机器学习(八)监督学习之人体运动状态预测

一.实例介绍
(1)实例背景
• 可穿戴式设备的流行,让我们可以更便利地使用传感器获取人体的各项数据,甚至生理数据。
• 当传感器采集到大量数据后,我们就可以通过对数据进行分析和建模,通过各项特征的数值进行用户状态的判断,根据用户所处的状态提供给用户更加精准、便利的服务
(2)数据介绍
• 我们现在收集了来自 A,B,C,D,E 5位用户的可穿戴设备上的传感器数据,每位用户的数据集包含一个特征文件(a.feature)和一个标签文件(a.label)。
• 特征文件中每一行对应一个时刻的所有传感器数值,标签文件中每行记录了和特征文件中对应时刻的标记过的用户姿态,两个文件的行数相同,相同行之间互相对应。
1)特征文件


人体的温度数据可以反映当前活动的剧烈程度,一般在静止状态时,体温趋于稳定在36.5度上下;当温度高于37度时,可能是进行短时间的剧烈运动,比如跑步和骑行。
在数据中有两个型号的加速度传感器,可以通过互相印证的方式,保证数据的完整性和准确性。通过加速度传感器对应的三个数值,可以知道空间中x、y、z三个轴上对应的加速度,而空间上的加速度和用户的姿态有密切的关系,比如用户向上起跳时,z轴上的加速度会激增。
陀螺仪是角运动检测的常用仪器,可以判断出用户佩戴传感器时的身体角度是水平、倾斜还是垂直。直观地,通过这些数值都是推断姿态的重要指标。
磁场传感器可以检测用户周围的磁场强度和数值大小,这些数据可以帮助我们理解用户所处的环境。比如在一个办公场所,用户座位附近的磁场是大体上固定的,当磁场发生改变时,我们可以推断用户的位置和场景发生了变化。
2)标签文件
标签文件内容如图所示,每一行代表与特征文件中对应行的用户姿态类别。总共有0-24共25种身体姿态,如,无活动状态,坐态、跑态等。标签文件作为训练集的标准参考准则,可以进行特征的监督学习。
(3)实例任务
假设现在出现了一个新用户,但我们只有传感器采集的数据,那么该如何得到这个新用户的姿态呢?
对同一用户如果传感器采集了新的数据,怎么样根据新的数据判断当前用户处于什么样的姿态呢?
(4)算法流程
需要从特征文件和标签文件中将所有数据加载到内存中,由于存在缺失值,此步骤还需要进行简单的数据预处理。
创建对应的分类器,并使用训练数据进行训练。
利用测试集预测,通过使用真实值和预测值的比对,计算模型整体的准确率和召回率,来评测模型。

1)模块导入
导入numpy库和pandas库。
从sklearn库中导入预处理模块Imputer
导入自动生成训练集和测试集的模块train_test_split
导入预测结果评估模块classification_report
接下来,从sklearn库中依次导入三个分类器模块:K近邻分类器KNeighborsClassifier、决策树分类器DecisionTreeClassifier和高斯朴素贝叶斯函数GaussianNB。
-
import pandas as pd
-
import numpy as np
-
-
from sklearn.preprocessing import Imputer
-
from sklearn.cross_validation import train_test_split
-
from sklearn.metrics import classification_report
-
-
from sklearn.neighbors import KNeighborsClassifier
-
from sklearn.tree import DecisionTreeClassifier
-
from sklearn.naive_bayes import GaussianNB
2)数据导入函数
编写数据导入函数,设置传入两个参数,分别是特征文件的列表feature_paths和标签
文件的列表label_paths。
定义feature数组变量,列数量和特征维度一致为41;定义空的标签变量,列数量与标
签维度一致为1。
-
def load_datasets(feature_paths, label_paths):
-
feature = np.ndarray(shape=(0,41))
-
label = np.ndarray(shape=(0,1))
使用pandas库的read_table函数读取一个特征文件的内容,其中指定分隔符为逗号、缺失值为问号且
文件不包含表头行。
使用Imputer函数,通过设定strategy参数为‘mean’,使用平均值对缺失数据进行补全。fit()函数
用于训练预处理器,transform()函数用于生成预处理结果。
将预处理后的数据加入feature,依次遍历完所有特征文件
-
for file in feature_paths:
-
df = pd.read_table(file, delimiter=',', na_values='?', header=None)
-
imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
-
imp.fit(df)
-
df = imp.transform(df)
-
feature = np.concatenate((feature, df))
遵循与处理特征文件相同的思想,我们首先使用pandas库的read_table函数读取一个标签文件的内容,
其中指定分隔符为逗号且文件不包含表头行。
由于标签文件没有缺失值,所以直接将读取到的新数据加入label集合,依次遍历完所有标签文件,得
到标签集合label。
最后函数将特征集合feature与标签集合label返回。
-
for file in label_paths:
-
df = pd.read_table(file, header=None)
-
label = np.concatenate((label, df))
-
-
label = np.ravel(label)
-
return feature, label
3)主函数-数据准备
设置数据路径feature_paths和label_paths。
使用python的分片方法,将数据路径中的前4个值作为训练集,并作为参数传入load_dataset()函数中,
得到训练集合的特征x_train,训练集的标签y_train。
将最后一个值对应的数据作为测试集,送入load_dataset()函数中,得到测试集合的特征x_test,测试
集的标签y_test。
使用train_test_split()函数,通过设置测试集比例test_size为0,将数据随机打乱,便于后续分类
器的初始化和训练
-
if __name__ == '__main__':
-
''' 数据路径 '''
-
featurePaths = ['A/A.feature','B/B.feature','C/C.feature','D/D.feature','E/E.feature']
-
labelPaths = ['A/A.label','B/B.label','C/C.label','D/D.label','E/E.label']
-
''' 读入数据 '''
-
x_train,y_train = load_datasets(featurePaths[:4],labelPaths[:4])
-
x_test,y_test = load_datasets(featurePaths[4:],labelPaths[4:])
-
x_train, x_, y_train, y_ = train_test_split(x_train, y_train, test_size = 0.0)
4)主函数——KNN
使用默认参数创建K近邻分类器,并将训练集x_train和y_train送入fit()函数进行训练,训练后的分类
器保存到变量knn中。
使用测试集x_test,进行分类器预测,得到分类结果answer_knn
-
print('Start training knn')
-
knn = KNeighborsClassifier().fit(x_train, y_train)
-
print('Training done')
-
answer_knn = knn.predict(x_test)
-
print('Prediction done')
5)主函数——决策树
使用默认参数创建决策树分类器dt,并将训练集x_train和y_train送入fit()函数进行训练。训练后的分
类器保存到变量dt中。
使用测试集x_test,进行分类器预测,得到分类结果answer_dt。
-
print('Start training DT')
-
dt = DecisionTreeClassifier().fit(x_train, y_train)
-
print('Training done')
-
answer_dt = dt.predict(x_test)
-
print('Prediction done')
6)主函数——贝叶斯
使用默认参数创建贝叶斯分类器,并将训练集x_train和y_train送入fit()函数进行训练。训练后的分类
器保存到变量gnb中。
使用测试集x_test,进行分类器预测,得到分类结果answer_gnb。
-
print('Start training Bayes')
-
gnb = GaussianNB().fit(x_train, y_train)
-
print('Training done')
-
answer_gnb = gnb.predict(x_test)
-
print('Prediction done')
(5)分类结果分析
-
print('\n\nThe classification report for knn:')
-
print(classification_report(y_test, answer_knn))
-
print('\n\nThe classification report for DT:')
-
print(classification_report(y_test, answer_dt))
-
print('\n\nThe classification report for Bayes:')
-
print(classification_report(y_test, answer_gnb))
使用classification_report函数对分类结果,从精确率precision、召回率recall、f1值f1-score
和支持度support四个维度进行衡量。
分别对三个分类器的分类结果进行输出



三种算法的结果对比如下:
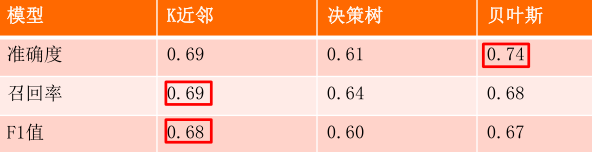
结论:
从准确度的角度衡量,贝叶斯分类器的效果最好
从召回率和F1值的角度衡量,k近邻效果最好
贝叶斯分类器和k近邻的效果好于决策树
(6)小结
在所有的特征数据中,可能存在缺失值或者冗余特征。如果将这些特征不加处理地送入后续的计算,可能会导致模型准确度下降并且增大计算量。
在特征选择阶段,通常需要借助辅助软件(例如Weka)将数据进行可视化并进行统计。
思考如何筛选冗余特征,提高模型训练效率,也可以尝试调用sklearn提供的其他分类器进行数据预测。
文章来源: andyguo.blog.csdn.net,作者:山顶夕景,版权归原作者所有,如需转载,请联系作者。
原文链接:andyguo.blog.csdn.net/article/details/104336532

- 点赞
- 收藏
- 关注作者
评论(0)