面试高频|一文详解Flink背压

不知为何,最近的我开始走下坡路了。。。
1 故事的开始
此刻,我抬头看了一眼坐在对面的这个家伙: 格子衫、中等身材,略高的鼻梁下顶着一副黑框眼镜,微眯的目光透出丝丝倦意,正一眨不眨地盯着我看。

我心里直犯嘀咕: 我又有什么好看的呢?不过是A君你用来换取面包、汽车的工具罢了。虽然陪伴了五年的时光,想来也就是如此~
说到这,忘了自我介绍了。我叫Flink,当然,我还是喜欢你们叫我的全名: Apache Flink,因为这样听起来很有科技感。 我是目前最火的大数据实时计算引擎之一。
之所以敢这么说,是因为目前我在实时领域确实处于独领风骚的地位,不信请看下面的统计:
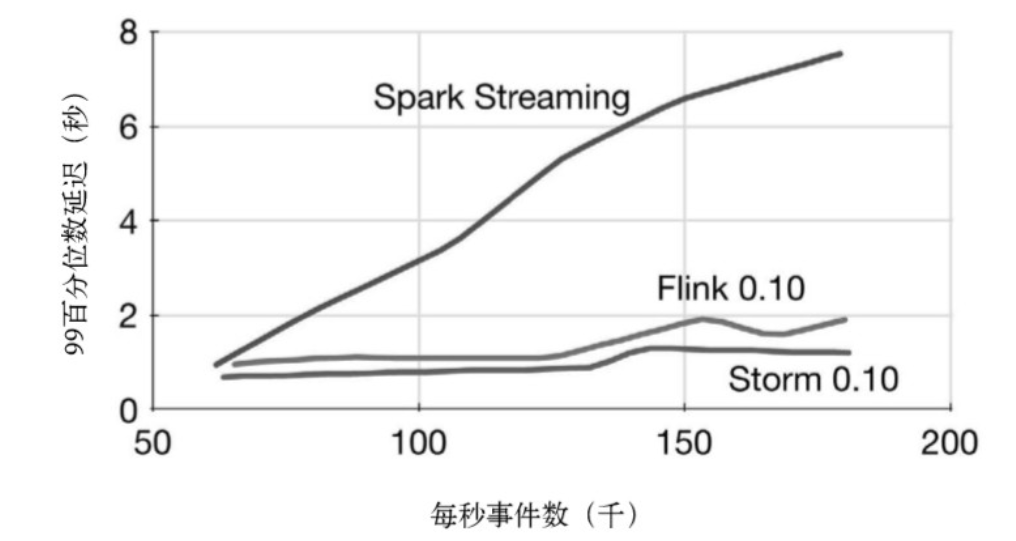
此处需要@一下我的老大哥:Apache Spark,我听说一度出现过"Flink的出现,Spark是否慢慢成为鸡肋"的言论。咱也不敢说,也不敢问,对于前辈还是保持尊重和理性。
"咳"~ 一声轻咳把我拉回了现实,A君又开始调试代码了~
2 我开始有压力了
其实我是在上周和A君再次遇见的,之前听说他在我的好朋友:Kafka那里呆了一周,好像是准备搞一个大事情。
等到他找到我, 才知道公司准备建设实时数仓。需要我和Kafka兄弟一起加入,处理亿级别实时数据。
对于实时数仓我大抵是了解的。再看看A君的老大拿出的架构方案,心中暗喜:这可是到了我的专业领域。

整体架构并不难,很好理解。
-
程序实时获取源数据,放置kafka ods层存储 -
进行ods->dwd->dws层实时加工计算,结果写进kafka -
再加一条离线处理流程,作为备用
我看了一眼旁边跃跃欲试的Kafka兄弟,互相点了点头,我们开始吧~
作为老搭档,我和Kafka兄弟配合的很默契,A君也是个老手,于是我们在短短的一周内就出色的完成了初步任务。
我可以给你看看我们的部分配合成果:
- src.main.scala.com.xxproject.xx
|--handler
|---FlinkODSHandler.scala
|---FlinkDWHandler.scala
|---FlinkADSHandler.scala
...
|--service
|---KafkaSchdulerService.scala
|---SchdulerService.scala
...
|--config/util/model
|---KafkaUtils.scala
|---XXDataModel.scala
...
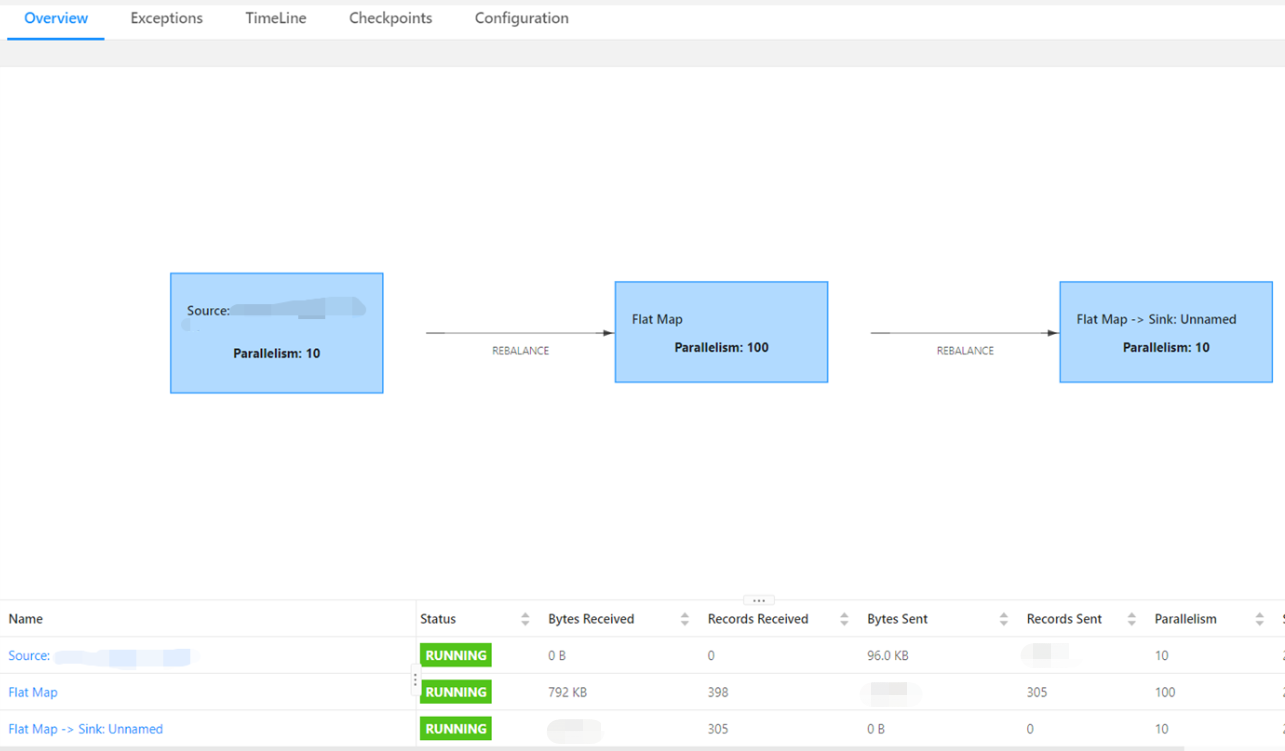
春风得意马蹄疾~ 此刻的心情舒服极了,我们仨简直就是完美搭档。。
可是好景不长。来到第二周,我渐渐的发现自己开始变慢了~
具体的表现为 :
运行开始时正常,到了后面就出现大量Task任务 等待少量Task任务开始报 checkpoint超时问题Kafka数据堆积,无法消费
我有点慌,去看了下自身的状况,结果吓了一大跳:
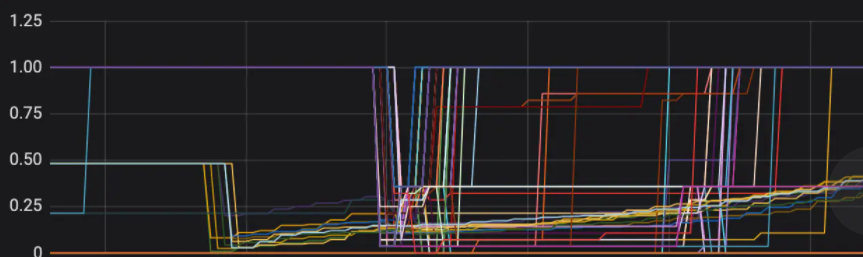
无论是输入还是输出,缓冲区内存都被占满了。数据处理不过来,barrier流动极为缓慢,大量checkpoint生成时间变长。
我发生了背压问题!!!
3 我的反压机制
在默默的进行一段时间的自我调节后,问题依然没有解决。
同时,我的周围不断拉响警报,内存频繁告急。转眼间我的Task执行页面已被红色High标识占满~

没有办法,最终我还是向A君发出了告警~
A君收到消息,盯着我看了好一会,叹了口气。我觉得有点不好意思,感觉把事情搞砸了。。
他没有多说什么,只是问起了我的反压机制,说要从源头解决问题。
下面是A君和我的对话
1)反压一般有哪些情况?
按照我以往的经验,一般出现反压就是下游数据的处理速度跟不上上游数据的产生速度。
可以细分两种情况:
-
当前Task任务处理速度慢,比如task任务中调用算法处理等复杂逻辑,导致上游申请不到足够内存。 -
下游Task任务处理速度慢,比如多次collect()输出到下游,导致当前节点无法申请足够的内存。
2)频繁反压的影响是什么?
频繁反压会导致流处理作业数据延迟增加,同时还会影响到Checkpoint。
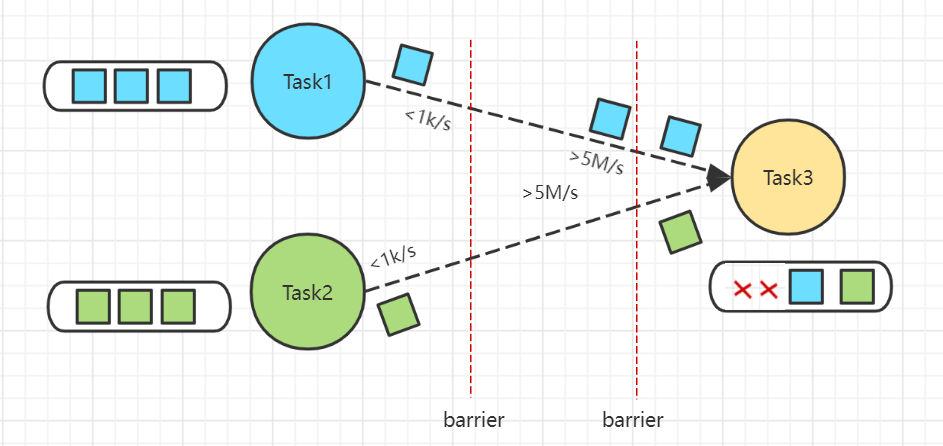
Checkpoint时需要进行Barrier对齐,此时若某个Task出现反压,Barrier流动速度会下降,导致Checkpoint变慢甚至超时,任务整体也变慢。
长期或频繁出现反压才需要处理,如果由于
网络波动或者GC出现的偶尔反压可以不必处理。
3)你是怎么发现反压的?
在我的Web界面,我会从Sink到Source逆向Task排查。逐个查看BackPressure详情,找到第一个出现反压的Task。
下面这是正常的状况~

我的内部检测原理
BackPressure界面定期采样Task线程栈信息,统计线程请求内存Buffer的阻塞频率,判断节点是否处于反压状态。
-
默认情况下,频率小于 0.1显示正常 -
(0.1,0.5)为LOW,背压轻微 -
超过 0.5为 HIGH,需要注意反压
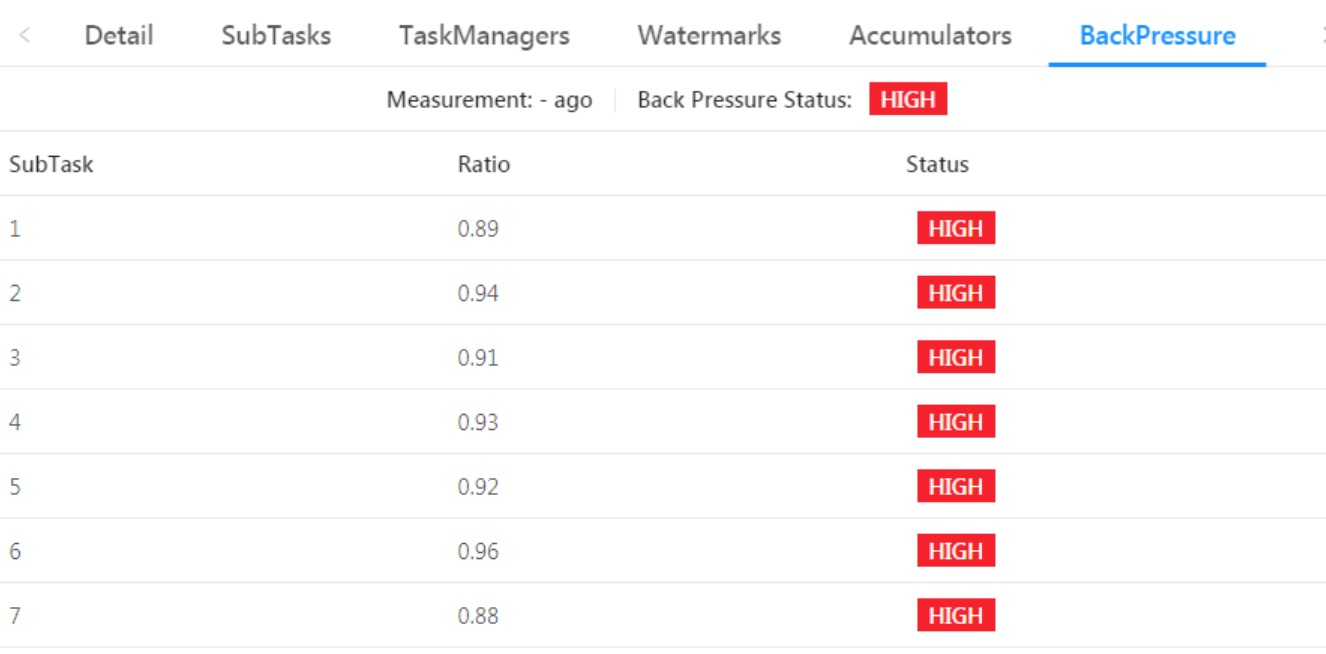
此时,我指给A君看了目前项目的BackPressure页面,这明显是不正常的状况。
4)反压机制原理是什么?
A君顿了顿嗓子,提示我此处讲的仔细一点。 我整理了下思路,决定先从限流开始说起:
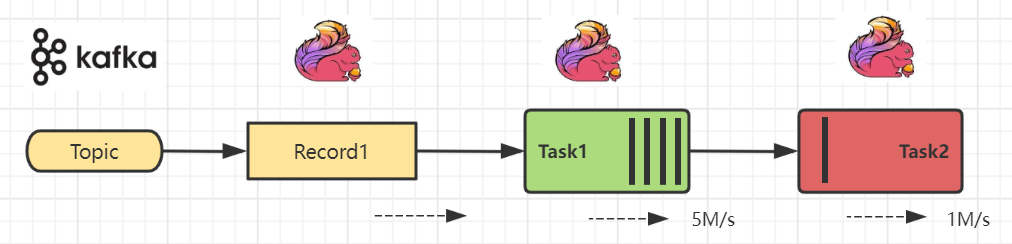
-
数据流程
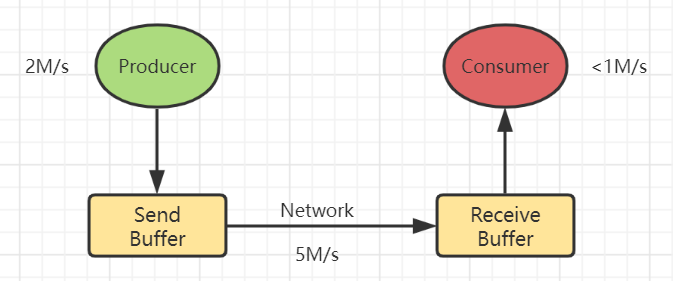
整体流程可类比为生产者->消费者体系。上游生产者发送数据(2M/s)至Send Buffer,途径网络传输(5M/s)到Receive Buffer, 最终下游Consumer消费(<1M/s)。
这明显是不行的,下游速度慢于上游速度,数据久积成疾~ 需要做限流。
-
限流

这很好理解。既然上游处理较快,那么我添加一个限流机制将其速度降下来,让上下游速度基本一致,这样不就解决了吗。。
其实不然,这里有几个问题:
我无法提前预估下游实际速度(流速限制设置多少) 常碰到网络波动等情况,上下游的流速是 动态变化的
考虑到这些原因,我的内部提供一种强大的反压机制:
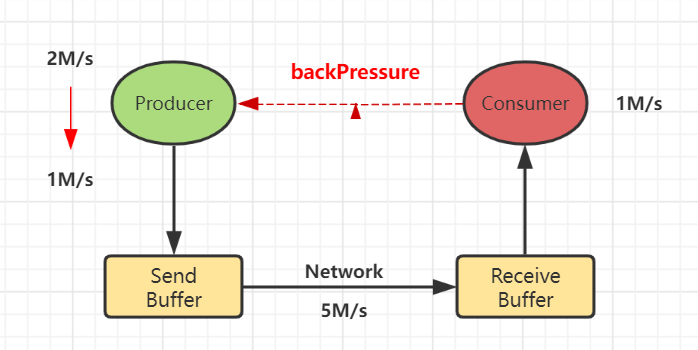
上下游动态反馈,如果下游速度慢,则上游限速;否则上游提速。实现动态自动反压的效果。
-
反压机制示意
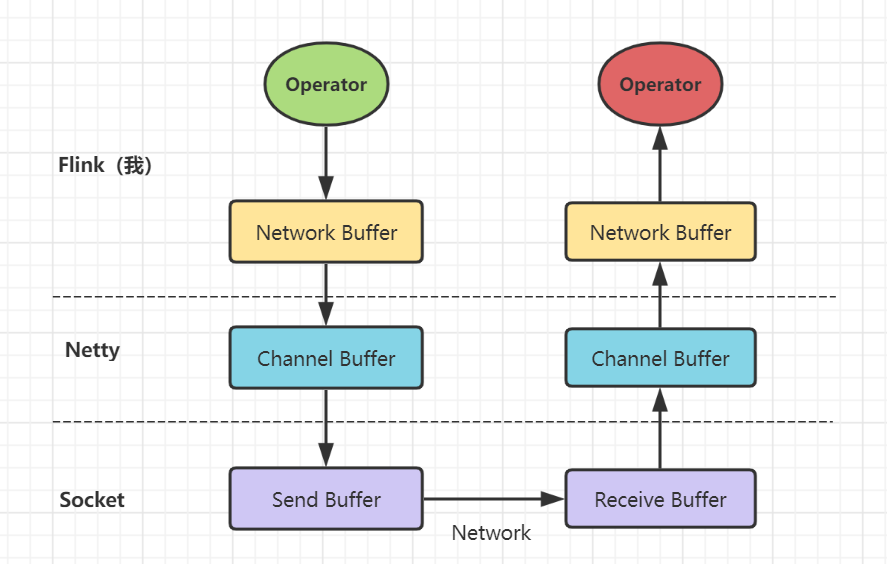
上游发送网络数据前经过自身的Network Buffer层,之后往下传输到Channel Buffer层(Netty通道)。最终通过网络传输,层层传递达到下游。
Network Buffer、Channel Buffer和Socket Buffer通俗理解就是
用户态和内核态的区别,处于不同的交换空间和操作系统。
有关内核态和用户态原理,有兴趣的小伙伴欢迎添加个人微信: youlong525 进行讨论~
-
反压机制原理
前面做了一些铺垫,这里我给A君总结了我的反压机制的运行流程:

-
每个
TaskManager维护共享Network BufferPool(Task共享内存池),初始化时向Off-heap Memory中申请内存。 -
每个Task创建自身的
Local BufferPool(Task本地内存池),并和Network BufferPool交换内存。 -
上游
Record Writer向 Local BufferPool申请buffer(内存)写数据。如果Local BufferPool没有足够内存则向Network BufferPool申请,使用完之后将申请的内存返回Pool。 -
Netty Buffer拷贝buffer并经过Socket Buffer发送到网络,后续下游端按照相似机制处理。 -
当下游申请buffer失败时,表示当前节点
内存不够,则逐层发送反压信号给上游,上游慢慢停止数据发送,直到下游再次恢复。
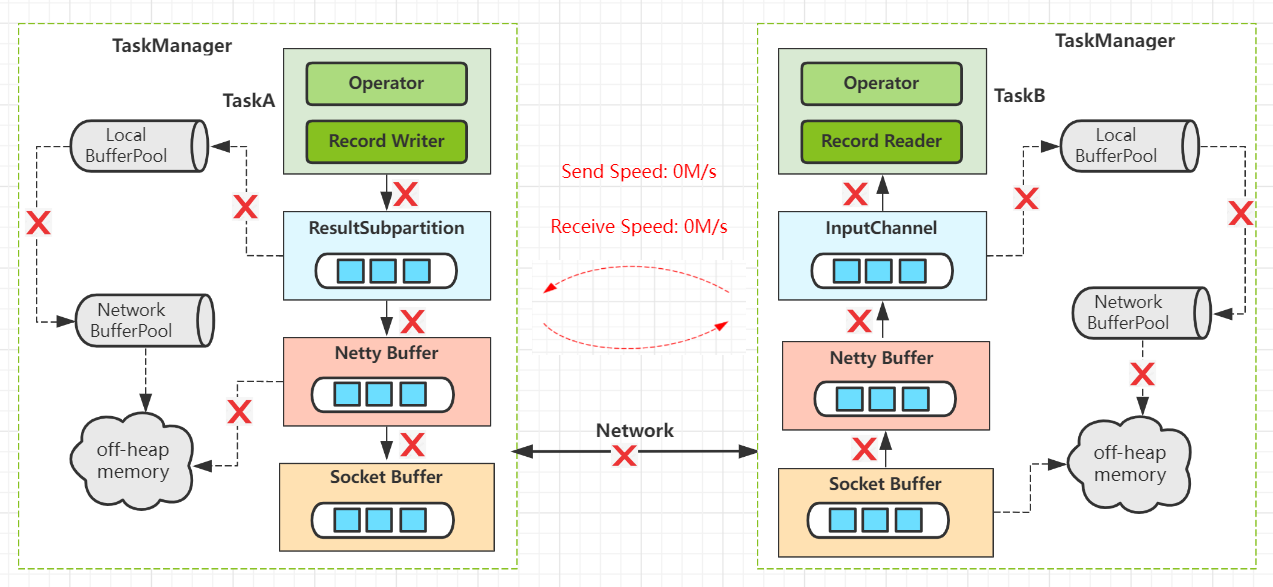
所以,我的反压机制类似于Java中的阻塞队列,如下图我的内存级的反压工作原理示意。

Task任务通过与Local BufferPool和Network BufferPool协作进行内存申请和释放,同时下游内存使用情况实时反馈给上游,实现动态反压。
A君听完我的回答,陷入了沉思~
4 我要减压
其实我心里也很迷惑。我对自己的反压机制很有信心,会不会是其他原因影响到了反压处理?
这时,一旁的A君打开了我的WEB UI,口中喃喃的吐出几个词: 数据倾斜和并发。
4.1 第一次尝试
我瞬间明白了过来,转眼去看屏幕。
我分别查看了各个SubTask情况,发现在某个Checkpoint中对应的state size值存在个别异常,竟达到了10G左右大小!!
再看下分区内的其他值(如图):

发生数据倾斜了~
我心里有了底,立马和A君一起找出了这些特殊的Key,进行预聚合打散和数据拆分,再次运行。

感觉有那么一点效果,但是还是有蛮多的高峰值。。
4.2 第二次尝试
此刻又陷入了僵局。
没办法,我加大了自身的一点内存。想了想,又加大了算子的并发度,毕竟增加线程数总归会缓解一些计算压力。
不甘心的调整了参数之后,结果依然没有太多提升。
4.3 第三次尝试
A君开始重新梳理我的整体计算流程,然后改动了一个参数。
我看了下,还是修改并发度。心中不以为然,我刚才可就试过了这个。。
好像有点不对劲。。

这就是我要的结果!!我不禁喊了出来。
他笑了笑,告诉我这是用到了我的算子链机制。
算子链
通过将下游算子和上游算子设置相同并发度,可自动形成算子链
这样做的好处是:
-
有效减少线程间切换和数据缓存开销 -
提高吞吐量且降低延迟

整个流程中形成多个算子链,导致线程开销和内存使用率下降。我的反压情况自然也变得缓和了。
我不禁大受震撼~~
5 一日看尽长安花
最终在A君的协助下,我的速度回来了。几天高压的日子彻底结束,此刻尽丝滑~
我缓缓吐出一口气,有点欣慰的看着最后的结果:

不自觉地抬头看了眼A君,他也露出了久违的微笑。
我是Flink,现在没有压力~
本文完。
》》》更多好文,请大家关注我的公众号: 大数据兵工厂

- 点赞
- 收藏
- 关注作者
评论(0)