于目标列离散的数据,注意这里是目标列,也就是通过模型需要预测的列,它如果是一个离散的数据,那么适用于分类。
分类又分为:二分类,多分类
二分类就是一个目标列只有两种情况,一般的分类以二分类为主,比如在预测肿瘤是良性还是恶性,预测商品是否会被售卖成功,检测某样品是否合格。
多分类就是一个目标列有多种情况,比如某信用等级有:A、B、C、D四种情况,那么这个时候就是一个多分类的情况,多分类得的算法和二分类差不多,在细节上有点不一样。
分类方法的定义:分类分析的是根据已知类别的训练集数据,建立分类模型,并利用该分类模型预测未知类别数据对象所属的类别。
分类方法的应用:
1、模式识别(Pattern Recognition),就是通过计算机用数学技术方法来研究模式的自动处理和判读。模式识别的目标往往是识别,即分析出待测试的样本所属的模式类别。
2、预测,从利用历史数据记录中自动推导出对给定数据的推广描述,从而能对未来数据进行类预测。
-
现实应用案例
1、行为分析
2、物品识别、图像检测
3、电子邮件的分类(垃圾邮件和非垃圾邮件等)
4、新闻稿件的分类、手写数字识别、个性化营销中的客户群分类、图像/视频的场景分类等
-
分类器
-
分类的实现方法是创建一个分类器(分类函数或模型),该分类器能把待分类的数据映射到给定的
-
类别中。
-
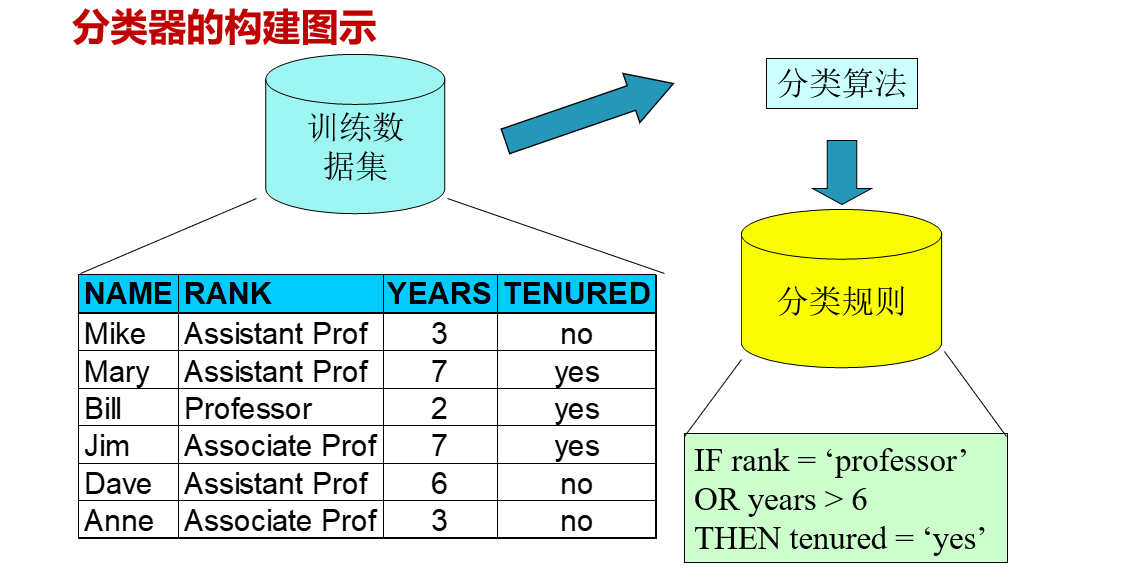
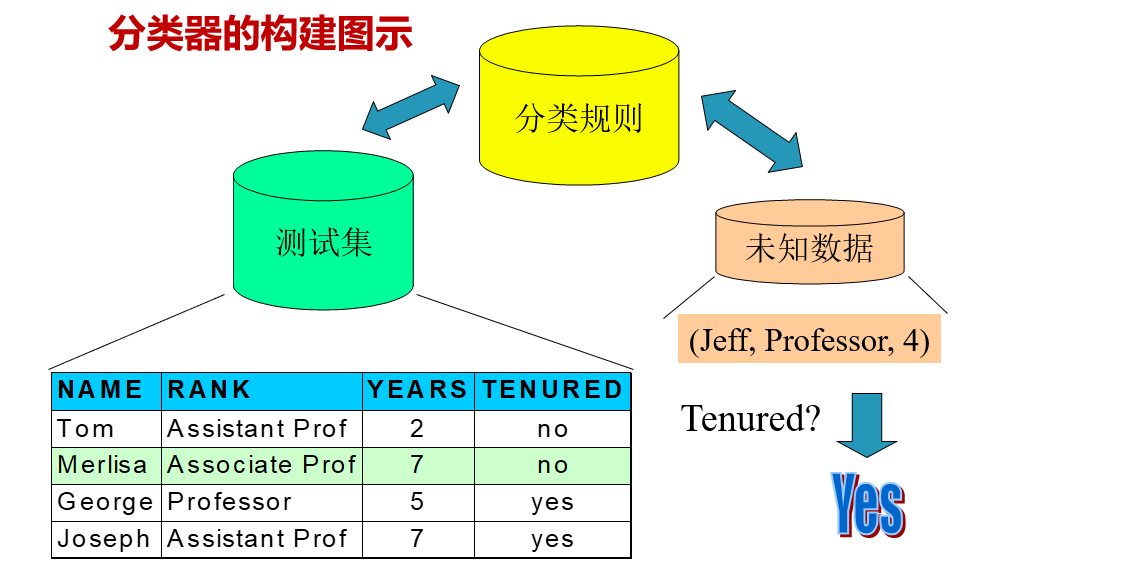
创建分类的过程与机器学习的一般过程一致
上一篇文章我们讲述了,机器学习的框架和以及相关的理论知识,也就是说在一个完整的模型训练当中,这些步骤是不可或缺的。
![]()
![]()
分类器的构建标准
使用下列标准比较分类和预测方法
预测的准确率:模型正确预测新数据的类编号的能力
速度:产生和使用模型的计算花销
健壮性:给定噪声数据或有空缺值的数据,模型正确预测的能力
可伸缩性:对大量数据,有效的构建模型的能力
可解释性:学习模型提供的理解和洞察的层次
常见的分类算法
逻辑回归(尽管是回归的算法但实际上是完成分类的问题)
决策树(包括 ID3 算法、 C4.5 算法和 CART 算法)
神经网络
贝叶斯
K-近邻算法
支持向量机(SVM)
这些分类算法适合的使用场景并不完全一致,需要根据实际的应用评价才能选对适合的算法
模型。
分类算法的常见应用包括:决策树方法在医学诊断、贷款风险评估等领域应用;神经网络在识别手写字符、语音识别和人脸识别等应用,贝叶斯在垃圾邮件过滤、文本拼写纠正方向的应用等。
分类也是一个常见的预测问题,这个分类解决的问题与生活中分类问题基本一致,比如我们会根据天气的情况决定是否出行,这里面的天气情况就是因变量特征值,出行与否就是因变量标签值,分类算法是将我们思考的过程进行了自动化或半自动化。
数据挖掘中的分类典型的应用是根据事物在数据层面表现的特征,对事物进行科学的分类。分类与回归的区别在于:回归可用于预测连续的目标变量,分类可用于预测离散的目标变量。

在计算机语言中,分类你最容易想到的是什么逻辑语言,不错,答案就是:判断语句
这也是分类的底层思想,就像是决策树一样,一个条件下有很多的分支
下期文章我们将介绍,模型训练中的特征工程
每文一语
不去羡慕才能获得宁静,不去攀比最终才可直到青云

- 点赞
- 收藏
- 关注作者
评论(0)