矩阵分解和信息论基础

学习总结
一、矩阵分解
机器学习中常见的矩阵分解有特征分解和奇异值分解。
先提一下矩阵的特征值和特征向量的定义
- 若矩阵 A A A 为方阵,则存在非零向量 x x x 和常数 λ \lambda λ 满足 A x = λ x Ax=\lambda x Ax=λx,则称 λ \lambda λ 为矩阵 A A A 的一个特征值, x x x 为矩阵 A A A 关于 λ \lambda λ 的特征向量。
- A n × n A_{n \times n} An×n 的矩阵具有 n n n 个特征值, λ 1 ≤ λ 2 ≤ ⋯ ≤ λ n λ_1 ≤ λ_2 ≤ ⋯ ≤ λ_n λ1≤λ2≤⋯≤λn 其对应的n个特征向量为 𝒖 1 , 𝒖 2 , ⋯ , 𝒖 𝑛 𝒖_1,𝒖_2, ⋯ ,𝒖_𝑛 u1,u2,⋯,un
- 矩阵的迹(trace)和行列式(determinant)的值分别为
tr ( A ) = ∑ i = 1 n λ i ∣ A ∣ = ∏ i = 1 n λ i \operatorname{tr}(\mathrm{A})=\sum_{i=1}^{n} \lambda_{i} \quad|\mathrm{~A}|=\prod_{i=1}^{n} \lambda_{i} tr(A)=i=1∑nλi∣ A∣=i=1∏nλi
矩阵特征分解: A n × n A_{n \times n} An×n 的矩阵具有 n n n 个不同的特征值,那么矩阵A可以分解为 A = U Σ U T A = U\Sigma U^{T} A=UΣUT.
其中 Σ = [ λ 1 0 ⋯ 0 0 λ 2 ⋯ 0 0 0 ⋱ ⋮ 0 0 ⋯ λ n ] U = [ u 1 , u 2 , ⋯ , u n ] ∥ u i ∥ 2 = 1 \Sigma=\left[
奇异值分解:对于任意矩阵 A m × n A_{m \times n} Am×n,存在正交矩阵 U m × m U_{m \times m} Um×m 和 V n × n V_{n \times n} Vn×n,使其满足 A = U Σ V T U T U = V T V = I A = U \Sigma V^{T} \quad U^T U = V^T V = I A=UΣVTUTU=VTV=I,则称上式为矩阵 A A A 的特征分解。
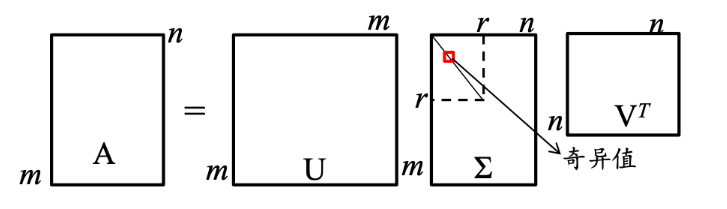
二、信息论
熵(Entropy)
信息熵,可以看作是样本集合纯度一种指标,也可以认为是样本集合包含的平均信息量。
假定当前样本集合X中第i类样本 𝑥 𝑖 𝑥_𝑖 xi 所占的比例为 P ( 𝑥 𝑖 ) ( i = 1 , 2 , . . . , n ) P(𝑥_𝑖)(i=1,2,...,n) P(xi)(i=1,2,...,n),则X的信息熵定义为:
H ( X ) = − ∑ i = 1 n P ( x i ) log 2 P ( x i ) H(X) = -\sum_{i = 1}^n P(x_i)\log_2P(x_i) H(X)=−i=1∑nP(xi)log2P(xi)
H(X)的值越小,则X的纯度越高,蕴含的不确定性越少
联合熵
两个随机变量X和Y的联合分布可以形成联合熵,度量二维随机变量XY的不确定性:
H ( X , Y ) = − ∑ i = 1 n ∑ j = 1 n P ( x i , y j ) log 2 P ( x i , y j ) H(X, Y) = -\sum_{i = 1}^n \sum_{j = 1}^n P(x_i,y_j)\log_2 P(x_i,y_j) H(X,Y)=−i=1∑nj=1∑nP(xi,yj)log2P(xi,yj)
条件熵
在随机变量X发生的前提下,随机变量Y发生带来的熵,定义为Y的条件熵,用H(Y|X)表示,定义为:
H ( Y ∣ X ) = ∑ i = 1 n P ( x i ) H ( Y ∣ X = x i ) = − ∑ i = 1 n P ( x i ) ∑ j = 1 n P ( y j ∣ x i ) log 2 P ( y j ∣ x i ) = − ∑ i = 1 n ∑ j = 1 n P ( x i , y j ) log 2 P ( y j ∣ x i )
条件熵用来衡量在已知随机变量X的条件下,随机变量Y的不确定。 熵、联合熵和条件熵之间的关系: H ( Y ∣ X ) = H ( X , Y ) − H ( X ) H(Y|X) = H(X,Y)-H(X) H(Y∣X)=H(X,Y)−H(X).
互信息
I ( X ; Y ) = H ( X ) + H ( Y ) − H ( X , Y ) I(X;Y) = H(X)+H(Y)-H(X,Y) I(X;Y)=H(X)+H(Y)−H(X,Y)
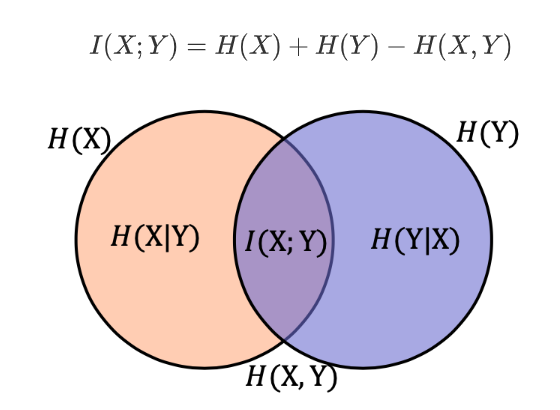
相对熵
相对熵又称KL散度,是描述两个概率分布P和Q差异的一种方法,记做D(P||Q)。在信息论中,D(P||Q)表示用概率分布Q来拟合真实分布P时,产生的信息表达的损耗,其中P表示信源的真实分布,Q表示P的近似分布。
- 离散形式: D ( P ∣ ∣ Q ) = ∑ P ( x ) log P ( x ) Q ( x ) D(P||Q) = \sum P(x)\log \frac{P(x)}{Q(x)} D(P∣∣Q)=∑P(x)logQ(x)P(x).
- 连续形式: D ( P ∣ ∣ Q ) = ∫ P ( x ) log P ( x ) Q ( x ) D(P||Q) = \int P(x)\log \frac{P(x)}{Q(x)} D(P∣∣Q)=∫P(x)logQ(x)P(x).
交叉熵
一般用来求目标与预测值之间的差距,深度学习中经常用到的一类损失函数度量,比如在对抗生成网络( GAN )中
D ( P ∥ Q ) = ∑ P ( x ) log P ( x ) Q ( x ) = ∑ P ( x ) log P ( x ) − ∑ P ( x ) log Q ( x ) = − H ( P ( x ) ) − ∑ P ( x ) log Q ( x )
交叉熵: H ( P , Q ) = − ∑ P ( x ) log Q ( x ) H(P,Q) = -\sum P(x)\log Q(x) H(P,Q)=−∑P(x)logQ(x).
文章来源: andyguo.blog.csdn.net,作者:山顶夕景,版权归原作者所有,如需转载,请联系作者。
原文链接:andyguo.blog.csdn.net/article/details/121392339

- 点赞
- 收藏
- 关注作者
评论(0)