Linux操作系统

1.计算机工作模式
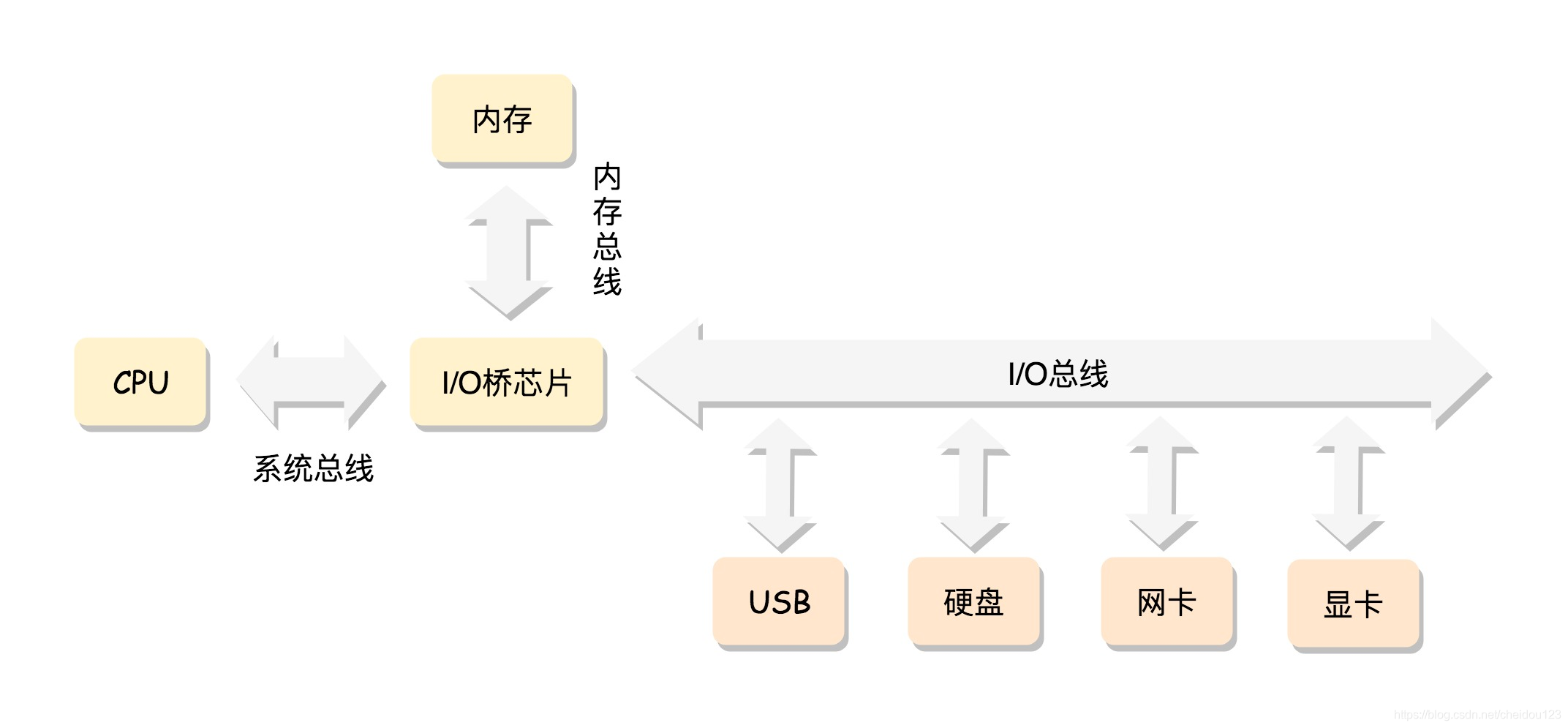
⑴CPU:
核心,和其它设备连接需要靠总线,另外很多复杂的计算任务需要将中间结果保存到内存中,CPU包含三个部分
- 运算单元 负责运算
- 数据单元 暂存数据和运算结果
- 控制单元 指挥做什么运算
⑵内存:
很多复杂的计算任务需要将中间结果保存到内存中。
⑶地址总线和数据总线
CPU和内存传数据,靠的是总线。主要有两类数据,一个是地址数据,也就是我想拿内存中哪个位置的数据,这类总线叫地址总线(Address Bus);另一类是真正的数据,这类总线叫数据总线(Data Bus)。
地址总线的位数,决定了能访问的地址范围到底有多广。例如只有两位,那CPU就只能认00,01,10,11四个位置。
而数据总线的位数,决定了一次能拿多少个数据进来。例如只有两位,那CPU一次只能从内存拿两位数。要想拿八位,就要拿四次。位数越多,一次拿的数据就越多,访问速度也就越快
2.x86架构
x86架构起源于8086处理器:
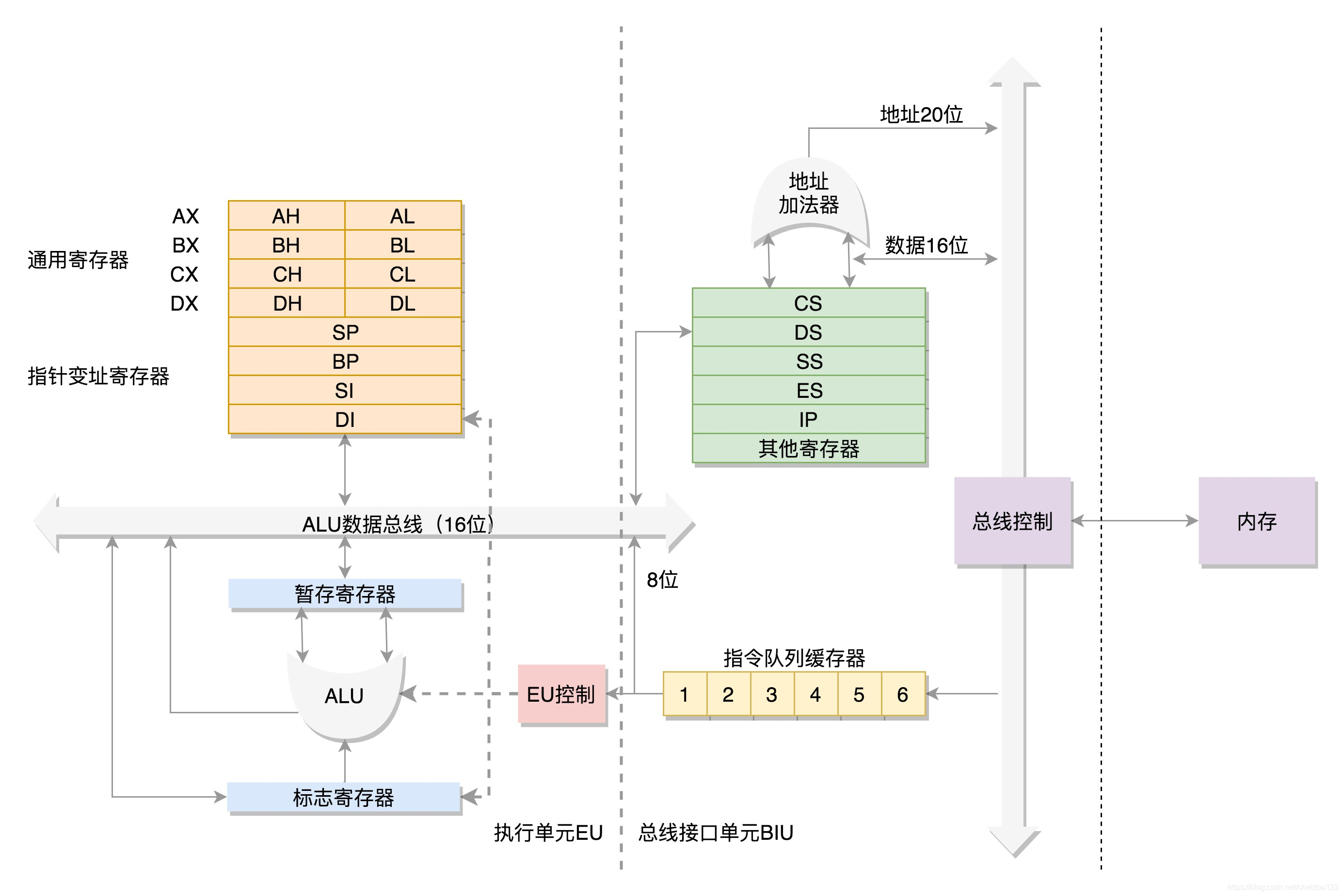
AX、BX、CX、DX、SP、BP、SI、DI主要用来暂存数据,其中AX、BX、CX、DX可以分成两个8位的寄存器来使用。
IP寄存器:指向代码段中下一条指令的位置。CPU会根据它来不断地将指令从内存的代码段中,加载到CPU的指令队列中,然后交给运算单元去执行
3.32位处理器
在32位处理器中,有32根地址总线,可以访问2^32=4G的内存
x86有两种模式:
- 实模式,只能寻址1M,每个段最多64K
- 保护模式,对于32位系统,能够寻址4G
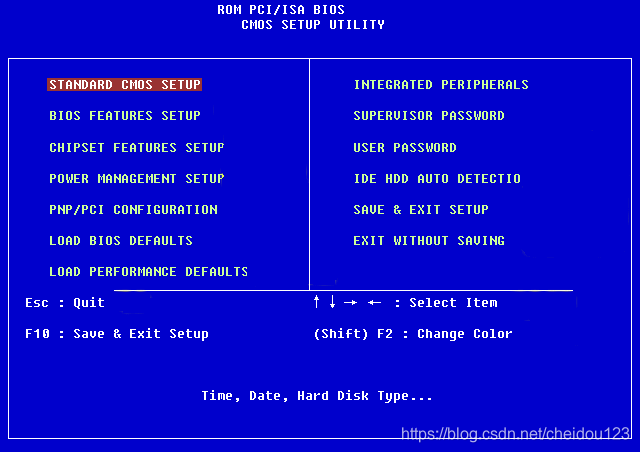
4.BIOS
在主板上,有一个只读的东西叫ROM,上面固化了一些初始化的程序,也就是BIOS。
4.进程
5.线程
使用进程的问题:
- 占用资源多
- 进程通讯需要在不同的内存空间传来传去,无法共享
线程的数据
- 线程栈上的本地数据
- 在整个进程里共享的全局数据
- 线程私有数据(比如java里面的threadLocal)
6.内存
⑴物理内存
电脑内存16GB指的是物理内存,只有内核才可以访问物理内存。
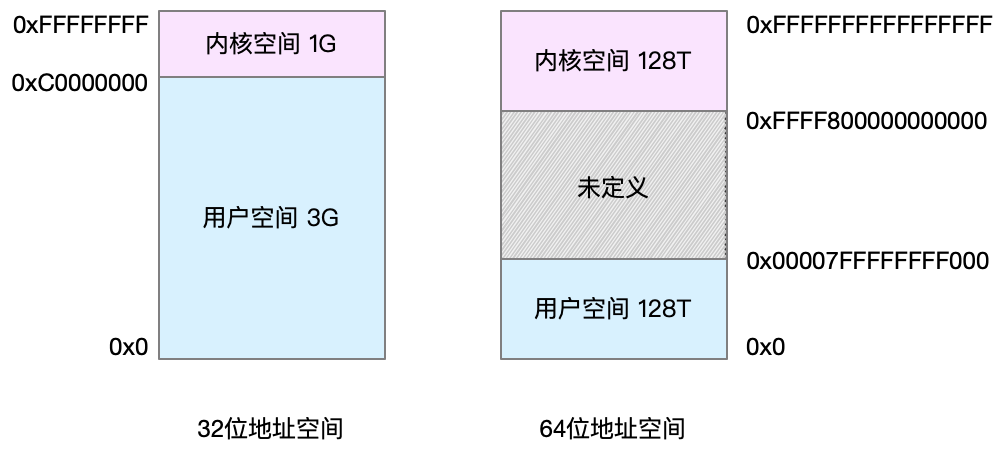
进程都有一个虚拟地址空间,访问自己的虚拟内存,虚拟地址空间又分为用户空间和内核空间。进程在用户态时,只能访问用户空间内存;只有进入内核态后,才可以访问内核空间内存。并不是所有的虚拟内存都会访分配物理内存,只要真正使用的才会分配。
⑵内存映射
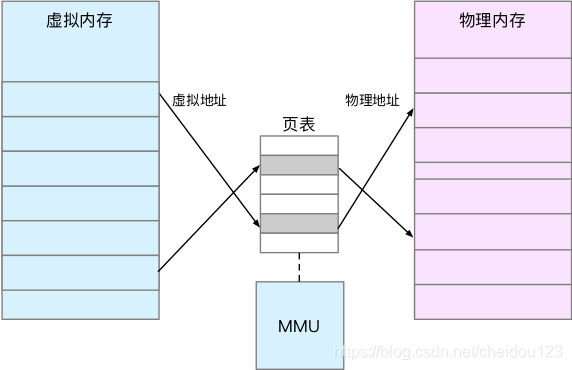
MMU是CPU的内存管理单元。TLB是 MMU 中页表的高速缓存。由于进程的虚拟地址空间是独立的,而 TLB 的访问速度又比 MMU 快得多,所以,通过减少进程的上下文切换,减少 TLB 的刷新次数,就可以提高 TLB 缓存的使用率,进而提高 CPU 的内存访问性能。
⑶虚拟内存空间分布
虚拟内存空间分为:
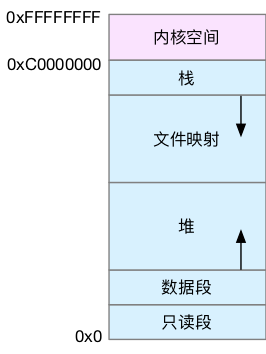
- 只读段,包括代码和常量等。
- 数据段,包括全局变量等。
- 堆,包括动态分配的内存,从低地址开始向上增长。
- 文件映射段,包括动态库、共享内存等,从高地址开始向下增长。
- 栈,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8 MB。
在这五个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存
⑷内存分配和回收
①内存分配
对小块内存(小于 128K)
C 标准库使用 brk() 来分配,可以减少缺页异常的发生,但是频繁的内存分配和释放会造成内存碎片
brk分配的内存是推_edata指针,从堆的低地址向高地址推进。这种情况下,如果高地址的内存不释放,低地址的内存是得不到释放的
而大块内存(大于 128K)
直接使用内存映射 mmap() 来分配,会在释放时直接归还系统,所以每次 mmap 都会发生缺页异常
用户空间的内存分配都是基于buddy算法(伙伴算法),并不涉及slab
②内存回收
发现内存紧张时,系统就会通过一系列机制来回收内存,比如
- 回收不常访问的内存,把不常用的内存通过交换分区直接写到磁盘中,Swap 其实就是把一块磁盘空间当成内存来用。它可以把进程暂时不用的数据存储到磁盘中(这个过程称为换出),当进程访问这些内存时,再从磁盘读取这些数据到内存中(这个过程称为换入)。通常只在内存不足时,才会发生 Swap 交换。并且由于磁盘读写的速度远比内存慢,Swap 会导致严重的内存性能问题。
- OOM,直接杀掉占用大量内存的进程
⑸Buffer和Cache
[work(caibin)@tjtx167-39-49 ~]$ free
total used free shared buffers cached
Mem: 131356876 127138940 4217936 5266204 1292 82237136
-/+ buffers/cache: 44900512 86456364
Swap: 0 0 0
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
Buffer 是对磁盘数据的缓存,通常不会特别大(20MB 左右)。这样,内核就可以把分散的写集中起来,统一优化磁盘的写入,比如可以把多次小的写合并成单次大的写等等。
而 Cache 是文件数据的缓存,它们既会用在读请求中,也会用在写请求中。是从磁盘读取文件的页缓存,也就是用来缓存从文件读取的数据。这样,下次访问这些文件数据时,就可以直接从内存中快速获取,而不需要再次访问缓慢的磁盘。
Buffer主要是读写磁盘时缓存,Cache主要是读写文件时缓存。
⑹swap
Swap 说白了就是把一块磁盘空间或者一个本地文件,当成内存来使用
Swap 把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
Java 的应用都建议关 swap,这个和 JVM 的 gc 有关,它在 gc 的时候会遍历所有用到的堆的内存,如果这部分内存是被 swap 出去了,遍历的时候就会有磁盘IO
什么时候发出swap呢?
①直接内存回收大块内存分配请求
有新的大块内存分配请求,但是剩余内存不足。这个时候系统就需要回收一部分内存(比如前面提到的缓存),进而尽可能地满足新内存请求。这个过程通常被称为直接内存回收。
②内核线程定期回收
kswapd0 定义了三个阈值(可以手动修改):
- 页最小阈值(pages_min)
- 页低阈值(pages_low)
- 页高阈值(pages_high)
剩余内存,则使用 pages_free 表示。

- 剩余内存小于页最小阈值,说明进程可用内存都耗尽了,只有内核才可以分配内存。
- 剩余内存落在页最小阈值和页低阈值中间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值为止。
- 剩余内存落在页低阈值和页高阈值中间,说明内存有一定压力,但还可以满足新内存请求。
- 剩余内存大于页高阈值,说明剩余内存比较多,没有内存压力
NUMA和SWAP:
明明发现了 Swap 升高,可是在分析系统的内存使用时,却很可能发现,系统剩余内存还多着呢。为什么剩余内存很多的情况下,也会发生 Swap 呢?
NUMA架构下的处理器是多Node模式,每个Node都有自己的本地内存空间。分析时需要每个Node单独分析。
当然,某个 Node 内存不足时,系统可以从其他 Node 寻找空闲内存,也可以从本地内存中回收内存。具体选哪种模式,你可以通过 /proc/sys/vm/zone_reclaim_mode 来调整。
swappiness
-
对文件页的回收,当然就是直接回收缓存,或者把脏页写回磁盘后再回收。
-
而对匿名页的回收,其实就是通过 Swap 机制,把它们写入磁盘后再释放内存。
Linux 提供了一个 /proc/sys/vm/swappiness 选项,用来调整使用 Swap 的积极程度。
swappiness 的范围是 0-100,数值越大,越积极使用 Swap,也就是更倾向于回收匿名页;数值越小,越消极使用 Swap,也就是更倾向于回收文件页。
虽然 swappiness 的范围是 0-100,不过要注意,这并不是内存的百分比,而是调整 Swap 积极程度的权重
7.网络
⑴C10K C100K和 C1000K
C10K 并发连接 1 万
C10K 并发连接 10 万
C1000K 并发连接 100 万
①C10K
C10K物理资源是足够的,可以通过IO模型来实现C10K
②C100K
可以通过IO模型来实现C100K
②C1000K
除了 I/O 模型之外,还需要从应用程序到 Linux 内核、再到 CPU、内存和网络等各个层次的深度优化。
文章来源: andyguo.blog.csdn.net,作者:山顶夕景,版权归原作者所有,如需转载,请联系作者。
原文链接:andyguo.blog.csdn.net/article/details/104409848

- 点赞
- 收藏
- 关注作者
评论(0)