【MySQL实战45讲基础篇】(task1)基础架构:SQL查询语句如何执行

学习总结
(1)以一条查询语句为栗子过一遍执行流程,初步学习MySQL的逻辑架构。
(2)可以从一个有趣的栗子入手:
1)连接器:门卫,想进请出示准入凭证(工牌、邀请证明一类)。“你好,你是普通员工,只能进入办公大厅,不能到高管区域”此为权限查询。
2)分析器:“您需要在公司里面找一张头发是黑色的桌子?桌子没有头发啊!臣妾做不到”。
3)优化器:“要我在A B两个办公室找张三和李四啊?那我应该先去B办公室找李四,然后请李四帮我去A办公室找张三,因为B办公室比较近且李四知道张三具体工位在哪”。
4)执行器:“好了,找人的计划方案定了,开始行动吧,走你!糟糕,刚门卫大哥说了,我没有权限进B办公室”。
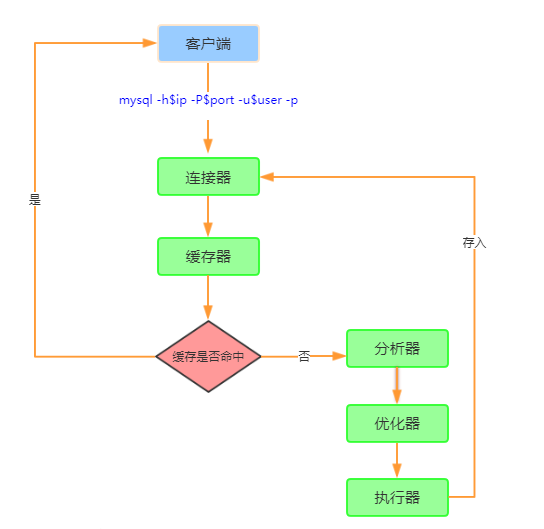
一、MySQL逻辑架构图
现在有一个只有一个ID字段的表,当执行查询语句
mysql> select * from T where ID=10;
- 1
其中的执行过程是本task要学的。
MySQL 可以分为 Server 层和存储引擎层两部分。
1.1 Server 层
Server 层包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
1.2 存储引擎层
而存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
也就是说,你执行 create table 建表的时候,如果不指定引擎类型,默认使用的就是 InnoDB。不过,你也可以通过指定存储引擎的类型来选择别的引擎,比如在 create table 语句中使用 engine=memory, 来指定使用内存引擎创建表。不同存储引擎的表数据存取方式不同,支持的功能也不同。

从上图中看出,不同的存储引擎共用一个 Server 层,也就是从连接器到执行器的部分。
二、Server层五大部分
2.1 连接器

(1)连接命令
首先要连接数据库,所以连接器的作用:和客户端建立连接、获取权限、维持和管理连接。
连接命令的一般写法如下。然后就是输入密码,密码也可以直接跟在-p后面(即写在命令行里),如果是生产服务器就别这么做(不安全)。
mysql -h$ip -P$port -u$user -p
- 1
账号密码正确后,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限(就是说即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置)。
(2)连接后
连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,show processlist 命令可以看到该连接(如下图),第一行的Command处是Sleep就是代表现在系统有一个空闲连接。

客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时,超过8h再次发起请求则会报错Lost connection to MySQL server during query,只能重连咯。
TIPS:
(1)最好用长连接
数据库里面,长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。短连接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。
(2)如果长连接累积下来,可能导致内存占用太大,被系统强行杀掉(OOM),从现象看就是 MySQL 异常重启了。
(3)长连接过多导致内存爆炸
如果全部使用长连接后,你可能会发现,有些时候 MySQL 占用内存涨得特别快,这是因为 MySQL 在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放。解决方案有:
- 定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
- 如果用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行
mysql_reset_connection来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
2.2 查询缓存
如果查询命中缓存MySQL不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高,但是大多数情况下不建议使用查询缓存,因为:
1、查询缓存的失效非常频繁,只要有一个表更新,这个表上所有的查询缓存都被清空
2、对于更新压力大的数据库来说,查询缓存的命中率会非常低,
3、除非你的业务就是有一张静态表,很长时间才会更新一次(比如一个系统配置表)
(1)默认语句使用查询缓存
query_cache_type 设置成 DEMAND
(2)确定需要查询缓存的语句
用SQL_CACHE 显式指定。
mysql> select SQL_CACHE * from T where ID=10;
- 1
注意:MySQL 8.0 版本直接将查询缓存的整块功能删掉了,8.0 开始彻底没有这个功能了。
2.3 分析器
如果没有命中缓存,则要正真开始执行语句,分析器对SQL语句做解析。首先是《词法分析》,即识别里面的字符串分别是啥,并且代表啥。然后是《语法分析》判断该SQL语句是否合法。如果语句不对则会如下报错(下面SQL语句是select少了开头的s字母)。
mysql> elect * from t where ID=1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'elect * from t where ID=1' at line 1
- 1
- 2
- 3
注意:一般语法错误会提示第一个出现错误的位置,所以你要关注的是紧接"use naar"的内容。
2.4 优化器
作用:
1、在表里面有多个索引的时候,决定使用哪个索引
2、多表关联(join)的时候,决定各个表的链接顺序
mysql> select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;
- 1
- 既可以先从表 t1 里面取出 c=10 的记录的 ID 值,再根据 ID 值关联到表 t2,再判断 t2 里面 d 的值是否等于20
- 也可以先从表 t2 里面取出 d=20 的记录的 ID 值,再根据 ID 值关联到 t1,再判断 t1 里面 c 的值是否等于10
这两种执行方法的逻辑结果时一样的,但是执行的效率会有不同,而优化器的作用就是决定选择哪一个方案
2.5 执行器
开始执行时会判断用户是否对该表T有执行查询的权限(如果没有权限就返回如下error;在工程实现上,如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证。查询也会在优化器之前调用precheck验证权限)。
如果有权限,就打开表继续执行;
打开表时,执行器会根据表的引擎定义,使用该引擎提供的接口。
mysql> select * from T where ID=10;
ERROR 1142 (42000): SELECT command denied to user 'b'@'localhost' for table 'T'
- 1
- 2
- 3
(1)没有索引的执行流程
1、调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是1,如果不是则跳过,如果是则将这行存在结果集中
2、调用引擎接口取"下一行",重复相同的判断逻辑,直到取到这个表的最后一行
3、执行器将上述遍布过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
(2)有索引的执行流程
第一调用的是"取满足条件的第一行"这个接口,
之后循环取"满足条件的下一行"这个引擎中的接口。
PS:引擎扫描行数跟rows_examined并不是完全相同的。
三、作业
如果表 T 中没有字段 k,而你执行了这个语句 select * from T where k=1, 那肯定是会报“不存在这个列”的错误: “Unknown column ‘k’ in ‘where clause’”。你觉得这个错误是在我们上面提到的哪个阶段报出来的呢?
【答】分析器。
《高性能mysql》里提到解析器和预处理器。
解析器处理语法和解析查询, 生成一课对应的解析树。
预处理器进一步检查解析树的合法。比如: 数据表和数据列是否存在, 别名是否有歧义等。如果通过则生成新的解析树,再提交给优化器。
四、课后答疑
(1)为什么对权限的检查不在优化器之前做?
【答】有些时候,SQL语句要操作的表不只是SQL字面上那些。比如如果有个触发器,得在执行器阶段(过程中)才能确定。优化器阶段前是无能为力的。
(2)我创建了一个没有select权限的用户,执行select * from T where k=1,报错“select command denied”,并没有报错“unknown column”,是不是可以说明是在打开表之后才判断读取的列不存在?
【答】这个是一个安全方面的考虑。你想想一个用户如果没有查看这个表的权限,你是会告诉他字段不对还是没权限?如果告诉他字段不对,其实给的信息太多了,因为没权限的意思还包含了:没权限知道字段是否存在。
(3)Trace 日志是个好东西:
源码安装完MySQL之后,使用Debug模式启动
mysqld --debug --console &后,
mysql> create database wxb;
Query OK, 1 row affected (0.01 sec)
mysql> use wxb;
Database changed
mysql> create table t(a int);
Query OK, 0 rows affected (0.01 sec)
mysql> select * from t where k=1;
ERROR 1054 (42S22): Unknown column ‘k’ in ‘where clause’
T@4: | | | | | | | | | error: error: 1054 message: ‘Unknown column ‘k’ in ‘where clause’’
Complete optimizer trace:
答案就很清楚了。
附基础篇的大纲

Reference
(1)《MySQL实战45讲》
(2)https://www.cnblogs.com/luoahong/p/10383486.html
附:MySQL的语句执行顺序
PS:这部分转自java知路公众号。
今天遇到一个问题就是mysql中insert into 和update以及delete语句中能使用as别名吗?目前还在查看,但是在查阅资料时发现了一些有益的知识,给大家分享一下,就是关于sql以及MySQL语句执行顺序:
sql和mysql执行顺序,发现内部机制是一样的。最大区别是在别名的引用上。
一、sql执行顺序
from
join
on
where
group by(开始使用select中的别名,后面的语句中都可以使用)
avg,sum....
having
select
distinct
order by
limit
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
从这个顺序中我们不难发现,所有的 查询语句都是从from开始执行的,在执行过程中,每个步骤都会为下一个步骤生成一个虚拟表,这个虚拟表将作为下一个执行步骤的输入。
第一步:首先对from子句中的前两个表执行一个笛卡尔乘积,此时生成虚拟表 vt1(选择相对小的表做基础表)。
第二步:接下来便是应用on筛选器,on 中的逻辑表达式将应用到 vt1 中的各个行,筛选出满足on逻辑表达式的行,生成虚拟表 vt2 。
第三步:如果是outer join 那么这一步就将添加外部行,left outer jion 就把左表在第二步中过滤的添加进来,如果是right outer join 那么就将右表在第二步中过滤掉的行添加进来,这样生成虚拟表 vt3 。
第四步:如果 from 子句中的表数目多余两个表,那么就将vt3和第三个表连接从而计算笛卡尔乘积,生成虚拟表,该过程就是一个重复1-3的步骤,最终得到一个新的虚拟表 vt3。
第五步:应用where筛选器,对上一步生产的虚拟表引用where筛选器,生成虚拟表vt4,在这有个比较重要的细节不得不说一下,对于包含outer join子句的查询,就有一个让人感到困惑的问题,到底在on筛选器还是用where筛选器指定逻辑表达式呢?on和where的最大区别在于,如果在on应用逻辑表达式那么在第三步outer join中还可以把移除的行再次添加回来,而where的移除的最终的。举个简单的例子,有一个学生表(班级,姓名)和一个成绩表(姓名,成绩),我现在需要返回一个x班级的全体同学的成绩,但是这个班级有几个学生缺考,也就是说在成绩表中没有记录。为了得到我们预期的结果我们就需要在on子句指定学生和成绩表的关系(学生.姓名=成绩.姓名)那么我们是否发现在执行第二步的时候,对于没有参加考试的学生记录就不会出现在vt2中,因为他们被on的逻辑表达式过滤掉了,但是我们用left outer join就可以把左表(学生)中没有参加考试的学生找回来,因为我们想返回的是x班级的所有学生,如果在on中应用学生.班级='x’的话,left outer join会把x班级的所有学生记录找回(感谢网友康钦谋__康钦苗的指正),所以只能在where筛选器中应用学生.班级=‘x’ 因为它的过滤是最终的。
第六步:group by 子句将中的唯一的值组合成为一组,得到虚拟表vt5。如果应用了group by,那么后面的所有步骤都只能得到的vt5的列或者是聚合函数(count、sum、avg等)。原因在于最终的结果集中只为每个组包含一行。这一点请牢记。
第七步:应用cube或者rollup选项,为vt5生成超组,生成vt6.
第八步:应用having筛选器,生成vt7。having筛选器是第一个也是为唯一一个应用到已分组数据的筛选器。
第九步:处理select子句。将vt7中的在select中出现的列筛选出来。生成vt8.
第十步:应用distinct子句,vt8中移除相同的行,生成vt9。事实上如果应用了group by子句那么distinct是多余的,原因同样在于,分组的时候是将列中唯一的值分成一组,同时只为每一组返回一行记录,那么所以的记录都将是不相同的。
第十一步:应用order by子句。按照order_by_condition排序vt9,此时返回的一个游标,而不是虚拟表。sql是基于集合的理论的,集合不会预先对他的行排序,它只是成员的逻辑集合,成员的顺序是无关紧要的。对表进行排序的查询可以返回一个对象,这个对象包含特定的物理顺序的逻辑组织。这个对象就叫游标。正因为返回值是游标,那么使用order by 子句查询不能应用于表表达式。排序是很需要成本的,除非你必须要排序,否则最好不要指定order by,最后,在这一步中是第一个也是唯一一个可以使用select列表中别名的步骤。
第十二步:应用top选项。此时才返回结果给请求者即用户。
二、mysql的执行顺序
1、SELECT语句定义
一个完成的SELECT语句包含可选的几个子句。SELECT语句的定义如下:
SQL代码
<SELECT clause> [<FROM clause>] [<WHERE clause>]
[<GROUP BY clause>] [<HAVING clause>]
[<ORDER BY clause>] [<LIMIT clause>]
- 1
- 2
- 3
SELECT子句是必选的,其它子句如WHERE子句、GROUP BY子句等是可选的。
一个SELECT语句中,子句的顺序是固定的。例如GROUP BY子句不会位于WHERE子句的前面。
2、SELECT语句执行顺序
SELECT语句中子句的执行顺序与SELECT语句中子句的输入顺序是不一样的,所以并不是从SELECT子句开始执行的,而是按照下面的顺序执行:
开始->FROM子句->WHERE子句->GROUP BY子句->HAVING子句->ORDER BY子句->SELECT子句->LIMIT子句->最终结果
每个子句执行后都会产生一个中间结果,供接下来的子句使用,如果不存在某个子句,就跳过
对比了一下,mysql和sql执行顺序基本是一样的, 标准顺序的 SQL 语句为:
select 考生姓名, max(总成绩) as max总成绩
from tb_Grade
where 考生姓名 is not null
group by 考生姓名
having max(总成绩) > 600
order by max总成绩
- 1
- 2
- 3
- 4
- 5
- 6
在上面的示例中 SQL 语句的执行顺序如下:
(1). 首先执行 FROM 子句, 从 tb_Grade 表组装数据源的数据
(2). 执行 WHERE 子句, 筛选 tb_Grade 表中所有数据不为 NULL 的数据
(3). 执行 GROUP BY 子句, 把 tb_Grade 表按 “学生姓名” 列进行分组(注:这一步开始才可以使用select中的别名,他返回的是一个游标,而不是一个表,所以在where中不可以使用select中的别名,而having却可以使用,感谢网友 zyt1369 提出这个问题)
(4). 计算 max() 聚集函数, 按 “总成绩” 求出总成绩中最大的一些数值
(5). 执行 HAVING 子句, 筛选课程的总成绩大于 600 分的.
(6). 执行 ORDER BY 子句, 把最后的结果按 “Max 成绩” 进行排序.
文章来源: andyguo.blog.csdn.net,作者:山顶夕景,版权归原作者所有,如需转载,请联系作者。
原文链接:andyguo.blog.csdn.net/article/details/121149749

- 点赞
- 收藏
- 关注作者
评论(0)