ARM裸机开发:Cortex-A7 MPCore架构基础

ARM裸机开发:Cortex-A7 MPCore架构基础
一、Cortex-A7 MPCore简介
- Cortex-A7 MPCore是一款高性能低功耗的处理器,使用的是
ARMv7-A架构,28nm 工艺下,Cortex-A7 可以运行在1.2~1.6GHz主频,有浮点单元、NEON 和32KB 的L1 缓存,在典型场景下功耗小于100mW, 这使得它非常适合对功耗要求严格的移动设备 - Cortex-A7 MPCore处理器可支持核心数目:1-4个核心,通过SCU进行调度

其搭载的核心中L1缓存分为(L1 instruction cache指令缓存和L1 data cache数据缓存),可选大小范围:8KB、16KB、32KB、64KB;L2 Cache 可以不配,也可以选择搭载128KB、256KB、512KB、1024KB
备注:L1 和 L2 是计算机中缓存内存的级别,处理器能够在缓存中找到其下一次操作所需的数据,与从随机访问内存中获取数据相比,节省更多时间,级别越高与处理器越接近,访问速度也越快
-
Cortex-A7 MPCore 架构
基于ARMv7-A架构,进行如下扩展:
① SIMDv2 扩展整形和浮点向量操作。
② 提供了与 ARM VFPv4 体系结构兼容的高性能的单双精度浮点指令,支持全功能的IEEE754。
③ 支持大物理扩展(LPAE),最高可以访问40 位存储地址,也就是最高可以支持1TB 的内存。
④ 支持硬件虚拟化。
⑥ 支持Generic Interrupt Controller(GIC)V2.0。
⑦ 支持NEON,可以加速多媒体和信号处理算法。总线架构:
Cortex-A7 MPCore处理器ACE和调试接口符合AXI和APB
调试架构:
使用了ARMv7.1 ARM Debug架构,符合CoreSight架构
通用中断控制器体系结构:
Cortex-A7 MPCore处理器使用了通用中断控制器(GIC) v2.0架构
通用定时器架构:
Cortex-A7 MPCore处理器实现了ARM通用定时器架构,包括对虚拟化扩展的支持。
-
处理器特性
-
有直接和间接分支预测的顺序管道。
-
带有内存管理单元(MMU)的哈佛1级(L1)内存系统。
-
APB调试接口,支持整数处理器时钟比率,最高包括1:1。
-
通过嵌入式跟踪宏单元格(ETM)接口支持跟踪。
-
可选的VFPv4-D16 FPU与无trap执行或媒体处理引擎(MPE)与NEON技术。
二、Cortex-A 处理器运行模型
Cortex-A7有9种运行处理模式:
| 运行模式 | 说明 |
|---|---|
| User(USR) | 用户模式,非特权模式,大部分程序运行的时候就处于此模式。 |
| FIQ | 快速中断模式,进入 FIQ 中断异常 |
| Supervisor(SVC) | 超级管理员模式,特权模式,供操作系统使用。 |
| Monitor(MON) | 监视模式,这个模式用于安全扩展模式。 |
| Abort(ABT) | 数据访问终止模式,用于虚拟存储以及存储保护。 |
| Hyp(HYP) | 超级监视模式,用于虚拟化扩展。 |
| Undef(UND) | 未定义指令终止模式。 |
| System(SYS) | 系统模式,用于运行特权级的操作系统任务 |
| IRQ | 一般中断模式。 |
User(USR)用户模式为非特权模式
其它 8 种运行模式都是特权模式
不同模式间的资源使用权限不一样
模式间切换方式:1.软件进行切换,2.中断切换,3.异常切换;用户模式是不能直接进行切换的,需要借助异常来完成模式切换,当要切换模式的时候,应用程序可以产生异常,在异常的处理过程中完成处理器模式切换;当中断或者异常发生以后,处理器就会进入到相应运行模式的异常模式种,每一种模式都有一组寄存器供异常处理程序使用,这样的目的是为了保证在进入异常模式以后,用户模式下的寄存器不会被破坏。
补充一个Tips:Cortex-M架构的运行模式只有两种,一个特权一个非特权
三、CorteX-A 寄存器组
3.1 寄存器组成
ARM 架构提供了 **16 个 32 位的通用寄存器(R0~R15)**供软件使用
在非特权模式下,前 15 个(R0~R14)可以用作通用的数据存储,R15 是程序计数器 PC,用来保存将要执行的指令。ARM 还提供了一个当前程序状态寄存器CPSR 和一个备份程序状态寄存器 SPSR,SPSR 寄存器就是CPSR寄存器的备份,寄存器如下图,其中R13用来做堆栈SP指针寄存器,R14用来做LR链接寄存器,R15为程序寄存器,指向下一步程序的执行地址:
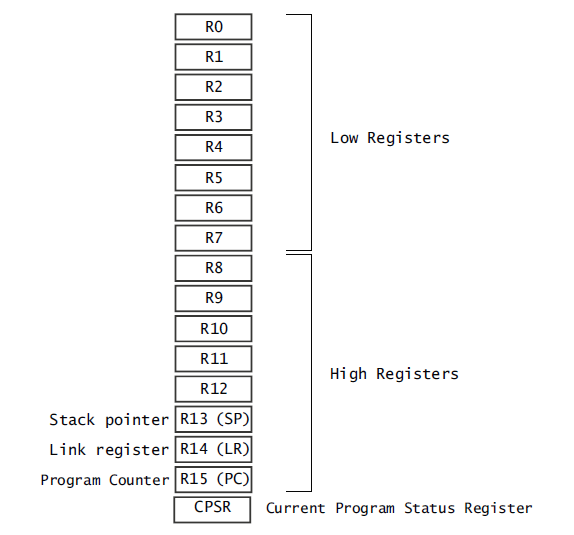
但在非特权模式下,R0到R15映射的寄存器就不一定是上图的寄存器了,具体映射关系如下:
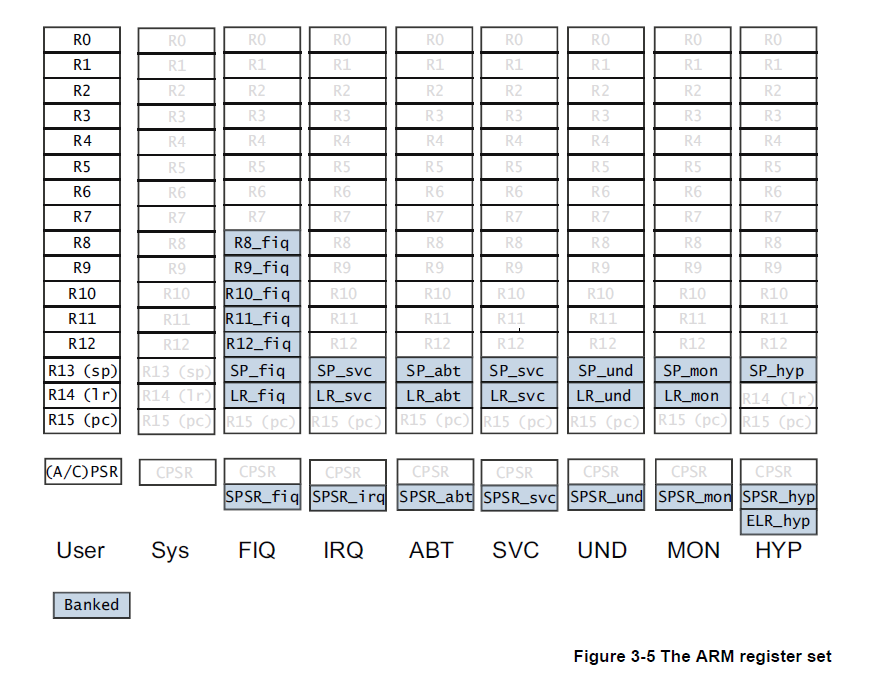
上图的浅色部分是非特权模式与特权模式相同的寄存器,加深的部分则是对应模式下重新映射的寄存器,访问时会访问深色部分寄存器
我们可以看出,在所有的模式中,低寄存器组(R0~R7)是共享同一组物理寄存器的,只是一些高寄存器组在不同的模式有自己独有的寄存器,比如 FIQ 模式下R8~R14 是独立的物理寄存器。假如某个程序在 FIQ 模式下访问 R13 寄存器,那它实际访问的是寄存器 R13_fiq,如果程序处于 SVC 模式下访问R13寄存器,那它实际访问的是寄存器 R13_svc
根据上图,Cortex-A的内核寄存器组成如下:
-
34 个通用寄存器,包括 R15 程序计数器(PC),这些寄存器都是 32 位的。
-
8 个状态寄存器,包括 CPSR 和 SPSR。
-
Hyp 模式下独有一个 ELR_Hyp 寄存器
3.2 通用寄存器
R0-R15为通用寄存器,具体可以分为以下三类:
- 未备份的寄存器,R0 - R7
- 备份的寄存器,即R8 - R14
- 程序计数器PC,即 R15
-
未备份寄存器
寄存器R0 - R7 低八位寄存器是未备份寄存器,因为R0 - R7 对于9个运行模式是共用的寄存器,不同的模式下,这 8 个寄存器中的数据就会被破坏,所以这 8 个寄存器 并没有被用作特殊用途 -
备份寄存器
R8 - R14为备份寄存器,-
R8-R12: R8 - R12寄存器在Usr和FIQ模式下,对应着不同的寄存器,在切换时因为映射的寄存器改变了,不需要对原先的寄存器做备份,进行现场保护,所以是备份寄存器
-
R13: R13则对应着8个寄存器,其中用户模式(User)和系统模式(Sys)共用 的,剩下的 7 个分别对应 7 种不同的模式。同时R13 也叫做 SP,用来做为栈指针。基本上每种模式 都有一个自己的 R13 物理寄存器,应用程序会初始化 R13,使其指向该模式专用的栈地址,这就是常说的 SP 指针
-
R14: R14 也称为连接寄存器(LR), LR 寄存器在 ARM 中主要用作如下两种用途:
-
每种处理器模式使用 R14(LR)来存放当前子程序的返回地址,如果使用 BL 或者 BLX 来调用子函数的话,R14(LR)被设置成该子函数的返回地址,在子函数中,将 R14(LR)中的值赋给 R15(PC)即可完成子函数返回,比如在汇编子程序中可以使用如下两种代码
MOV PC, LR @直接将寄存器 LR 中的值赋值给 PC,实现跳转- 1
在子函数的入口出将 LR 入栈
PUSH {LR} @通过堆栈将 LR 寄存器压栈- 1
在子函数的最后面出栈即可
POP {PC} @然后将上面压栈的 LR 寄存器数据出栈给 PC 寄存器 @严格意义上来讲应该是将LR-4 赋给 PC,因为 3 级流水线,这里只是演示代码。- 1
- 2
-
当异常发生以后,该异常模式对应的 R14 寄存器被设置成该异常模式将要返回的地址, R14 也可以当作普通寄存器使用。
-
-
程序计数器
程序计数器 R15 也叫做 PC,R15 保存着当前执行的指令地址值加 8 个字节,这是因为 ARM 的流水线机制导致的。ARM 处理器 3 级流水线:取指->译码->执行,这三级流水线循环执行, 比如当前正在执行第一条指令的同时也对第二条指令进行译码,第三条指令也同时被取出存放 在 R15(PC)中。我们喜欢以当前正在执行的指令作为参考点,也就是以第一条指令为参考点, 那么 R15(PC)中存放的就是第三条指令,换句话说就是 R15(PC)总是指向当前正在执行的指令 地址再加上 2 条指令的地址。对于 32 位的 ARM 处理器,每条指令是 4 个字节,所以: R15 (PC)值 = 当前执行的程序位置 + 8 个字节。和以前的51单片机PC指针相比,因为三级指令流水线,所以多了个指令偏移值(两条指令的长度,8个字节)
3.3 程序状态寄存器
程序状态寄存器 CPSR 可以在任何模式下被访问,他包含了条件标志位、中断禁止位、当前处理器模式标志等一些状态位以及一些控制位,因为能被所有模式访问,所以每种模式下各自还存在CPSR寄存器的备份寄存器SPSR,用来保存对应模式运行时的CPSR状态,这样即使CPSR被别的模式改变了,通过各自的备份寄存器也能恢复到原来的状态,但因为User和Sys模式不是异常模式,所以没有配备SPSR,故不能在 User 和 Sys 模式下访问 SPSR!
SPSR和CPSR寄存器结构相同,如下图:
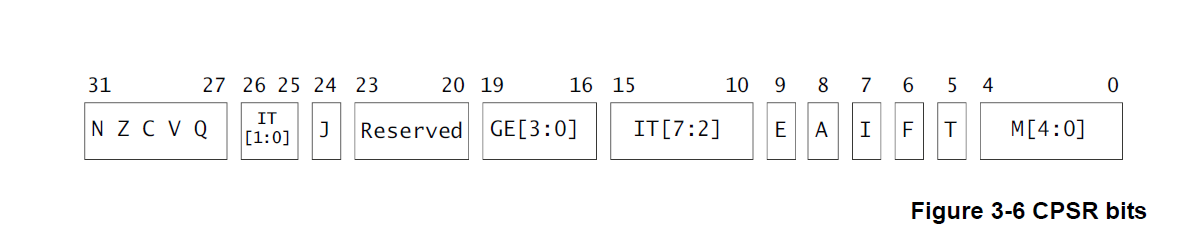
| 寄存器 | 功能 |
|---|---|
| N(bit31) | 有符号整数运算的时候,N=1 表示运算对的结果为负数,N=0 表示结果为正数 |
| Z(bit30) | Z=1 表示运算结果为零,Z=0 表示运算结果不为零 对于 CMP 比较指令,Z=1 表示 进行比较的两个数大小相等 |
| C(bit29) | 在加法指令中,当结果产生了进位,则 C=1,表示无符号数运算发生上溢,其它 情况下 C=0。在减法指令中,当运算中发生借位,则 C=0,表示无符号数运算发生下溢,其它 情况下 C=1。对于包含移位操作的非加/减法运算指令,C 中包含最后一次溢出的位的数值,对 于其它非加/减运算指令,C 位的值通常不受影响。 |
| V(bit28) | 对于加/减法运算指令,当操作数和运算结果表示为带符号数时,V=1 表示符号位溢出,通常其他位不影响 V 位。 |
| Q(bit27) | 仅 ARM v5TE_J 架构支持,表示饱和状态,Q=1 表示累积饱和,Q=0 表示累积 不饱和 |
| IT[1:0] (bit26:25) | 和 IT[7:2]一起组成 IT[7:0],作为 IF THEN 指令执行状态。 |
| J(bit24) | 仅 ARM_v5TE-J 架构支持,J=1 表示处于 Jazelle 状态,此位通常和 T(bit5)位一起 表示当前所使用的指令集,如下表指示 |
| GE[3:0] (bit19:16) | SIMD 指令有效,大于或等于 |
| IT[7:2] (bit15:10) | 参考IT[1:0] 组合使用 |
| E(bit9) | 大小端控制位,E=1 表示大端模式,E=0 表示小端模式 |
| A(bit8) | 禁止异步中断控制位,A=1 表示禁止异步中断 |
| I(bit7) | I=1 禁止 IRQ,I=0 使能 IRQ。 |
| F(bit6) | F=1 禁止 FIQ,F=0 使能 FIQ |
| T(bit5) | 控制指令执行状态,表明本指令是 ARM 指令还是 Thumb 指令,通常和 J(bit24)一 起表明指令类型,参考 J(bit24)位。 |
| M[4:0] | 处理器模式控制位,具体含义下表 |
J & T 位表示当前指令集:
| J | T | 描述 |
|---|---|---|
| 0 | 0 | ARM |
| 0 | 1 | Thumb |
| 1 | 1 | ThumbEE |
| 1 | 0 | Jazelle |
Jazelle:允许在某些架构的硬件上加速执行Java bytecode
Thumb:一种16-bit指令模式,在Thumb模式下,较小的opcode有更少的功能性
ThumbEE:在所处的执行环境下,使得指令集能特别适用于执行阶段(Runtime)的编码产生(例如即时编译)
处理器模式控制位:
| M[4:0] | 处理器对应模式 |
|---|---|
| 10000 | User 模式 |
| 10001 | FIQ 模式 |
| 10010 | IRQ 模式 |
| 10011 | Supervisor(SVC)模式 |
| 10110 | Monitor(MON)模式 |
| 10111 | Abort(ABT)模式 |
| 11010 | Hyp(HYP)模式 |
| 11011 | Undef(UND)模式 |
| 11111 | System(SYS)模式 |
文章来源: blog.csdn.net,作者:JeckXu666,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/qq_45396672/article/details/118345071

- 点赞
- 收藏
- 关注作者
评论(0)