机器学习(三)降维之PCA及鸢尾花降维

【摘要】
一.主成分分析(Principal Component Analysis,PCA)
(1)简介
最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等。 PCA可以把具有相关性的高维变量合成为线性无关的低维变量,称为主成分。主成分能够尽可能保留原始数据的信息。
(2)复习相关术语
• 方差:各个样...
一.主成分分析(Principal Component Analysis,PCA)
(1)简介
最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等。
PCA可以把具有相关性的高维变量合成为线性无关的低维变量,称为主成分。主成分能够尽可能保留原始数据的信息。
(2)复习相关术语
• 方差:各个样本和样本均值的差的平方和的均值,用来度量一组数据的分散程度。
• 协方差:用于度量两个变量之间的线性相关性程度,若两个变量的协方差为0,则可认为二者线性无关。协方差矩阵则是由变量的协方差值构成的矩阵(对称阵)。
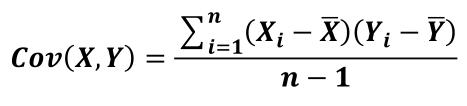
• 协方差矩阵
• 特征向量和特征值
特征向量:矩阵的特征向量是描述数据集结构的非零向量,并满足如下公式:![]()
A是方阵, 𝒗是特征向量,𝝀是特征值。
(3)PCA原理
矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主成分,以此类推。

sklearn中主成分分析
在sklearn库中,可以使用sklearn.decomposition.PCA加载PCA进行降维,主要参数有:
• n_components:指定主成分的个数,即降维后数据的维度
• svd_solver :设置特征值分解的方法,默认为‘auto’,其他可选有
‘full’, ‘arpack’, ‘randomized’。
(4)鸢尾花实例

目标:已知鸢尾花数据是4维的,共三类样本。使用PCA实现对鸢尾花数据进行降维,实现在二维平面上的可视化。
-
import matplotlib.pyplot as plt
-
#加载matplotlib用于数据的可视化
-
from sklearn.decomposition import PCA
-
#加载PCA算法包
-
from sklearn.datasets import load_iris
-
#加载鸢尾花数据集到输入函数
-
-
data = load_iris()
-
#以字典形式加载鸢尾花数据集
-
y = data.target #使用y表示数据集中的标签
-
X = data.data #使用X表示数据集中的属性数据
-
pca = PCA(n_components=2)
-
#加载PCA算法,设置降维后主成分数目为2
-
-
reduced_X = pca.fit_transform(X)
-
#对原始数据进行降维,保存在reduced_X中
-
-
#按照类别对降维后的数据进行保存
-
red_x, red_y = [], []
-
blue_x, blue_y = [], []
-
green_x, green_y = [], []
-
-
for i in range(len(reduced_X)):
-
if y[i] == 0:
-
red_x.append(reduced_X[i][0])
-
red_y.append(reduced_X[i][1])
-
elif y[i] == 1:
-
blue_x.append(reduced_X[i][0])
-
blue_y.append(reduced_X[i][1])
-
else:
-
green_x.append(reduced_X[i][0])
-
green_y.append(reduced_X[i][1])
-
#按照鸢尾花的类别将降维后的数据点保存在不同的列表中
-
-
plt.scatter(red_x, red_y, c='r', marker='x')
-
plt.scatter(blue_x, blue_y, c='b', marker='D')
-
plt.scatter(green_x, green_y, c='g', marker='.')
-
plt.show()
结果输出:

由上图可以看出降维后的数据清晰分成3类,得以削减数据的维度,降低分类任务的工作量,保证分类质量。
文章来源: andyguo.blog.csdn.net,作者:山顶夕景,版权归原作者所有,如需转载,请联系作者。
原文链接:andyguo.blog.csdn.net/article/details/104326860

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)