【王喆-推荐系统】线上服务篇-(task5)部署离线模型

学习总结
(1)业界主流的模型服务方法有 4 种,分别是预存推荐结果或 Embeding 结果、预训练 Embeding+ 轻量级线上模型、利用 PMML 转换和部署模型以及 TensorFlow Serving。
(2)重点使用基于Docker的 TensorFlow Serving 服务,它是 End2End 的解决方案,使用起来非常方便、高效,而且它支持绝大多数 TensorFlow 的模型结构,对于深度学习推荐系统来说,是一个非常好的选择。
(3)但 TensorFlow Serving 只支持 TensorFlow 模型,而且针对线上服务的性能问题,需要进行大量的优化。TensorFlow serving本身在高并发下有一定的性能问题,有一些坑,各一线团队都在进行一些魔改。
一、业界的主流模型服务方法
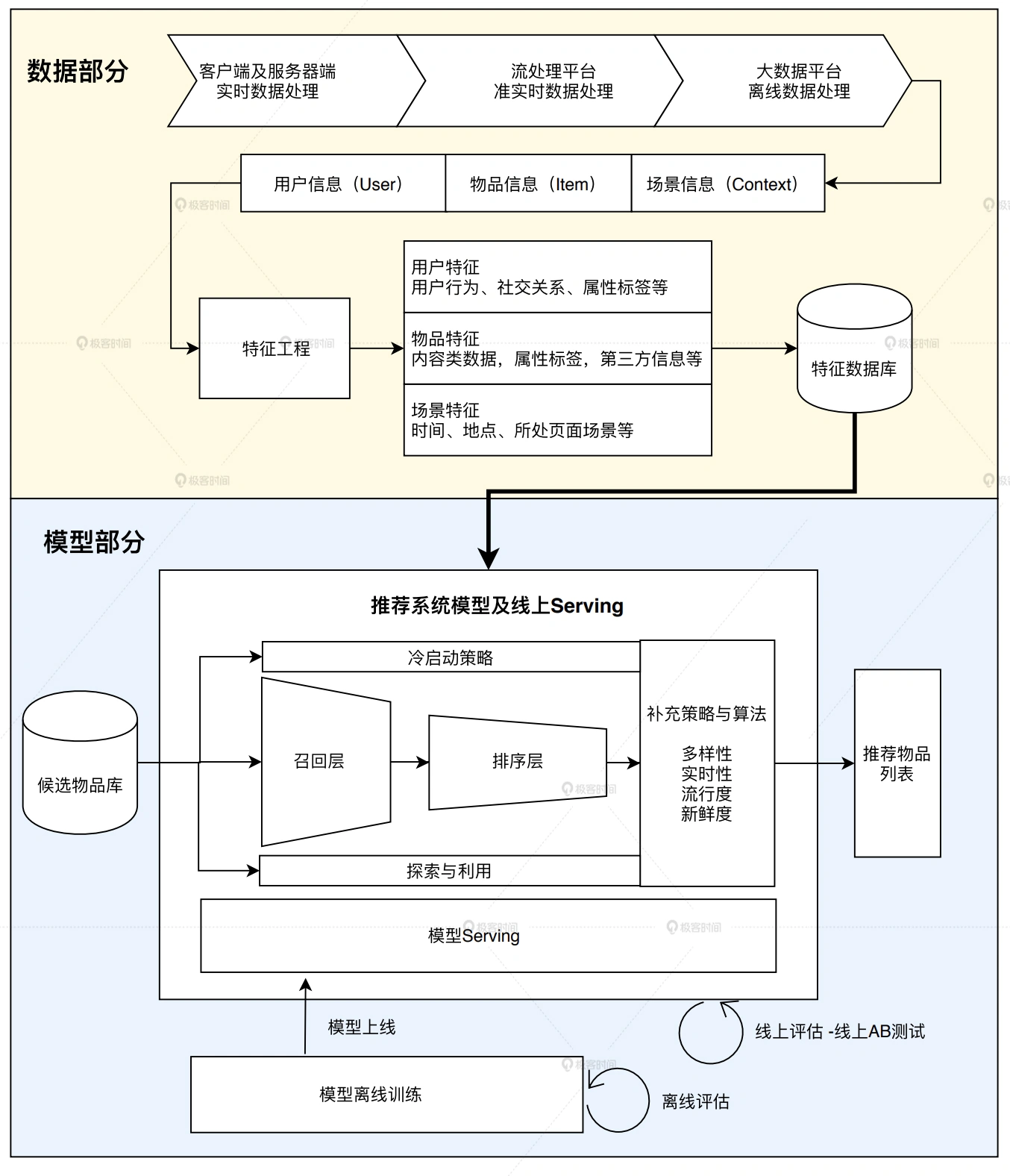
在实验室的环境下,我们经常使用 Spark MLlib、TensorFlow、PyTorch 这些流行的机器学习库来训练模型,因为不用直接服务用户,所以往往得到一些离线的训练结果就觉得大功告成了。但在业界的生产环境中,模型需要在线上运行,实时地根据用户请求生成模型的预估值。这个把模型部署在线上环境,并实时进行模型推断(Inference)的过程就是模型服务。
业界主流的模型服务方法有 4 种,分别是预存推荐结果或 Embedding 结果、预训练 Embedding+ 轻量级线上模型、PMML 模型以及 TensorFlow Serving。
二、预存推荐结果或Embedding
对于推荐系统线上服务来说,最简单直接的模型服务方法就是在离线环境下生成对每个用户的推荐结果,然后将结果预存到以 Redis 为代表的线上数据库中。这样,我们在线上环境直接取出预存数据推荐给用户即可。
适用场景:只适用于用户规模较小,或者一些冷启动、热门榜单等特殊的应用场景中。

用户规模大时,为了减少模型存储所需空间,可以通过存储embedding来替代直接存储推荐结果,而在线上则利用embedding计算相似度得到推荐结果。在【特征工程篇】就通过 Item2vec、Graph Embedding 等方法生成物品 Embedding,再存入 Redis 供线上使用的过程,这就是预存 Embedding 的模型服务方法的典型应用。
缺点:由于完全基于线下计算出 Embedding,这样的方式无法支持线上场景特征的引入,并且无法进行复杂模型结构的线上推断,表达能力受限。因此对于复杂模型,我们还需要从模型实时线上推断的角度入手,来改进模型服务的方法。
三、预训练Embedding+轻量级线上模型
上一个方法不太行的原因:仅仅采用了“相似度计算”这样非常简单的方式去得到最终的推荐分数。
所以想到在线上实现一个比较复杂的操作,甚至是用神经网络来生成最终的预估值——预训练 Embedding+ 轻量级线上模型。
具体:用复杂深度学习网络离线训练生成 Embedding,存入内存数据库,再在线上实现逻辑回归或浅层神经网络等轻量级模型来拟合优化目标。
【栗子】阿里的推荐模型 MIMN(Multi-channel user Interest Memory Network,多通道用户兴趣记忆网络)的结构。神经网络,才是真正在线上服务的部分。
不需要纠结于复杂模型的结构细节,你只要知道左边的部分不管多复杂,它们其实是在线下训练生成的,而右边的部分是一个经典的多层神经网络,它才是真正在线上服务的部分。

(1)有两个被虚线框框住的数据结构,分别是 S(1)-S(m) 和 M(1)-M(m)——其实就是在离线生成的 Embedding 向量,在 MIMN 模型中,它们被称为“多通道用户兴趣向量”,这些 Embedding 向量就是连接离线模型和线上模型部分的接口。
(2)线上部分从redis数据库拿到这些embedding后,和其他特征的embedding向量组合,扔给一个标准的多层神经网络进行预估。
优点:隔离了离线模型的复杂性和线上推断的效率要求。
四、利用PMML转换和部署模型
上一个方法不完全是 End2End(端到端)训练 +End2End 部署这种最“完美”的方式。
还有一种方法是脱离于平台的通用模型部署方式,PMML。
“预测模型标记语言”(Predictive Model Markup Language, PMML),它是一种通用的以 XML 的形式表示不同模型结构参数的标记语言。在模型上线的过程中,PMML 经常作为中间媒介连接离线训练平台和线上预测平台。
以 Spark MLlib 模型的训练和上线过程为例:
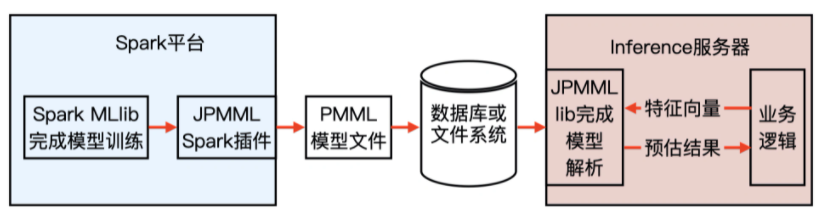
PMML 在整个机器学习模型训练及上线流程中扮演的角色:
例子使用了 JPMML 作为序列化和解析 PMML 文件的 library(库),JPMML 项目分为 Spark 和 Java Server 两部分。Spark 部分的 library 完成 Spark MLlib 模型的序列化,生成 PMML 文件,并且把它保存到线上服务器能够触达的数据库或文件系统中,而 Java Server 部分则完成 PMML 模型的解析,生成预估模型,完成了与业务逻辑的整合。
JPMML 在 Java Server 部分只进行推断,不考虑模型训练、分布式部署等一系列问题,因此 library 比较轻,能够高效地完成推断过程。与 JPMML 相似的开源项目还有 MLeap,同样采用了 PMML 作为模型转换和上线的媒介。
PS:JPMML 和 MLeap 也具备 Scikit-learn、TensorFlow 等简单模型的转换和上线能力。
JPMML :https://github.com/jpmml
MLeap:https://github.com/combust/mleap
五、实战搭建 TensorFlow Serving 模型服务
PMML 语言的表示能力还是比较有限的,还不足以支持复杂的深度学习模型结构。想要上线 TensorFlow 模型,我们就需要借助 TensorFlow 的原生模型服务模块,也就是 TensorFlow Serving 的支持。
TensorFlow Serving 和 PMML 类工具的流程一致,它们都经历了模型存储、模型载入还原以及提供服务的过程。
在具体细节上:TensorFlow 在离线把模型序列化,存储到文件系统,TensorFlow Serving 把模型文件载入到模型服务器,还原模型推断过程,对外以 HTTP 接口或 gRPC 接口的方式提供模型服务。

具体到 Sparrow Recsys 项目中(上图):我们会在离线使用 TensorFlow 的 Keras 接口完成模型构建和训练,再利用 TensorFlow Serving 载入模型,用 Docker 作为服务容器,然后在 Jetty 推荐服务器中发出 HTTP 请求到 TensorFlow Serving,获得模型推断结果,最后推荐服务器利用这一结果完成推荐排序。
5.1 安装 Docker
本次学习选用了 TensorFlow Serving 作为模型服务的技术方案,它们可以说是整个推荐系统的核心了。
TensorFlow Serving 最普遍、最便捷的服务方式就是使用 Docker 建立模型服务 API。
Docker介绍:(官网:https://www.docker.com/get-started)
Docker 是一个开源的应用容器引擎,你可以把它当作一个轻量级的虚拟机。它可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的操作系统,比如 Linux/Windows/Mac 的机器上。Docker 容器相互之间不会有任何接口,而且容器本身的开销极低,这就让 Docker 成为了非常灵活、安全、伸缩性极强的计算资源平台。
因为 TensorFlow Serving 对外提供的是模型服务接口,所以使用 Docker 作为容器的好处主要有两点:
一是可以非常方便的安装(上面官网链接);
二是在模型服务的压力变化时,可以灵活地增加或减少 Docker 容器的数量,做到弹性计算,弹性资源分配。
不仅可以通过图形界面打开并运行 Docker,而且可以通过命令行来进行 Docker 相关的操作。
验证你是否安装成功:打开命令行输入 docker --version 命令,它能显示出类似“Docker version 19.03.13, build 4484c46d9d”这样的版本号,就说明你的 Docker 环境已经准备好了。
【安装docker的坑】
(1)官网下载docker:
https://www.docker.com/get-started
(2)菜鸟教程:
https://www.runoob.com/docker/ubuntu-docker-install.html
我参考这个教程,直接在ubuntu上curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun就ok了,这里会使用官方的脚本自动安装好(出现一排sudo就慢慢等好了hh)。
然后输入docker --version,显示如下版本号说明安装成功:
Docker version 20.10.10, build b485636
- 1
(3)Docker容器启动失败 Failed to start Docker Application Container Engine的解决办法:
https://www.cnblogs.com/huhyoung/p/9495956.html
或者参考:docker正常安装成功,但是启动服务报错Failed to startDocker……Engine
或者参考Stack Overflow:
https://stackoverflow.com/questions/66091744/docker-failed-to-start
(4)卸载docker:在window10上彻底卸载docker
安装也可以参考docker 入坑(win10和Ubuntu 安装)
5.2 建立 TensorFlow Serving 服务
PS:搞tensorflow serving服务中遇到的困难可以参考官网。
首先,我们要利用 Docker 命令拉取 TensorFlow Serving 的镜像(如果不行就加上sudo):
# 从docker仓库中下载tensorflow/serving镜像
docker pull tensorflow/serving
- 1
- 2
再从 TenSorflow 的官方 GitHub 地址下载 TensorFlow Serving 相关的测试模型文件:
# 把tensorflow/serving的测试代码clone到本地
git clone https://github.com/tensorflow/serving
# 指定测试数据的地址
TESTDATA="$(pwd)/serving/tensorflow_serving/servables/tensorflow/testdata"
- 1
- 2
- 3
- 4
最后,我们在 Docker 中启动一个包含 TensorFlow Serving 的模型服务容器,并载入我们刚才下载的测试模型文件 half_plus_two:
# 启动TensorFlow Serving容器,在8501端口运行模型服务API
docker run -t --rm -p 8501:8501 \
-v "$TESTDATA/saved_model_half_plus_two_cpu:/models/half_plus_two" \
-e MODEL_NAME=half_plus_two \
tensorflow/serving &
- 1
- 2
- 3
- 4
- 5
我的ubuntu设置的路径后的命令应该是(不过好像有点问题,回头看这个):
# 启动TensorFlow Serving容器,在8501端口运行模型服务API
docker run -t --rm -p 8501:8501 \
-v "/Desktop/serving/tensorflow_serving/servables/tensorflow/testdata/saved_model_half_plus_two_cpu/models/half_plus_two" \
-e MODEL_NAME=half_plus_two \
tensorflow/serving &
- 1
- 2
- 3
- 4
- 5
在命令执行完成后,如果你在 Docker 的管理界面(window版本)中看到了 TenSorflow Serving 容器,如下图所示,就证明 TensorFlow Serving 服务被你成功建立起来了。而如果是用ubuntu的linux系统,则可以使用docker的图形化Portainer容器。
注意关闭docker服务是:service docker stop,其他常用的docker命令总结。
5.3 请求 TensorFlow Serving 获得预估结果
验证一下是否能够通过 HTTP 请求从 TensorFlow Serving API 中获得模型的预估结果:
(1)可以通过 curl 命令来发送 HTTP POST 请求到 TensorFlow Serving 的地址;
(2)或者利用 Postman 等软件来组装 POST 请求进行验证。
# 请求模型服务API
curl -d '{"instances": [1.0, 2.0, 5.0]}' \
-X POST http://localhost:8501/v1/models/half_plus_two:predict
- 1
- 2
- 3
返回结果如下,就说明 TensorFlow Serving 服务已经成功建立起来了。
# 返回模型推断结果如下
# Returns => { "predictions": [2.5, 3.0, 4.5] }
- 1
- 2
PS:上面只是使用了 TensorFlow Serving 官方自带的一个测试模型,来将怎么准备环境。在推荐模型实战的时候,还会基于 TensorFlow 构建多种不同的深度学习模型,到时候 TensorFlow Serving 就会派上关键的用场了。
六、作业
你是如何在自己的项目中进行模型服务的吗?你还用过哪些模型服务的方法?
七、课后答疑
(1)在window7上面通过docker toolbox安装好了docker,然后在docker toolbox上pull tensorflow serving镜像。再把tensorflow测试模型文件下载到本地,并配置TESTDATA地址,然后docker run服务。最后报错了:error response form daemon: invalid mode: /models/half_plus_two。
【答】估计还是TESTDATA的路径问题,参考这篇文章https://stackoverflow.com/questions/50540721/docker-toolbox-error-response-from-daemon-invalid-mode-root-docker。
(2)建议:第一步初次安装的国内小伙伴,添加Docker 引擎源加快拉取数据:
{
"experimental": true,
"debug": true,
"registry-mirrors": [
"http://hub-mirror.c.163.com"
]
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(3)请问tf serving怎么解决预训练embedding+轻量级预估的问题呢,如果用tf serving方案,MIMN不还是割裂的两部分吗,并不是端到端的啊。
【答】tf serving并不是说不能做MIMN的end2end serving,而是因为MIMN做e2e serving太慢了,所以把它割裂成两部分,这是一个优化的过程。
这块没必要钻牛角尖,我们这里说的是tf serving有e2e serving的能力,真正的工业级环境,当然是要做各种优化的。
(4)git clone tf-serving不可用,failed,网上找的以下这个可以:
git clone --recurse-submodules https://github.com/tensorflow/serving
(5)下面这个TESTDATA这句命令也是直接在command Prompt里直接打么,我试了,得到错误信息“TESTDATA is not recognized as an internal or external command…” 是不是应该在别的地方打这句啊?
TESTDATA="$(pwd)/serving/tensorflow_serving/servables/tensorflow/testdata"
【答】这句是配置一个变量,如果不打的话,你把serving/tensorflow_serving/servables/tensorflow/testdata 的完整绝对路径替换后面命令的TESTDATA也可以
(6)在Windows下的Git命令行里照着输入这些指令碰到了下面的问题,运行docker run那个指令报错:
E tensorflow_serving/sources/storage_path/file_system_storage_path_source.cc:364] FileSystemStoragePathSource encountered a filesystem access error: Could not find base path /models/half_plus_two for servable half_plus_two
报错说找不到模型文件。
原因:$TESTDATA这里的路径前面是"/c:/xxx/"这种,识别不了
解决方法:手动输入路径,把c盘前面的’/'符号去掉,就本来是‘/c:/xxx/xxx’改成‘c:/xxx/xxx’就可以了
【另外】curl就本文中提到的命令中,windows下引号需要转义,
curl -d ‘{“instances”: [1.0, 2.0, 5.0]}’
变成curl -d “{“instances”: [1.0, 2.0, 5.0]}” ,后面不变。
Windows 下curl转义可以参考https://stackoverflow.com/questions/58788793/curl-query-to-tensorflow-serving-model-to-predict-api-breaks
Reference
(1)https://github.com/wzhe06/Reco-papers
(2)《深度学习推荐系统实战》,王喆
(3)docker图形化Portainer
(4)基础服务系列-安装TensorFlow Serving
(5)Tensorflow Serving: no versions of servable half_plus_two found under base path /models
文章来源: andyguo.blog.csdn.net,作者:山顶夕景,版权归原作者所有,如需转载,请联系作者。
原文链接:andyguo.blog.csdn.net/article/details/121031616

- 点赞
- 收藏
- 关注作者
评论(0)