【王喆-推荐系统】模型篇-(task7)DeepFM处理交叉特征

学习总结
(1)DeepFM 模型在解决特征交叉问题上非常有优势,它会使用一个独特的 FM 层来专门处理特征之间的交叉问题。具体来说,就是使用点积、元素积等操作让不同特征之间进行两两组合,再把组合后的结果输入的输出神经元中,这会大大加强模型特征组合的能力。
(2)DeepFM的三个重点:
它是由 FM 和 Deep 两部分组成的;
在实现 FM 部分特征交叉层的时候,我们使用了多个 Dot Product 操作单元完成不同特征的两两交叉;
Deep 部分则与 Wide&Deep 模型一样,负责所有输入特征的深度拟合,提高模型整体的表达能力
(3)召回之后的“候选集”一个list,或者是很多item的集合,这个list的排序也可以使用本次学到的DeepFM。
(4)回顾矩阵相关的算法:结构上来说,因子分解机会引入除了user id和item id的其他特征,而且FM是有一阶部分的,不只是做特征交叉。
- 因子分解机模型(Factorization Machine)的FM层通过内积交叉特征;
- 奇异值分解(singular value decomposition)
- 非负矩阵分解NMF(Non-Negative Matrix Factorization)的基本思想:给定一个非负矩阵V,NMF能够找到一个非负矩阵W和一个非负矩阵H,使得矩阵W和H的乘积近似等于矩阵V中的值。
- 经典推荐算法协同过滤的深度学习进化版本 NerualCF。NeuralCF 用一个多层的神经网络,替代了矩阵分解算法中简单的点积操作,让用户和物品隐向量之间进行充分的交叉。通过改进物品隐向量和用户隐向量互操作层的方法,增强模型的拟合能力。

零、回顾上节
【栗子】
现在模型的输入有性别、年龄、电影风格这几个特征,在训练样本中我们发现有 25 岁男生喜欢科幻电影的样本,有 35 岁女生喜欢看恐怖电影的样本,那你觉得模型应该怎么推测“25 岁”的女生喜欢看的电影风格呢?
这其实是特征交叉和特征组合的问题,而这也决定了模型对未知特征组合样本的预测能力(推荐系统效果的关键)。
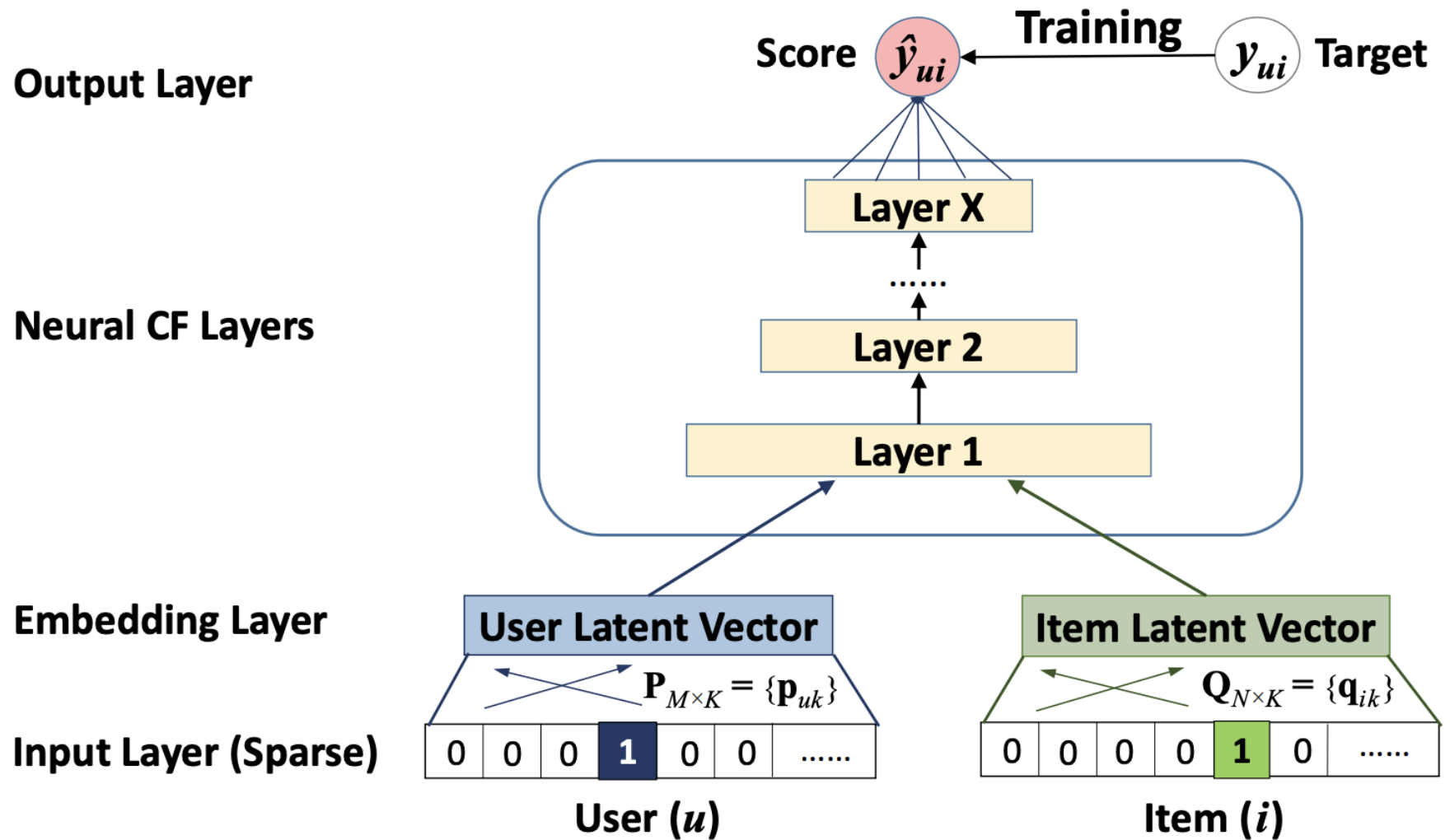
【NeuralCF模型】
NeuralCF模型只在最后才把物品侧和用户侧的特征交叉起来(如下);之前提到的MLP+embedding或者wide&deep算法也没有对特征交叉做特别的处理。
一、加强处理特征交叉的能力
之前一直说 MLP 有拟合任意函数的能力,但这是建立在 MLP 有任意多层网络,以及任意多个神经元的前提下的。
在训练资源有限,调参时间有限的现实情况下,MLP 对于特征交叉的处理其实还比较低效。因为 MLP 是通过 concatenate 层把所有特征连接在一起成为一个特征向量的,这里面没有特征交叉,两两特征之间没有发生任何关系。
【改进】
我们可以通过先验知识,人为地进行交叉特征,举栗子:在sparrow项目中有2个特征:用户喜欢的电影特征和电影本身的风格,这两个特征有很明显的强相关性,可以利用这种相关性进行特征交叉组合。
二、机器学习模型FM如何处理特征交叉
机器学习模型因子分解机模型(Factorization Machine)即FM的结构如下图:
(1)类别型特征转为one-hot向量
(2)将one-hot向量通过embedding层转为稠密的embedding层
(3)独特的是这里,使用一个单独的FM层处理特征之间的交叉问题:这里是多个内积操作单元对不同特征向量两两组合
(4)将(3)的内积操作结果输入到输出神经元,完成预测

这样回到刚才的栗子,用户喜欢的电影风格和电影本身的风格,通过FM层的两两特征的内积操作,使得特征进行充分的组合,不至于像embedding + MLP一样的MLP内部像黑盒子一样低效地交叉。
三、DeepFM模型
哈工大和华为一起提出DeepFM就是基于wide&deep组合模型的思想,我们可以将以往的FM和其他深度学习模型结合,成为一个全新的强特征组合能力的模型,并且也具有强拟合能力。
注意下图的FM层有个加操作:加操作是不进行特征交叉,直接把原先的特征接入输出层,相当于wide&deep模型中的wide层。

由上图的DeepFM架构图看出:
(1)用FM层替换了wide&deep左边你的wide部分;
——加强浅层网络的特征组合能力。
(2)右边保持和wide&deep一毛一样,利用多层神经元(如MLP)进行所有特征的深层处理
(3)最后输出层将FM的output和deep的output组合起来,产生预估结果
一般来说物品侧和用户侧的特征交叉的作用更大,在实际应用中,还是最好有一些手动调参,和先验知识会更好一些。
四、特征交叉新方法:元素积操作
特征交叉不止有点积操作。比如可以使用模型 NFM(Neural Factorization Machines,神经网络因子分解机)。
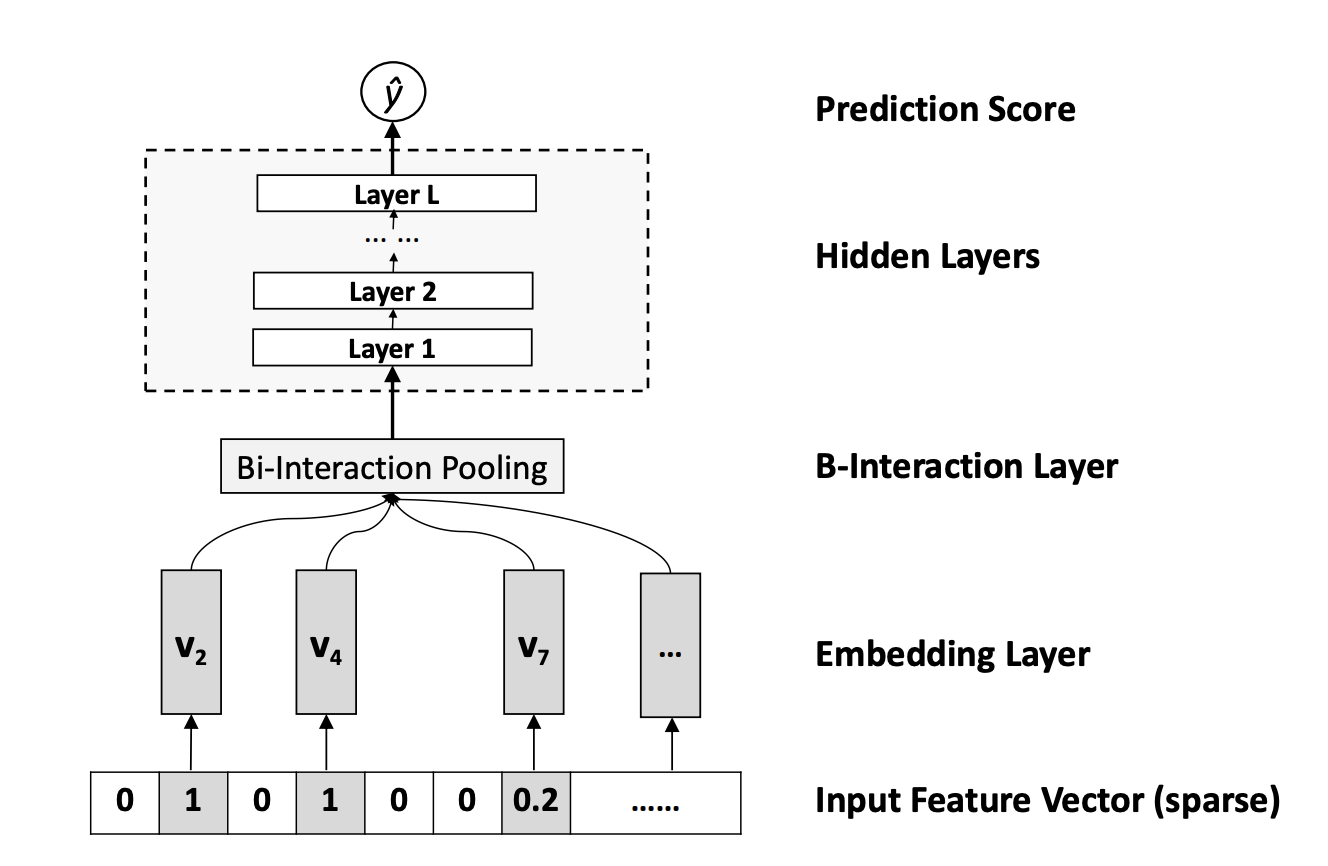
Bi-Interaction Pooling 层(中文:两两特征交叉池化层)。
4.1 元素积操作
假设 Vx 是所有特征域的 Embedding 集合,那么特征交叉池化层的具体操作如下所示。 f P I ( V x ) = ∑ i = 1 n ∑ j = i + 1 n x i v i ⊙ x j v j f_{\mathrm{PI}}\left(V_{x}\right)=\sum_{i=1}^{n} \sum_{j=i+1}^{n} x_{i} \boldsymbol{v}_{i} \odot \boldsymbol{x}_{j} \boldsymbol{v}_{j} fPI(Vx)=i=1∑nj=i+1∑nxivi⊙xjvj
⊙ \odot ⊙运算指两个向量的元素积(Element-wise Product),即两个长度相同的向量对应维相乘得到元素积向量。其中,第 k 维的操作: ( V i ⊙ V j ) K = v i k v j k \left(V_{i} \odot V_{j}\right)_{K}=v_{i k} v_{j k} (Vi⊙Vj)K=vikvjk
4.2 求所有交叉特征向量之和
并非像之前对向量做concatenate操作,而是如题操作(求和的池化层操作),就得到池化层的output,最后将该output输入到多层全连接神经网络,得到最终的预测得分。
王喆大佬:元素积操作和点积操作到底哪个更好呢?尽量多地储备深度学习模型的相关知识,先不去关注哪个方法的效果会更好,至于真实的效果怎么样,交给你去在具体的业务场景的实践中验证。
五、DeepFM 的 TensorFlow 实战
(1)deep的代码和embedding+MLP左边的MLP一样;
(2)FM则是首先选择了 4 个用于交叉的类别型特征,分别是用户 ID、电影 ID、用户喜欢的风格和电影自己的风格,然后对物品层和用户层的embedding进行来两两交叉特征,具体即元素积操作(取代向量的点积操作)。
(3)最后使用 concatenate 层,去把 FM 部分的输出和 Deep 部分的输出连接起来,输入到输出层的 sigmoid 神经元,从而产生最终的预估分数。
item_emb_layer = tf.keras.layers.DenseFeatures([movie_emb_col])(inputs)
user_emb_layer = tf.keras.layers.DenseFeatures([user_emb_col])(inputs)
item_genre_emb_layer = tf.keras.layers.DenseFeatures([item_genre_emb_col])(inputs)
user_genre_emb_layer = tf.keras.layers.DenseFeatures([user_genre_emb_col])(inputs)
# FM part, cross different categorical feature embeddings
product_layer_item_user = tf.keras.layers.Dot(axes=1)([item_emb_layer, user_emb_layer])
product_layer_item_genre_user_genre = tf.keras.layers.Dot(axes=1)([item_genre_emb_layer, user_genre_emb_layer])
product_layer_item_genre_user = tf.keras.layers.Dot(axes=1)([item_genre_emb_layer, user_emb_layer])
product_layer_user_genre_item = tf.keras.layers.Dot(axes=1)([item_emb_layer, user_genre_emb_layer])
# deep part, MLP to generalize all input features
deep = tf.keras.layers.DenseFeatures(deep_feature_columns)(inputs)
deep = tf.keras.layers.Dense(64, activation='relu')(deep)
deep = tf.keras.layers.Dense(64, activation='relu')(deep)
# concatenate fm part and deep part
concat_layer = tf.keras.layers.concatenate([product_layer_item_user, product_layer_item_genre_user_genre,
product_layer_item_genre_user, product_layer_user_genre_item, deep], axis=1)
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(concat_layer)
model = tf.keras.Model(inputs, output_lay)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
PS:上面只是示例代码,FM部分只用到了四个特征,并不是原型FM的全部交叉,而且也没有一阶非交叉的特征,这应该只算是deep网络和手工交叉的组合,严格意义不能算是deepfm的实现(后面会出pytorch版本的DeepFM)。
三、作业
(1)除了点积和元素积这两个操作外,还有没有其他的方法能处理两个 Embedding 向量间的特征交叉?
1.是否可以把这两个embedding向量组合之后再做一次embedding。
2.对于两个Embedding向量做一次pooling层,采用average/max pooling。
3.除此之外,还有元素减,外积等交叉操作,除此之外还有一些自定义的复杂交叉操作,比如google cross&deep模型中自定义的一些cross操作。对
4.特征embedding做concat、average pooling、sum pooling 确实都可以,但针对性不强,还是一些专门针对两个embedding特征交叉设计的操作效果好一些。比如我们提到的dot product, element-wise product 和element-wise minus. outer product等等。
王喆大佬:其实深度学习中没有什么不可以的,有的只是提出思路,改进模型,和验证效果。把点积和元素积在一起使用,交给模型自动学习权重当然也是可行的。
(2)多去尝试不同的特征输入,不同的模型结构,甚至可以按照自己的理解和思考去改进这些模型。
因为深度学习模型结构没有标准答案,我们只有清楚不同模型之间的优缺点,重点汲取它们的设计思想,才能在实际的工作中结合自己遇到的问题,来优化和改造已有的模型。
四、课后答疑
(1)DeepFM的图示中,输入均是类别型特征的one-hot或embedding,请问是因为特征交叉仅适用于类别型特征的交叉吗?数值型特征之间,数值型与类别型特征之间能否进行交叉呢?另外,在DeepFM的wide部分中一阶交叉项是否可以包含未参与特征交叉的数值型特征呢?
【答】按照DeepFM原论文,数值型特征是不参与特征交叉的,因为特征交叉的操作是在两个embedding向量间进行的。
但是如果可以把通过分桶操作把连续型特征处理成离散型特征,然后再加Embedding层,就可以让数值型特征也参与特征交叉。这是一个可行的方案。
(2)原FM中二阶交叉项中隐向量的内积仅作为权重,但从这篇课程的图示和代码来看,他们的内积直接作为了交叉项的结果,而没有了初始特征的交叉。
这样做是因为教程里所选的特征是one-hot格式,所以维度可能不一致,从而无法进行初始特征的交叉吗?
那对于数值型的特征,他们的初始特征交叉是否应该和隐向量内积相乘再作为二阶交叉项的输出呢?
【答】原FM中内积作为权重,然后还要乘以特征本身的值。
但在DeepFM中,所有的参与交叉的特征都先转换成了embedding,而且由于是one-hot,所以特征的值就是1,参不参与交叉都无所谓。所以直接使用embedding的内积作为交叉后的值就可以了。
至于数值型特征的问题在于,如何把他们转换成embedding向量,我觉得分桶后加embedding层是一个方法,但其实分桶后加embedding层也是不用加原特征值的,因为分桶后的结果还是一个one-hot向量。
因为要变成同一维度才能做内积,categorical feature embedding 到 embedding_dim 维, 需要数值型也映射到embedding_dim 维。数值型映射的方式可以是分箱也可以是乘以一个 embedding_dim 的向量。
(3)按FM的交叉方式,不同特征的embedding 向量维度要相同,但实际不同离散特征的维度可能相差很大,如果想用不同的embedding 维度,那应该怎样做交叉,业界有没有这样的处理方式?
【答】几乎不可以。如果一定要做的话,也要在不同embedding层上再加上一层fc layer或者embedding layer,把他们变成一致的,然后交叉。
Reference
(1)https://github.com/wzhe06/Reco-papers
(2)《深度学习推荐系统实战》,王喆
文章来源: andyguo.blog.csdn.net,作者:山顶夕景,版权归原作者所有,如需转载,请联系作者。
原文链接:andyguo.blog.csdn.net/article/details/121157134

- 点赞
- 收藏
- 关注作者
评论(0)