论文摘要笔记

摘 要
大数据技术随着互联网的发展及信息量爆炸增长的趋势应运而生。
面对异常庞 大的数据,多种分布式文件系统为大数据的存储提供了解决方案。
其中 Hadoop 由于 自身高扩展性、高可靠性等优点被业界广泛使用。HDFS 作为 Hadoop 的核心组件, 为处理大数据提供了文件存储服务。
然而 HDFS 更擅长处理流式的大文件,
面对海量小文件存储时的表现不佳。
原因:
因为Hadoop中一个最小的存储单元叫做Block[16],默认存储文件阈值为64MB。 小文件在存储时被分割成若干个内容连续的数据文件进行存储,小于 64MB 的文件会 占据节点空间但不占满整个空间。小文件数量的增多使得系统中的存储空间无法被完 全利用,存在大量的内存浪费的情况。
无结构文件(流式文件)
有结构文件(记录式文件)
通常业内将文件大小为 1KB-10MB 的数据称为小文件,
海量小文件问题(Lots of Small Files,简称 LOSF)
多级处理模块 MPM
(1)预处理模块。首先在所有文件中筛选出符合条件的小文件,进行简单分类后 等待处理。
(2)合并模块。基于空间最优化的原则,合并算法引入了合并队列和缓冲队列, 将小文件合并为尽可能接近数据块存储阈值的大文件。一方面直接减少了数据库中小 文件的数量,降低了内存消耗;另一方面避免合并后仍有大块的空白空间,使存储空 间得到最大程度的利用。
(3)二级索引模块。以小文件的修改日期为依据建立一级索引,小文件的文件名 及文件类型作为二级索引。虽然设计了两层索引,但索引的建立依据较为简单,且不 再作为 NameNode 的一部分进行存储。在降低 NameNode 内存消耗的同时也保证系 统的交互时间的不会大幅的增加。
(4)预取和缓存模块。用户在实际存储文件时,会对一部分文件频繁的进行读 取,增加预取和缓存模块,将用户读取次数较多的文件提前缓存下来,减少用户获取 这部分文件时产生的重复的交互时间。
(5)碎片整理模块。经过多次读写删除操作后,系统中会存在一些空白空间,将 这部分空白空间再利用,可以一定程度的提高系统的利用率。
存储文件
本文为了解决 HDFS 存储小文件效率低下的问题,
对 Hadoop 架构和 HDFS 存 储文件的流程进行详细分析,
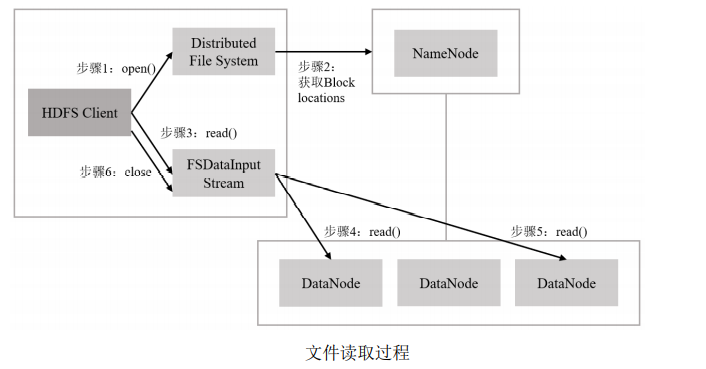
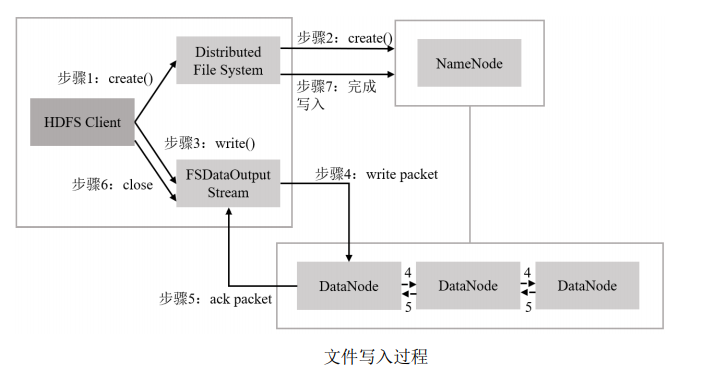
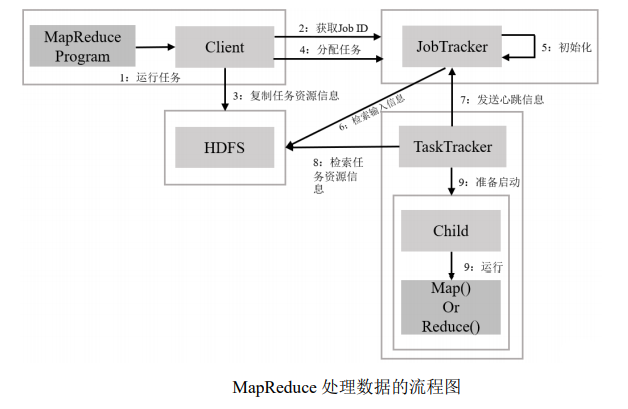
提出了引入**多级处理模块 MPM(Multilevel Processing Module for Small Files)**的方案。
-
该方案首先通过文件预处理模块,对系统中发出操 作请求的文件进行过滤,筛选 4.35MB 以下的文件为小文件,并将其按文件扩展名 进行初步分类。
-
随后文件合并模块会将预处理后的小文件合并成尽可能少的大文件, 以减少系统 NameNode 内存负载。
-
为了提高小文件的查询速度,方案中除了利用小 文件创建时间和小文件扩展名建立的二级索引模块,还引入了基于用户常用文件的 预取和缓存模块。
-
最后,针对系统长时间运行导致的碎片问题,当系统满足设定条 件时,碎片整理模块会对合并文件的空白空间进行清理,以提高系统空间的利用率。
本文将提出的 MPM 方案与三种 HDFS 现有存储方案:
现有解决办法
Hadoop 社区提出了 Hadoop
Archive(HAR)归档
Hadoop Archives(简称 HAR),顾名思义是一种文件归档技术。简单来说,就是 用户通过 archive()命令操纵一个 MapReduce 任务,将一定范围内的小文件合并成为一 个大文件,这个大文件中包括原始文件数据以及相应的索引。合并后的大文件被命名 为 HAR 文件,再传送给 HDFS 进行存储。
Sequence File[19]、
核心原理依旧是将小文 件合并成大文件,但存储结构不同。Sequence File 方案将其内部的小文件名及小文件 内容一一对应转化为 Key-Value 形式的数据。文件名是 Key,文件内容是 Value。
Map File
Map File 方案[43]在 Sequence File 方案的基础上,加入了真正的索引文件。如图 2- 8 所示是改进后的存储结构示意图。一个完整的 Map File 中除了大量 Key-Value 形式 的数据,还包括小文件的索引文件。
HDFS Federation[20]等
NameNode 主节点
中,NameNode 被水平扩展为 n 个空间,每个 NameNode n 执行来自总节 点 NameNode 的指令,并且向总节点登记和汇报信息。每个扩展节点之间相互独立, 管理本空间的元数据信息。
但是也正因为“分散管理”的技术原理,一旦系统中任意一个 NameNode 出现问题,该扩展节点下管理的所有空间将不可用,其中存储的数据将会 丢失,整个系统的数据不再完整。因此,尽管有着相对良好的存储性能,但高风险低 可靠性的数据特性还是让 HDFS Federation 未能很好的应用到实际场景中。
使系统中的文件数量大幅减少,从而降低存储文件所需的 节点内存和元数据数量,以此提升系统性能。但是目前的合并标准会导致例如跨块存 储、合并效率不高等新的问题。
将小文件的合并依据设 定为地理位置信息。将地理位置相近的小文件合并成大文件,并引入索引机制便于文 件查找。这种方法针对拥有地理位置信息的特殊数据合并效率较高,对其他类型的数 据没有可用性。另外这个方法的索引机制较为复杂,随着存储数据量的不断增多,文 件读取效率反而会降低。
为了提高小文件合并后文件之间的结构相关性和逻辑相关性;三级缓存策略。通过预取文件元数据、索引数据以及数据本身的方法增强文件之间的 结构相关性;
- 总结: 实现原理都是将小文件按照某些标准组合成一定大小的合并文件,再将其放入 HDFS 进行存储。
当存取数量为 100000 的文件时, MPM 方案可为系统节省 95.56%的内存占用,空间利用率高达 99.92%。
同等条件下, 与原生存储方案相比,MPM 方案的写入速率是未优化前的两倍;
由于合并机制步骤 更多,写入耗时只降低了 31%。读取速率提升了 2.25 倍左右,读取耗时是所有方案 中最低的。
实验结果表明,MPM 方案对 HDFS 的存储性能改善明显。大幅减少了系 统中的文件数量,有效降低 NameNode 内存负载,提高了系统内存利用率,实现了 高速率的小文件读写性能。
关键词:HDFS、海量小文件、文件合并、二级索引


文章来源: hiszm.blog.csdn.net,作者:孙中明,版权归原作者所有,如需转载,请联系作者。
原文链接:hiszm.blog.csdn.net/article/details/115437815

- 点赞
- 收藏
- 关注作者
评论(0)