【王喆-推荐系统】模型篇-(task3)环境准备+数据处理

学习总结
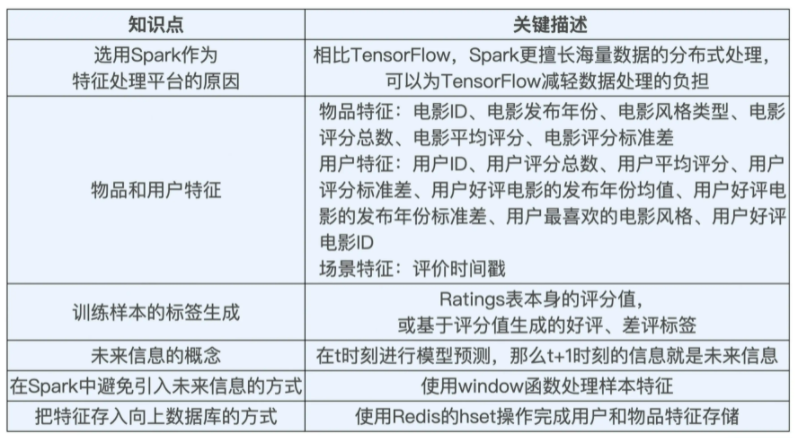
(1)在选择具体特征的过程中,我们遵循了“物品特征”、“用户特征”、“场景特征”这三大类特征分类方式,基于 MovieLens 的 用户评分数据ratings 表和 电影基本数据movies 表完成了特征抽取。
(2)在样本处理过程中,我们选用评分和基于评分生成的好评差评标识作为样本标签(PS:业界更多使用 CTR 预估这类解决二分类问题的模型去解决推荐问题),并基于 ratings 表的每条数据,通过联合物品和用户数据生成训练样本。
(3)在训练样本的生成中,注意“未来信息”的问题,利用 Spark 中的 window 函数滑动生成历史行为相关特征。最后我们利用 Redis 的 hset 操作把线上推断用的特征存储 Redis。
一、2种Tensorflow环境配置
虽然之前本地IDE的tensorflow已经配过了,但是课程学习最好使用下面这两种方法(IDEA配合我们之前学习的spark、scala代码等)。sparrow项目最好用Tensorflow r2.3 python3.7。
1.1 Docker+Jupyter
TensorFlow 官方已经为我们准备好了它专用的 Docker 镜像,只要运行下面两行代码,就可以拉取并运行最新的 TensorFlow 版本,还能在 http://localhost:8888/ 端口运行起 Jupyter Notebook。
docker pull tensorflow/tensorflow:latest
# Download latest stable image
docker run -it -p 8888:8888 tensorflow/tensorflow:latest-jupyter
# Start Jupyter server
- 1
- 2
- 3
- 4
1.2 IDEA调试代码
(1)安装 IDEA 的 Python 编译器插件
因为 IDEA 默认不支持 Python 的编译,所以我们需要为它安装 Python 插件。具体的安装路径是点击顶部菜单的 IntelliJ IDEA -> Preferences -> Plugins -> 输入 Python -> 选择插件 Python Community Edition 进行安装。
(2)安装本地 Python 环境
使用Anaconda来创建不同 Python 的虚拟环境,这样就可以为 SparrowRecsys 项目,专门创建一个使用 Python3.7 和支持 TensorFlow2.3 的虚拟 Python 环境了。
官网:https://docs.anaconda.com/anaconda/user-guide/tasks/tensorflow/
首先,Anaconda 的官方地址 下载并安装 Anaconda(最新版本使用 Python3.8,也可以去历史版本中安装 Python3.7 的版本)。然后,如果你是 Windows 环境,就打开 Anaconda Command Prompt,如果是 Mac 或 Linux 环境,打开 terminal输入下面命令:
conda create -n tf tensorflow
conda activate tf
- 1
- 2
如果是有 GPU 环境的同学,可以把命令中的tensorflow替换为tensorflow-gpu。
(3)配置 IDEA 的项目 Python 环境
第一步,在 IDEA 中添加项目 Python SDK。直接按照给出的这个路径配置就可以了:File->Project Structure -> SDKs -> 点击 + 号 ->Add Python SDK ,这个路径在操作界面的显示如图 3。
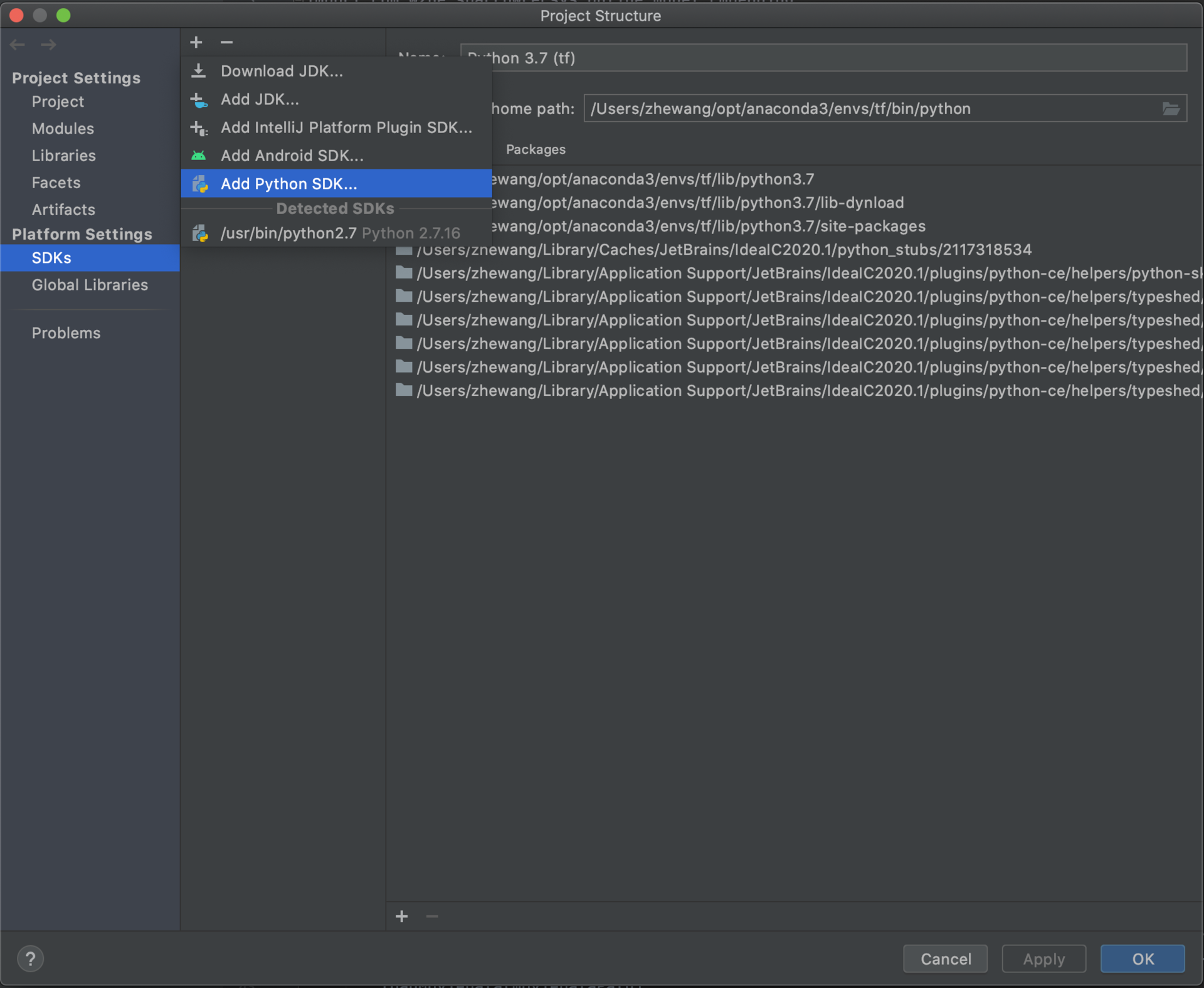
添加完 Python SDK 之后,我们配置 Conda Environment 为项目的 Python SDK。IDEA 会自动检测到系统的 Conda 环境相关路径,选择按照自动填充的路径就好,具体的操作可以看下图 4。
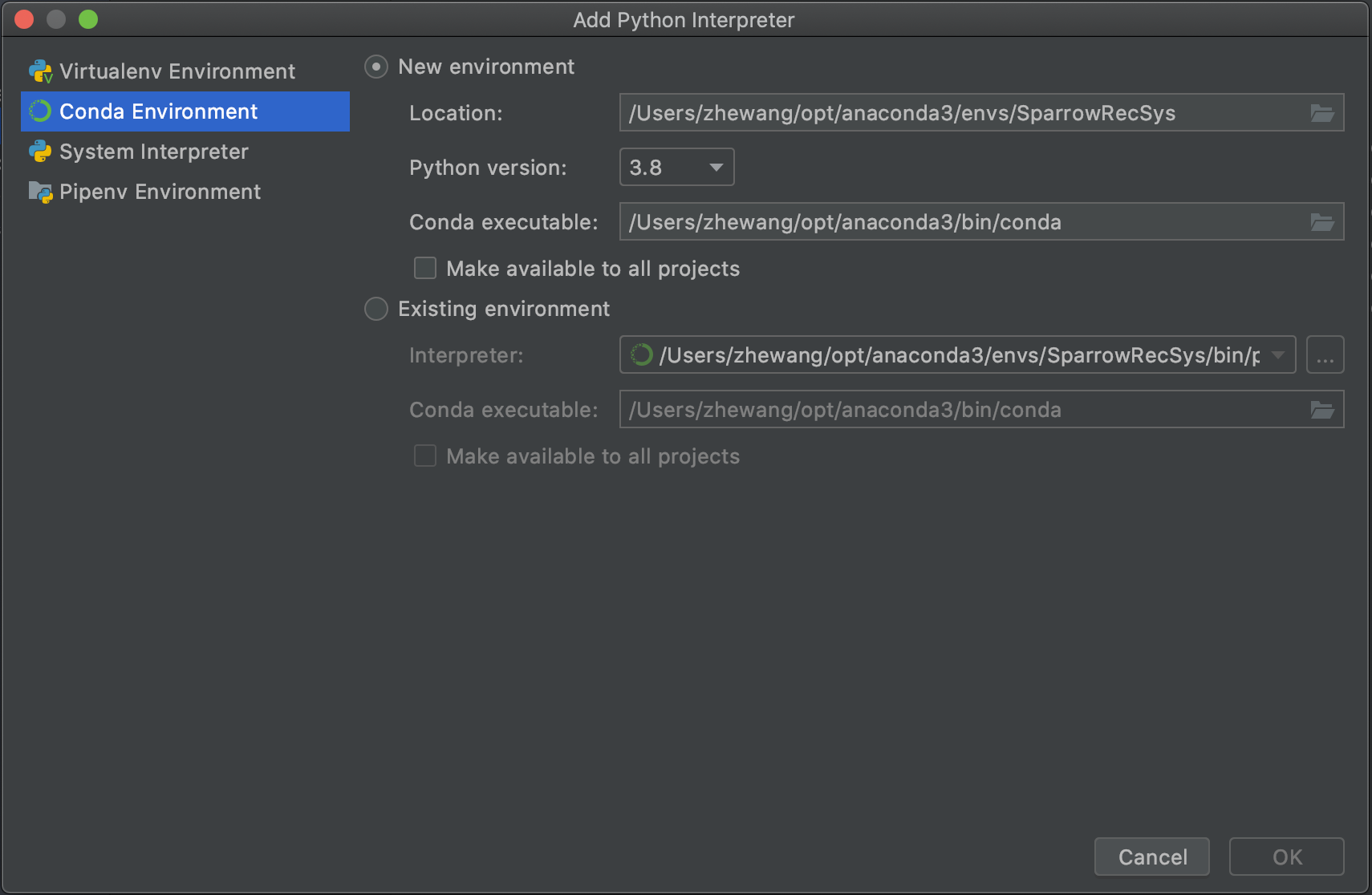
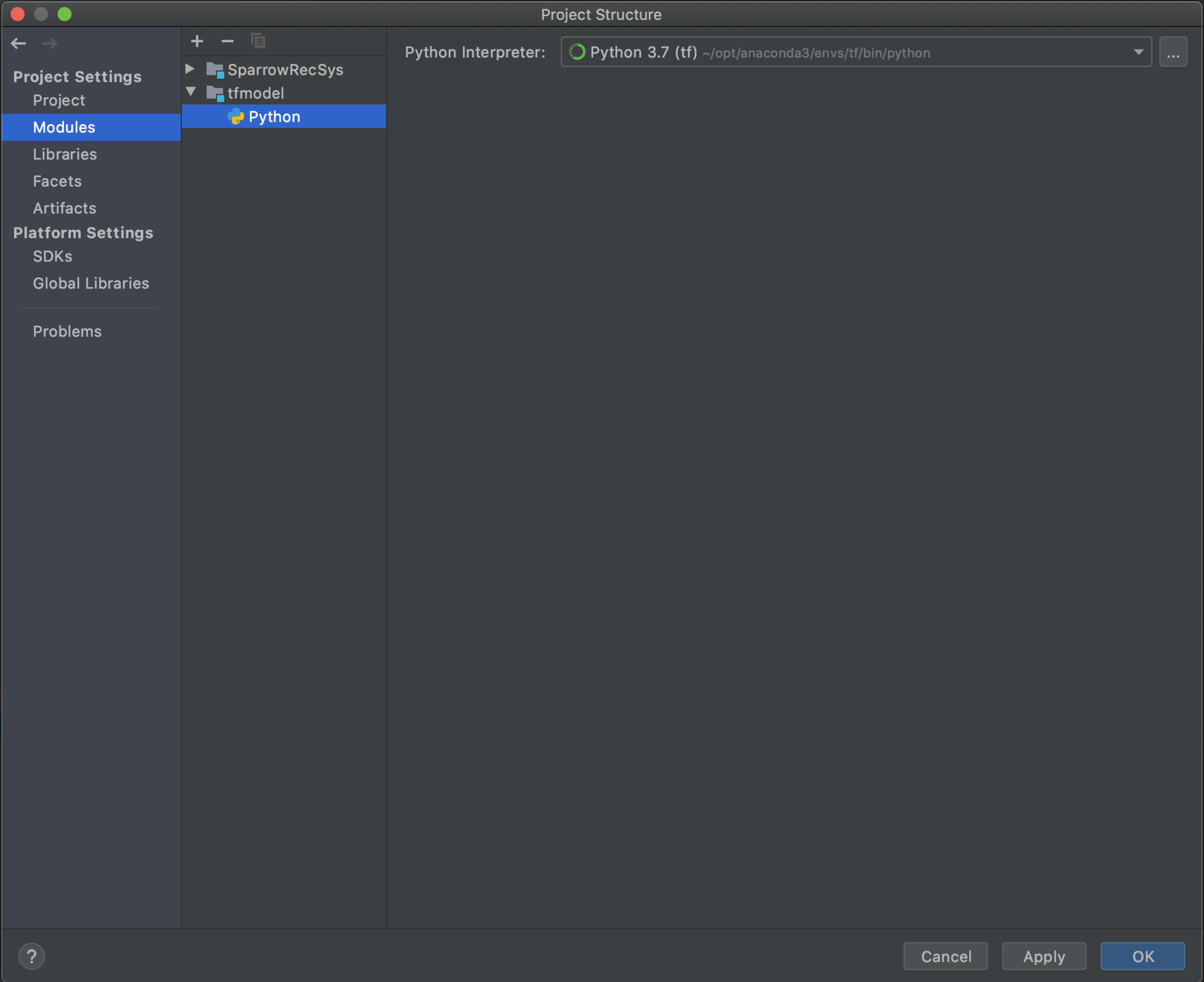
最后,我们为 TFRecModel 模块配置 Python 环境。我们选择 Project Structure Modules 部分的 TFRecModel 模块,在其上点击右键来 Add Python。
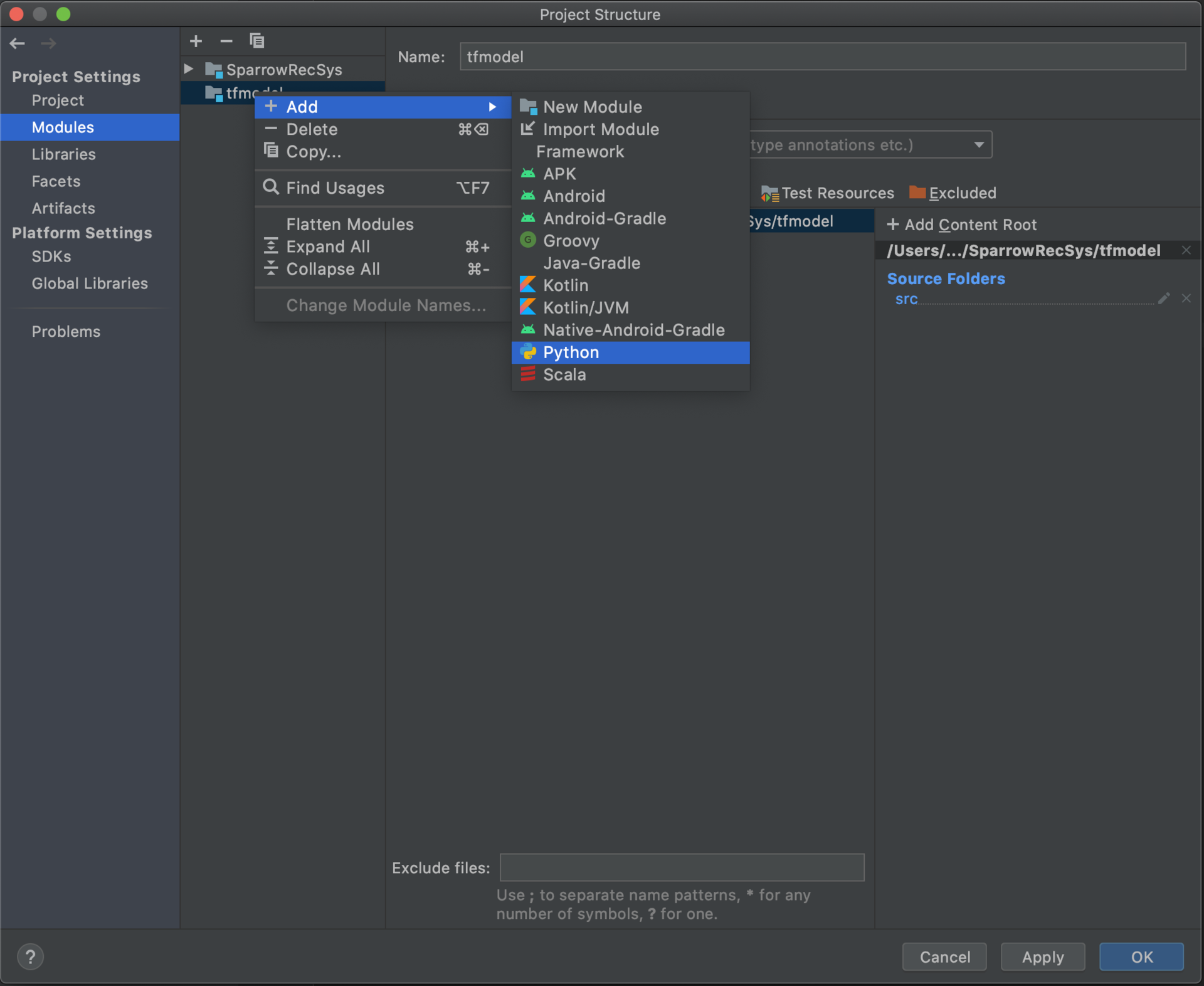
设置好的 TFRecModel 模块的 Python 环境应该如下图所示。
在业界的实践中,我们需要记住一个原则,就是让合适的平台做合适的事情。比如说,数据处理是 Spark 的专长,流处理是 Flink 的专长,构建和训练模型是 TensorFlow 的专长。在使用这些平台的时候,我们最好能够用其所长,避其所短。这也是一个业界应用拥有那么多个模块、平台的原因。
TensorFlow 也可以处理数据,但并不擅长分布式的并行数据处理,在并行数据处理能力上,TensorFlow 很难和动辄拥有几百上千个节点的 Spark 相比。那在面对海量数据的时候,我们利用 Spark 进行数据清洗、数据预处理、特征提取。
二、物品和用户特征
MovieLens 数据集中,可供我们提取特征的数据表有两个,分别是 movies 表和 ratings 表,它们的数据格式如下:
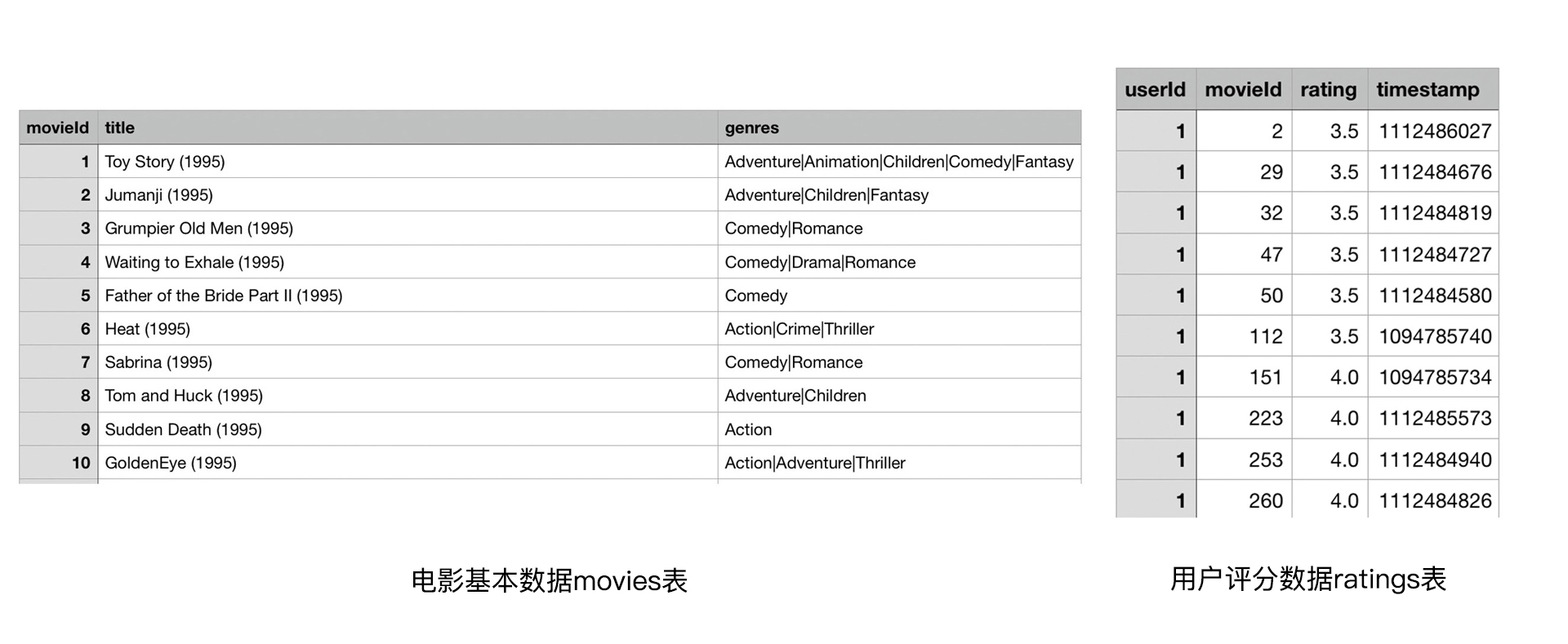
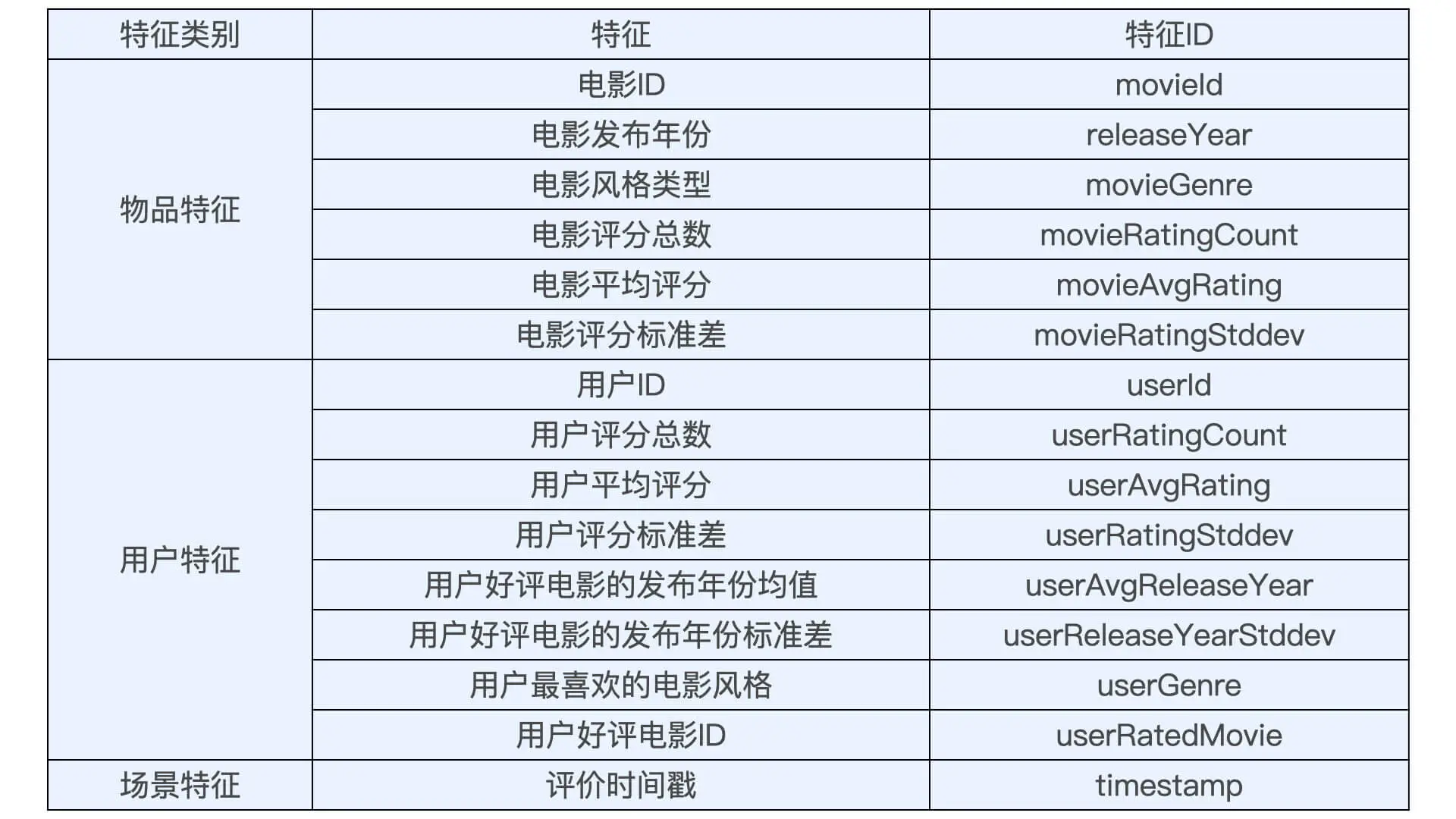
物品特征:即电影特征,从movies表中提取出movieid、title(电影名)、发布年份和风格类型。还可以利用统计类的特征,如电影的平均评分、评分标准差等。
用户特征:用户特征最重要的部分是历史行为特征。
可以根据 ratings 表的历史联合 movies 表的电影信息,提取出用户统计类特征,它包括用户评分总数、用户平均评分、用户评分标准差、用户好评电影的发布年份均值、用户好评电影的发布年份标准差、用户最喜欢的电影风格,以及用户好评电影 ID 等等。
场景特征:评分的时间戳。
代码参考:SparrowRecsys 项目中的 com.wzhe.sparrowrecsys.offline.spark.featureeng.FeatureEngForRecModel 对象,举例:
val movieRatingFeatures = samplesWithMovies3.groupBy(col("movieId"))
.agg(count(lit(1)).as("movieRatingCount"),
avg(col("rating")).as("movieAvgRating"),
stddev(col("rating")).as("movieRatingStddev"))
- 1
- 2
- 3
- 4
几个计算统计型特征的典型方法:
利用 Spark 中的 groupBy 操作,将原始评分数据按照 movieId 分组,然后用 agg 聚合操作来计算一些统计型特征。比如,在上面的代码中,我们就分别使用了 count 内置聚合函数来统计电影评价次数(movieRatingCount),用 avg 函数来统计评分均值(movieAvgRating),以及使用 stddev 函数来计算评价分数的标准差(movieRatingStddev)。
一般来说,我们不会人为预设哪个特征有用,哪个特征无用,而是让模型自己去判断,如果一个特征的加入没有提升模型效果,我们再去除这个特征。就像刚才虽然提取了不少特征,但并不是说每个模型都会使用全部的特征,而是根据模型结构、模型效果有针对性地部分使用它们。
三、最终的训练样本
明确两件事情,一是样本从哪里来,二是样本的标签是什么。
3.1 样本从哪里来
对于一个推荐模型来说,它的根本任务是预测一个用户 U 对一个物品 I 在场景 C 下的喜好分数。所以在训练时,我们要为模型生成一组包含 U、I、C 的特征,以及最终真实得分的样本。在 SparrowRecsys 中,这样的样本就是基于评分数据 ratings,联合用户、物品特征得来的。
用户特征和物品特征都需要我们提前生成好,然后让它们与 ratings 数据进行 join 后,生成最终的训练样本,具体的实现也在 FeatureEngForRecModel 中,关键代码:
//读取原始ratings数据
val ratingSamples = spark.read.format("csv").option("header", "true").load(ratingsResourcesPath.getPath)
//添加样本标签
val ratingSamplesWithLabel = addSampleLabel(ratingSamples)
//添加物品(电影)特征
val samplesWithMovieFeatures = addMovieFeatures(movieSamples, ratingSamplesWithLabel)
//添加用户特征
val samplesWithUserFeatures = addUserFeatures(samplesWithMovieFeatures)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.2 样本标签
对于 MovieLens 数据集来说,用户对电影的评分是最直接的标签数据,因为它就是我们想要预测的用户对电影的评价,所以 ratings 表中的 0-5 的评分数据自然可以作为样本的标签。
但对于很多应用来说,我们基本上不可能拿到它们的评分数据,更多的是点击、观看、购买这些隐性的反馈数据,所以业界更多使用 CTR 预估这类解决二分类问题的模型去解决推荐问题。
为了让我们的实践过程更接近真实的应用场景,对 MovieLens 数据集进行了进一步处理。具体来说就是,把评分大于等于 3.5 分的样本标签标识为 1,意为“喜欢”,评分小于 3.5 分的样本标签标识为 0,意为“不喜欢”。这样就可以完全把推荐问题转换为 CTR 预估问题。
四、在生成样本时避免引入“未来信息”
如果我们在 t 时刻进行模型预测,那么 t+1 时刻的信息就是未来信息。
这个问题在模型线上服务的时候是不存在的,因为未来的事情还未发生,我们不可能知道。但在离线训练的时候,我们就容易犯这样的错误。比如说,我们利用 t 时刻的样本进行训练,但是使用了全量的样本生成特征,这些特征就包含了 t+1 时刻的未来信息,这就是一个典型的引入未来信息的错误例子。
【栗子】
刚才我们说到有一个用户特征叫做用户平均评分(userAvgRating),我们通过把用户评论过的电影评分取均值得到它。假设,一个用户今年评论过三部电影,分别是 11 月 1 日评价电影 A,评分为 3 分,11 月 2 日评价电影 B,评分为 4 分,11 月 3 日评价电影 C,评分为 5 分。如果让你利用电影 B 这条评价记录生成样本,样本中 userAvgRating 这个特征的值应该取多少呢?
【错误做法】
取评价过的电影评分的均值啊,(3+4+5)/3=4 分,应该取 4 分啊。这就错了,因为在样本 B 发生的时候,样本 C 还未产生啊,它属于未来信息,不能把 C 的评分也加进去计算;而且样本 B 的评分也不应该加进去,因为 userAvgRating 指的是历史评分均值,B 的评分是我们要预估的值,也不可以加到历史评分中去。
【正确答案】
3 分,我们只能考虑电影 A 的评分。
在 Spark 中,我们应该如何处理这些跟历史行为相关的特征呢?这就需要用到 window 函数了。比如说,在生成 userAvgRating 这个特征的时候,是使用下面的代码生成的:
withColumn("userAvgRating", avg(col("rating"))
.over(Window.partitionBy("userId")
.orderBy(col("timestamp")).rowsBetween(-100, -1)))
- 1
- 2
- 3
over(Window.partitionBy("userId").orderBy(col("timestamp")))操作——即在做 rating 平均这个操作的时候,我们不要对这个 userId 下面的所有评分取平均值,而是要创建一个滑动窗口,先把这个用户下面的评分按照时间排序,再让这个滑动窗口一一滑动,滑动窗口的位置始终在当前 rating 前一个 rating 的位置。这样,我们再对滑动窗口内的分数做平均,就不会引入未来信息了。
五、把特征数据存入线上供模型服务用
把用户特征和物品特征分别存入 Redis,线上推断的时候,再把所需的用户特征和物品特征分别取出,拼接成模型所需的特征向量就可以了。FeatureEngForRecModel 中的 extractAndSaveUserFeaturesToRedis 函数给出了详细的 Redis 操作。关键步骤:
val userKey = userFeaturePrefix + sample.getAs[String]("userId")
val valueMap = mutable.Map[String, String]()
valueMap("userRatedMovie1") = sample.getAs[String]("userRatedMovie1")
valueMap("userRatedMovie2") = sample.getAs[String]("userRatedMovie2")
...
valueMap("userAvgRating") = sample.getAs[String]("userAvgRating")
valueMap("userRatingStddev") = sample.getAs[String]("userRatingStddev")
redisClient.hset(userKey, JavaConversions.mapAsJavaMap(valueMap))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
使用了 Redis 一个新的操作 hset,它的作用是把一个 Map 存入 Redis。这样做有什么好处呢?对于这里的用户特征来说,Map 中存储的就是特征的键值对,又因为这个 Map 本身是 userId 的值,所以,每个 userId 都拥有一组用户特征。这样就可以在推荐服务器内部,通过 userId 来取出所有对应的用户特征了。物品特征的储存方式是一样的。
六、作业
为了避免引入未来信息,课程讲了基于 userId 的 window 函数方法,你觉得还有哪些方法也能避免引入未来信息吗?
【答】存储特征的snapshot。
线上会组装当前访问时的历史序列及历史平均值等,可以利用flink实时落盘这些线上特征,这样线下就不用再离线生成,也就杜绝了特征穿越问题。
七、课后答疑
(1)上面图5中 只有 sparrowRecsys 模块,没有TFRecModel。项目中TFRecModel也没有小蓝框,如何设置呢
【答】File -> Project Structure -> Modules -> 左上角+号 -> Import Module -> 找到 TFRecModel -> 然后一路OK/NEXT -> 最后一步选择Python的SDK
(2)在IDEA中安装tensorflow的分享:
1.Anaconda:是一个python环境的管理软件,它一般可以采用界面或者命令行,安装按照官网文档来即可,具体解释下几个基础概念:
channels:就是获取包的来源,一般需要改为清华镜像源,那样下载速度快些
tensorflow-gpu:该包是针对有英伟达GPU的电脑的,使用需要安装NVIDIA提供的CUDA库和cuDNN神经网络加速库
2.python环境,一般使用IDEA创建py文件时,需要指定python环境,最好先使用Anaconda创建一个含有tensorflow包的环境,再创建文件时使用该环境,这样不易出问题。
(3)为什么没有tfmodel这个模块?改名TFRecModel了。
(4)如果用户上亿物品也上亿的话,存入redis会使用很大的资源。那是否是在redis只存入活跃用户的特征呢?但是如果这样解决,遇到非活跃用户是否就没有特征值了?
【答】SparrowRecsys项目确实对存储模块进行了一定程度的简化,实际应用中还是要多考虑分级存储,redis实际上当作一个缓存层来使用。
关于大量数据key value数据的存储和线上查找,可以多调研rocksdb,cassandra,dynamodb和mongodb。
(5)把评分大于等于 3.5 分的样本标签标识为 1,意为“喜欢”,评分小于 3.5 分的样本标签标识为 0,意为“不喜欢”。这样可以完全把推荐问题转换为 CTR 预估问题。请问老师,3.5分这个值是怎么来的呢?
【答】基本原则是在分析完分数的总体分布后得出的,3.5分基本是正负样本比例1:1的分界线,另外大于3.5分也符合我们直观意义上的高分,所以认为3.5分是比较合理的。
(6)spark-udf的问题,看官网上定义udf的时候要使用register,但是这里并没有使用,是sql与DataFrame的区别吗?
【答】是spark sql和直接操作dataframe的区别。直接操作dataframe不用register。
(7)如果标签或其他属性是中文内容需要进行特征处理还是直接进行word2vec?
【答】先分词再word2vec。
(8)由于用户有上亿个,在训练样本时,只是有一部分用户的usrid去进行训练,在模型上线时,不在模型训练所用的usrid里面,一般来说都有哪些处理方法呢?
【答】参考:https://zhuanlan.zhihu.com/p/351390011 。
Reference
(1)https://github.com/wzhe06/Reco-papers
(2)《深度学习推荐系统实战》,王喆
文章来源: andyguo.blog.csdn.net,作者:山顶夕景,版权归原作者所有,如需转载,请联系作者。
原文链接:andyguo.blog.csdn.net/article/details/121066130

- 点赞
- 收藏
- 关注作者
评论(0)