【王喆-推荐系统】模型篇-(task9)强化学习推荐模型DRN

学习总结
(1)深度推荐模型的前沿趋势,强化学习(Reinforcement Learning,又叫增强学习)与深度推荐模型的结合。强化学习的大体过程:通过训练一个智能体(它与环境交互,不断学习并强化自己的智力),从而指导自己的下一步行为,取得最大的预期收益。可见其优势——模型能够实时更新,用户行为快速反馈等。
(2)强化学习的落地不容易,工程量巨大(涉及到了模型训练、线上服务、数据收集、实时模型更新等几乎推荐系统的所有工程环节)。不像之前学过的深度学习模型,只要重新训练一下它,就可以改进一个模型结构。本次task学习微软的DRN模型:
- 构建了双塔模型作为深度推荐模型,得出行动得分。
- 更新方式:利用《微更新》实时学习用户的奖励反馈,更新推荐模型,再利用阶段性的《主更新》学习全量样本,更新模型。
- 微更新方法:竞争梯度下降算法(添加随机扰动;组合推荐列表;实时收集用户反馈。),它通过比较原网络和探索网络的实时效果,来更新模型的参数。而主更新会对微更新的参数进行纠偏(实践中有延迟反馈、数据噪声等问题)。
(3)DRN最大的改进就是把模型推断、模型更新、推荐系统工程整个一体化了,让整个模型学习的过程变得更高效,能根据用户的实时奖励学到新知识,做出最实时的反馈。

一、强化学习基本概念
1.1 强化学习框架的六要素
- 智能体(Agent):强化学习的主体也就是作出决定的“大脑”;
- 环境(Environment):智能体所在的环境,智能体交互的对象;
- 行动(Action):由智能体做出的行动;
- 奖励(Reward):智能体作出行动后,该行动带来的奖励;
- 状态(State):智能体自身当前所处的状态;
- 目标(Objective):指智能体希望达成的目标。
串起6要素:一个在不断变化的【环境】中的【智能体】,为了达成某个【目标】,需要不断【行动】,行动给予反馈即【奖励】,智能体对这些奖励进行学习,改变自己所处的【状态】,再进行下一步行动,即持续这个【行动-奖励-更新状态】的过程,直到达到目标。
任何一个有智力的个体,它的学习过程都遵循强化学习所描述的原理。比如说,婴儿学走路就是通过与环境交互,不断从失败中学习,来改进自己的下一步的动作才最终成功的。再比如说,在机器人领域,一个智能机器人控制机械臂来完成一个指定的任务,或者协调全身的动作来学习跑步,本质上都符合强化学习的过程。
二、强化学习推荐系统框架
强化学习推荐模型 DRN(Deep Reinforcement Learning Network,深度强化学习网络)是微软在 2018 年提出的,它被应用在了新闻推荐的场景上,下图 1 是 DRN 的框架图。同时也是一个经典的强化学习推荐系统技术框图。

(1)在新闻的推荐系统场景下,DRN 模型的第一步是初始化推荐系统,主要初始化的是推荐模型,可以利用离线训练好的模型作为初始化模型,其他的还包括我们之前讲过的特征存储、推荐服务器等等。
(2)推荐系统作为智能体会根据当前已收集的用户行为数据,也就是当前的状态,对新闻进行排序这样的行动,并在新闻网站或者 App 这些环境中推送给用户。
(3)用户收到新闻推荐列表之后,可能会产生点击或者忽略推荐结果的反馈。这些反馈都会作为正向或者负向奖励再反馈给推荐系统。
(4)推荐系统收到奖励之后,会根据它改变、更新当前的状态,并进行模型训练来更新模型。接着,就是推荐系统不断重复“排序 - 推送 - 反馈”的步骤,直到达成提高新闻的整体点击率或者用户留存等目的为止。
具体的应用场景的概念:

三、深度强化学习推荐模型 DRN
在 DRN 框架中,扮演“大脑”角色的是 Deep Q-Network (深度 Q 网络,DQN)。其中,Q 是 Quality 的简称,指通过对行动进行质量评估,得到行动的效用得分,来进行行动决策。

DQN 的网络结构如图 2 所示,它就是一个典型的双塔结构。其中,用户塔的输入特征是用户特征和场景特征,物品塔的输入向量是所有的用户、环境、用户 - 新闻交叉特征和新闻特征。
- 在强化学习的框架下,用户塔特征向量因为代表了用户当前所处的状态,所以也可被视为状态向量。
- 物品塔特征向量则代表了系统下一步要选择的新闻,这个选择新闻的过程就是智能体的“行动”,所以物品塔特征向量也被称为行动向量。
- 双塔模型通过对状态向量和行动向量分别进行 MLP 处理,再用互操作层生成了最终的行动质量得分 Q(s,a),智能体正是通过这一得分的高低,来选择到底做出哪些行动,也就是推荐哪些新闻给用户的。
四、DRN 的学习过程
正是因为可以在线更新,才使得强化学习模型相比其他“静态”深度学习模型有了更多实时性上的优势。
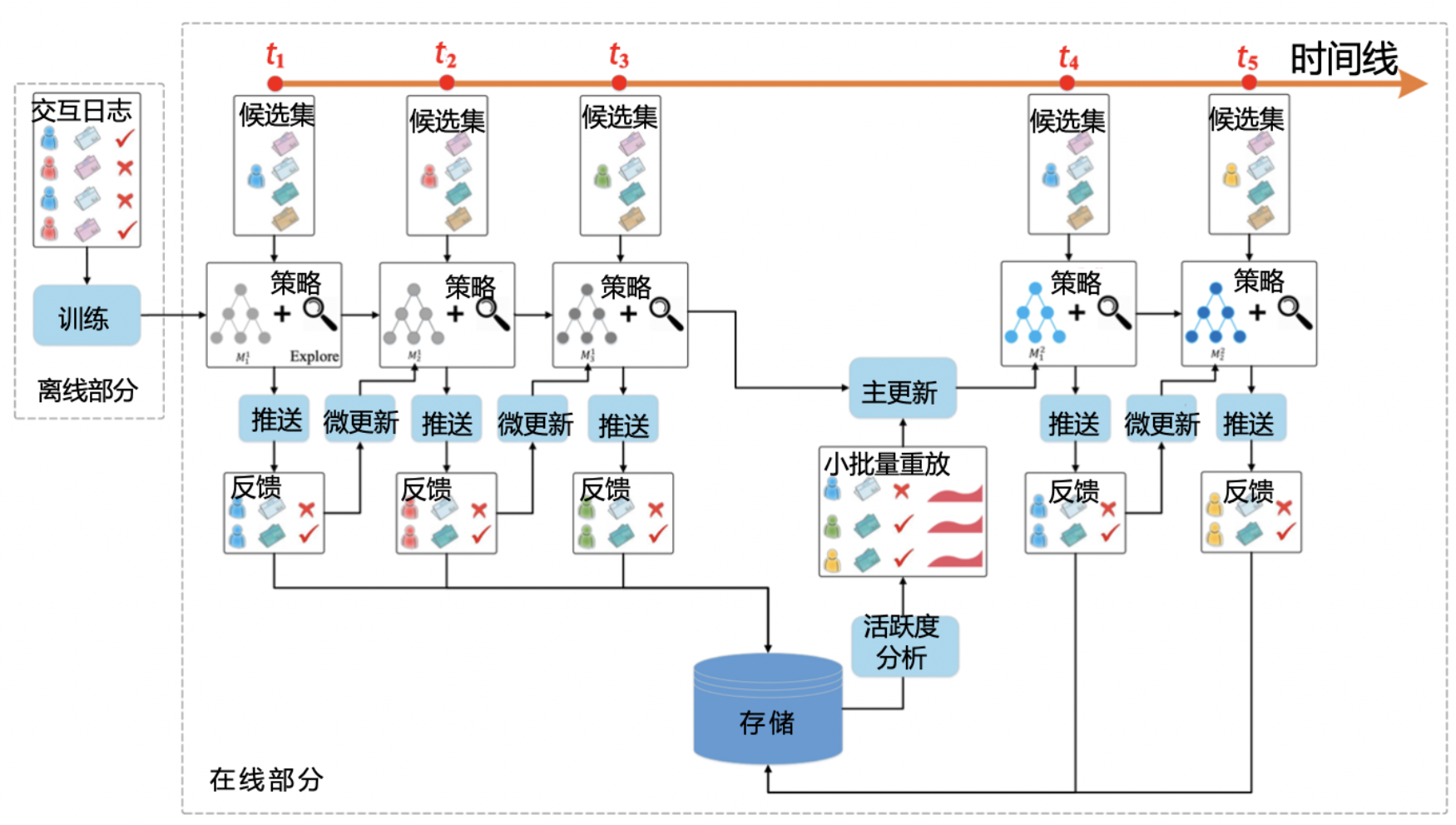
4.1 离线部分
DRN 根据历史数据训练好 DQN 模型,作为智能体的初始化模型。
4.2 在线部分
在线部分根据模型更新的间隔分成 n 个时间段,这里以 t1 到 t5 时间段为例。
(1)首先在 t1 到 t2 阶段,DRN 利用初始化模型进行一段时间的推送服务,积累反馈数据。(2)接着是在 t2 时间点,DRN 利用 t1 到 t2 阶段积累的用户点击数据,进行模型微更新(Minor update)。
(3)t2、t3 时间点提到的模型微更新操作,用到 DRN 使用的一种新的在线训练方法,Dueling Bandit Gradient Descent algorithm(竞争梯度下降算法)。
(4)最后在 t4 时间点,DRN 利用 t1 到 t4 阶段的用户点击数据及用户活跃度数据,进行模型的主更新(Major update)——可以理解为利用历史数据的重新训练,用训练好的模型来替代现有模型。时间线不断延长,我们就不断重复 t1 到 t4 这 3 个阶段的操作。
五、DRN 的在线学习方法:竞争梯度下降算法
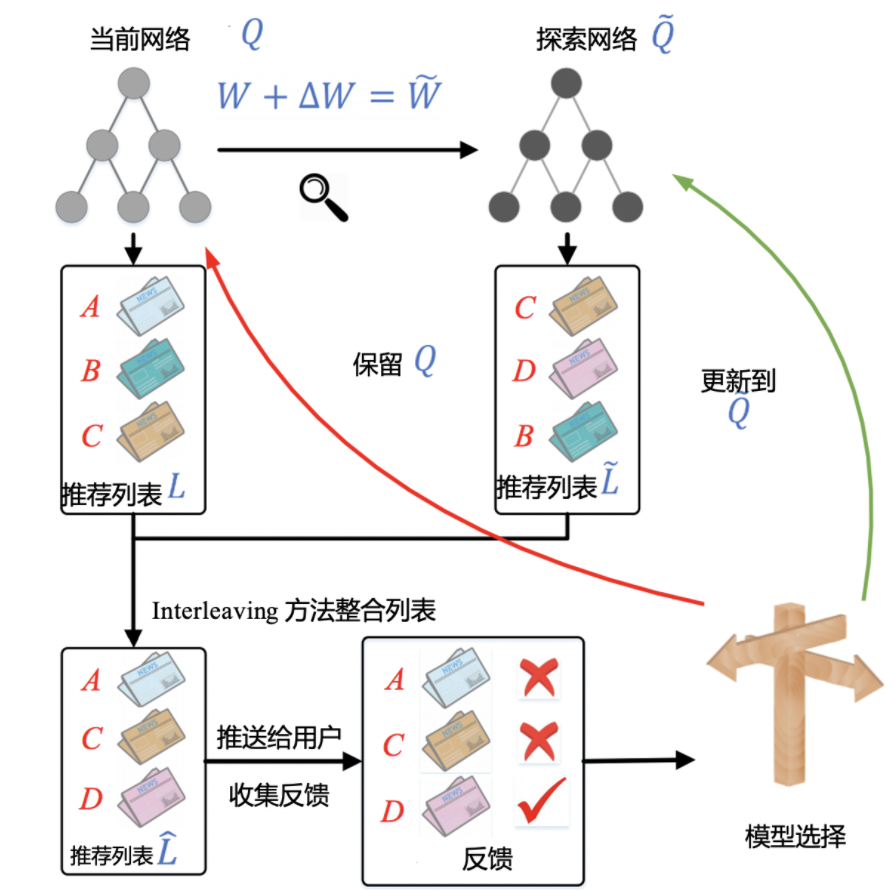
5.1 添加随机扰动
第一步,对于已经训练好的当前网络 Q,对其模型参数 W 添加一个较小的随机扰动(具体公式如下),得到一个新的模型参数,这里称对应的网络为探索网络 Q~。
在这一步中,由当前网络 Q 生成探索网络 ,产生随机扰动的公式 1 如下: Δ W = α ⋅ r a n d ( − 1 , 1 ) ⋅ W ΔW=α⋅rand(−1,1)⋅W ΔW=α⋅rand(−1,1)⋅W其中,α 是一个探索因子,决定探索力度的大小。rand(-1,1) 产生的是一个[-1,1]之间的随机数。
5.2 组合推荐列表
第二步,对于当前网络 Q 和探索网络 Q~,分别生成推荐列表 L 和 L~,再将两个推荐列表用间隔穿插(Interleaving)的方式融合,组合成一个推荐列表后推送给用户。
5.3 实时收集用户反馈
最后一步是实时收集用户反馈。如果探索网络 Q~生成内容的效果好于当前网络 Q,我们就用探索网络代替当前网络,进入下一轮迭代。反之,我们就保留当前网络。
5.4 总结
DRN 的在线学习过程利用了“探索”的思想,其调整模型的粒度可以精细到每次获得反馈之后,这一点很像随机梯度下降的思路:虽然一次样本的结果可能产生随机扰动,但只要总的下降趋势是正确的,我们就能够通过海量的尝试最终达到最优点。
DRN 正是通过这种方式,让模型时刻与最“新鲜”的数据保持同步,实时地把最新的奖励信息融合进模型中。模型的每次“探索”和更新也就是我们之前提到的模型“微更新”。
在这个过程中,需要一个架构师一样的角色来通盘协调,就成为了整个落地过程的关键点。有一个环节出错,比如说模型在做完实时训练后,模型参数更新得不及时,那整个强化学习的流程就被打乱了,整体的效果就会受到影响。
六、作业
(1)DRN 的微更新用到了竞争梯度下降算法,这个算法有没有弊端?你还知道哪些可以进行模型增量更新或者实时更新的方法吗?
【答】算法相比于随机梯度下降算法的弊端是:每个参数的更新方向是随机的,而不是像随机下降算法一样,是沿着梯度更新的。随机更新可能导致的结果就是:
1.收敛是缓慢的。2.很难收敛到全局最优值。
DRN的微更新,弊端是随机更新收敛太慢,没有方向性。可以参考double DQN,用target net和action net结果之间的差值作为loss,然后隔一段时间将action net 赋值给target net,直至两者完全一致,收敛。而action net的更新采用了experience replay的技术,随机选取历史数据再训练,同时有小概率采用随机方向的探索,也许这样比DBGD更有方向性。
DRN 的微更新用到了竞争梯度下降算法,理解上可以近似我们的遗传算法/进化算法。
小的扰动可以理解为“网络offspring的变异”,然后根据反馈选择优秀的“子代”模型替代“上一代模型”。
另外一个思路就是,可以考虑集成学习的策略(Ensemble Learning)。建立合适的模型群,设计增加或者减少模型的策略,例如基于contribution scores 或者添加基于时间的权重等。
因为线上推荐系统的数据流是变化的,所以不存在一个“当前vs所有”或者历史意义上的最优模型, 只要用户对推荐效果的反馈不发生大幅度变差,就可以算是成功了。
七、课后答疑
(1)竞争梯度下降算法需要比较探索网络和当前网络的推荐效果,但是在模型结构图中,微更新的参考只有上阶段的推荐反馈,这里的推荐反馈只有一个,那么如何去更新竞争梯度下降算法呢?探索网络和当前网络的推荐效果是在图示的哪个阶段进行实现的呢?
【答】在实际实现中肯定不是只用一个效果就更新网络,而是做一小段实践的数据收集,再根据这个batch的效果进行探索网络和当前网络的选择。这部分在实际的工程中一般是在flink等流计算平台上实现的。
(2)主更新的训练策略使用的也是竞争梯度下降算法吗?使用历史数据重新训练,这里指的是从零训练,还是说从离线阶段输出的模型进行fine-tune呢?
【答】主更新不使用梯度下降算法。实际工程中可视为一次正常的模型更新,使用的是全量历史样本,当然这其中包括了最近收集到的样本。
(3)按照论文,首先对原网络进行随机扰动,那么需要保存随机扰动之后的模型W’,然后用W和W’产生的结果进行交织,根据结果选取好的保留。因为这里最后推荐是一个列表。要评估整个列表的推荐结果,至少需要等到用户手动刷新推荐或者离开推荐页。这个过程,按照我的现有知识,整个过程从生成推荐列表到获取列表反馈,完成下来可能需要几分钟。请问一次更新真的一般都是这么长时间吗?是否业界有其他办法?
如果真的像我所想,那么DBGD的弊端就是在这几分钟内网络权重只能迭代一次,而且探索方向只有一个。
如果增加要增加网络更新频率,可以用反向传播计算梯度,在线更新模型,这就和一般的神经训练一样,只是根据实时样本流训练。
增加探索方向可以使用Evolution Strategy。从当前网络权重为中心按照高斯分布采样,根据每个子网络的用户反馈计算梯度,用梯度上升更新网络。
【答】不可能完成秒级别的更新,应该是以分钟为级别,而且应该是收集少量的mini batch数据之后进行一次梯度更新。
因为像你说的,列表展示、用户反应和交互最好需要几十秒到几分钟的时间,更别提整个数据流的延迟了。这篇论文其实已经做了大量的工程妥协,我们也主要理解思路即可,不用太多纠结于具体的思路。
(4)微更新部分主要是学习用户的实时反馈,直接使用梯度下降也可以学习到,为什么要采用竞争梯度下降呢?
【答】基于SGD的online learning确实可以做实时学习。但它的整个工程难度比竞争梯度下降难非常多,可以从整个框架的角度去思考这个问题,为什么落地难度大非常多。
(5)增加实时性上采用FTRL进行在线学习和强化学习在最终结果上有什么区别,如何判断选择?
【答】online learning其实可以看作强化学习的一个子集,或者说是子类。所以FTRL做在线学习本质上就是强化学习的一种。
(6)在线更新应该不是区别强化学习DRN的核心。DRN 的核心在于 DQN 把 状态 和 行动建立起评分联系。Q是Q learning 的意思,即 在这个状态下 可能的行动的评分预计。这个DQN的学习 才应该是核心,是区别传统的监督学习 输入输出pair 的关键。毕竟评分标准 不是直接的label.
【答】其实理论上DQN也没有非常大的创新,因为所谓的状态就是用户所处的当前特征集合,所谓行动就是物品的特征。需要建立强化学习中状态的和行动的概念和思想,看看能否应用到推荐系统之中。
其实宽泛的意义上,mutli-bandit,online learning都属于强化学习的范畴。
典型的强化学习的最大功夫就在于如何进行这里的微调,一般来说mutli-bandit中的exploration策略会粗放一些,偏global的调整,但RL一般会通过进行新样本的学习,调整智能体也就是这里的模型来实现不断的学习。
Reference
(1)https://github.com/wzhe06/Reco-papers
(2)《深度学习推荐系统实战》,王喆
(3)美团技术团队:强化学习在美团“猜你喜欢”的实践
(4)spinningup中文文档:https://spinningup.qiwihui.com/zh_CN/latest/
文章来源: andyguo.blog.csdn.net,作者:山顶夕景,版权归原作者所有,如需转载,请联系作者。
原文链接:andyguo.blog.csdn.net/article/details/121201008

- 点赞
- 收藏
- 关注作者
评论(0)