【SparkSQL笔记】SparkSQL的Dataset操作大全(二)

SparkSQL的Dataset/DataFrame操作大全
简介说明
1. Spark程序中利用SparkSession对象提供的读取相关数据源的方法读取来自不同数据源的结构化数据,转化为Dataset(DataFrame),当然也可以将现成RDDs转化为Dataset(DataFrame),在转化为Dataset(DataFrame)的过程中,需自识别或指定Dataset(DataFrame)的Schema,之后可以直接通过Dataset(DataFrame)的API进行数据分析,当然也可以直接将Dataset(DataFrame)注册为table,直接利用Sparksession提供的sql方法在已注册的表上进行SQL查询,Dataset(DataFrame)在转化为临时视图时需根据实际情况选择是否转化为全局临时表
2. SparkSQL可以以RDD对象,Parquet文件,Json文件,Hive表以及通过JDBC连接到关系型数据库表作为数据源来生成Dataset(DataFrame)对象,进而在该Dataset(DataFrame)对象上通过各种实例操作讲解Dataset(DataFrame)API的使用。本次以JSON文件为数据源。
数据展示:
{"name":"王明","age":15,"sex":"男","institute":"计算机1班","phone":"1"}
{"name":"李红","age":16,"sex":"女","institute":"计算机2班","phone":"2"}
{"name":"刘强","age":18,"sex":"男","institute":"计算机1班","phone":"3"}
{"name":"张三","age":12,"sex":"男","institute":"计算机3班","phone":"4"}
{"name":"李四","age":12,"sex":"男","institute":"计算机2班","phone":"5"}
{"name":"王五","age":11,"sex":"男","institute":"计算机3班","phone":"6"}
{"name":"刘旺","age":17,"sex":"男","institute":"计算机1班","phone":"7"}
{"name":"赵笋","age":18,"sex":"女","institute":"计算机2班","phone":"8"}
{"name":"刘晓红","age":20,"sex":"女","institute":"计算机1班","phone":"9"}
{"name":"王志利","age":15,"sex":"男","institute":"计算机2班","phone":"10"}
{"name":"王刚","age":19,"sex":"男","institute":"计算机2班","phone":"11"}
{"name":"李培","age":12,"sex":"男","institute":"计算机1班","phone":"12"}
{"name":"李狗蛋","age":15,"sex":"男","institute":"计算机3班","phone":"13"}
{"name":"王麻子","age":11,"sex":"男","institute":"计算机3班","phone":"14"}
{"name":"孙艳红","age":12,"sex":"女","institute":"计算机1班","phone":"15"}
{"name":"孙晓留","age":15,"sex":"男","institute":"计算机2班","phone":"16"}
{"name":"吴刚","age":16,"sex":"男","institute":"计算机1班","phone":"17"}
{"name":"郑成","age":12,"sex":"男","institute":"计算机1班","phone":"18"}
{"name":"诸葛燕","age":16,"sex":"女","institute":"计算机3班","phone":"19"}
{"name":"逍遥子","age":17,"sex":"男","institute":"计算机1班","phone":"20"}
1. Dataset(DataFrame)的actions操作(行动)
RDD的操作分为两大类,转化操作和行动操作,其中转化操作实际上是逻辑分析过程的实现,但是由于惰性计算的原因,只有当行动操作出现时,才会触发真正的计算
同样,Dataset(DataFrame)提供的API也是采用此种分类方法,有实现逻辑运算的转化操作,如select,where,orderBy,groupBy等负责指定结果列,过滤,排序,分组的方法,和负责触发计算,回收结果的行动操作。需要注意的是,无论直接使用sql()方法查询Dataset注册后的表还是通过调用提供转化操作API组合出来的类似的sql表达都会交由Spark SQL的解析,优化引擎——Catalyst进行解析优化,这样的底层自带优化功能的设计给了SparkSQL模块使用者极大地便利,即使我们我们的操作或者sql不高效也没事。
1.1 show:展示数据
以表格的形式在输出中展示DS(Dataset)中的数据,类似于select * from table_name
show的方法有五种调用方式:

他们的区别就在于参数不同。
numRows:即要展示的行数,默认20行
truncate:取值为boolean类型的时候表示一个字段是否最多展示20个字符,默认为true,是int类型就是指定展示的字符数
实例:
(1):展示前五条数据
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
// 读取文件转成JavaRDD
Dataset<Row> studentDataset = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student2.json");
studentDataset.show(5);
// 关闭saprkSesison 这里的close和stop是一个样 2.1.X开始用close 2.0.X使用的stop
sparkSession.close();
}
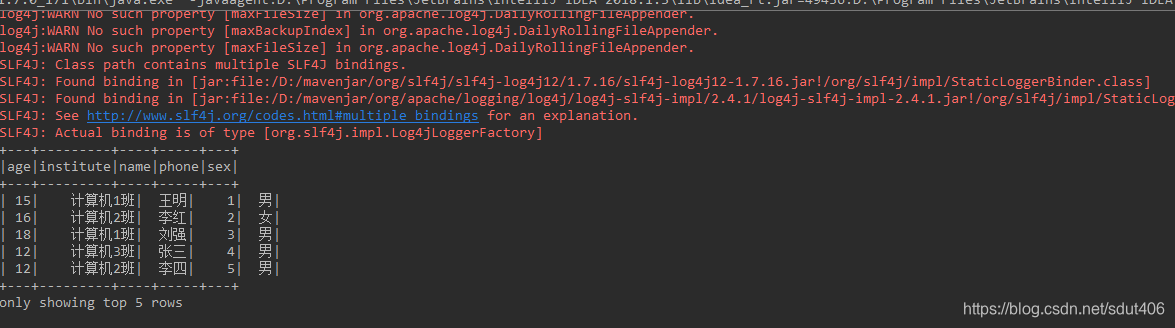
(2)设置展示四个字符
studentDataset.show(5,4);
结果只展示了一个字符。。。看了源码是因为如果少于五个只展示一个。。。

最终:

1.2 collect:获取所有的数据到数组

如果使用的是Java,文档推荐使用collectAsList

public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
// 读取文件转成JavaRDD
Dataset<Row> studentDataset = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student2.json");
List<Row> collect = studentDataset.collectAsList();
for (Row row : collect) {
System.out.println(row);
}
// 关闭saprkSesison 这里的close和stop是一个样 2.1.X开始用close 2.0.X使用的stop
sparkSession.close();
}
日志显示:

注意:
collect()和collectAsList()方法,用来从DataFrame中获取整个数据集。
如果当你的程序将原始的DataFrame(数据量很大)中的数据进行层层处理筛选,得到了包含着最终结果的DataFrame(数据量小)并且希望从DataFrame以Array、List取出结果并进行下一步处理时,可以使用它。
因为这两个方法是将集群中的目标变量的所有数据取回到一个结点当中,所以当你的单台结点的内存不足以放下DataFrame中包含的数据时就会出错。因此,collec()、collectAsList()不适用于特别大规模的数据集。
1.3 describe(cols: String*):获取指定字段的统计信息
这个方法可以动态的传入一个或者多个String类型的字段名,结果仍然为DS对象,用于统计数值类型字段的统计值
使用实例:
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
// 读取文件转成JavaRDD
Dataset<Row> studentDataset = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student2.json");
studentDataset.describe("age","phone").show();
// 关闭saprkSesison 这里的close和stop是一个样 2.1.X开始用close 2.0.X使用的stop
sparkSession.close();
}
日志显示:

使用describe()函数,会得到以下信息:
Count:记录条数
Mean:平均值
Stddev:样本标准差
Min:最小值
Max:最大值
进而掌握大规模结构化数据集的某字段的统计信息
1.4 first,head,take,takeAsList:获取若干行记录

first,head,take,takeAsList用来获取部门记录,与collect,collectAsList获取全部记录相对应
first:获取第一行记录
head:获取第一行记录
head(int n)获取前n行记录,返回的是Array
take(int n):获取前n行记录,返回的是Array
takeAsList(int n):获取前n行数据,并以List的形式展现
以Row或者Array[Row]的形式返回一行或多行数据。first和head功能相同。
take和takeAsList方法会将获得到的数据返回到Driver端,所以在使用这两个方法时需要注意数据量,以免Driver发生OutOfMemoryError。
使用实例:
// first
Row first = studentDataset.first();
// head
Row head = studentDataset.head();
// head(2)
Row[] heads = studentDataset.head(2);
// take(2)
Row[] take = studentDataset.take(2);
// takeAsList(2)
List<Row> rows = studentDataset.takeAsList(2);
可以这么写,但是不能运行,在java中没有Row[]这种Array,可以使用List<Row>

2. Dataset(DataFrame)的transformations操作(转化)
Dataset提供用以形成SQL表达的转化操作,如select()、where()、orderBy()、groupBy()、join()等方法。以下方法皆为返回DataFrame对象的方法,所以可以连续调用。
2.1 where 条件相关
where方法根据参数类型及数目不同进行了同名函数重载,可以看到第2个where(String conditionExpr)输入更像一种传统SQL的where子句的条件整体描述,而where(Column condition),该方法的输入则是要把where子句的对于每一个column的要求进行分别描述,且该种表述等效于filter()实现的筛选,但从最终效果上来讲,这两种方法并没有什么不同,只是解析语句时,第2种方法,需要对整个where子句进行解析,从而得到对于每一个column的要求。

(1)where (String conditionExpr):sql语言中where关键字后的条件;where(Column condition):字段的条件描述(主要使用Column的API)
传入筛选条件表达式,可以用and 和 or ,得到Dataset类型的返回结果。
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
// 读取文件转成JavaRDD
Dataset<Row> studentDataset = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student2.json");
// where(String conditionExpr)
Dataset<Row> wheredataset = studentDataset.where("age > 13 and sex = '男'");
wheredataset.show();
// where(Column condition)
Dataset<Row> whereDataset2 = studentDataset.where(studentDataset.col("age").gt(13).and(studentDataset.col("sex").equalTo("男")));
whereDataset2.show();
// 关闭saprkSesison 这里的close和stop是一个样 2.1.X开始用close 2.0.X使用的stop
sparkSession.close();
}
日志:

结果是一样的。
(2)filter:根据字段进行筛选
filter()同样具有和where类似的两个同名重载函数filter(String conditionExpr)、filter(Column condition),其间区分差不多where()情况相同,即其两者效果等效,仅为了满足程序员的不同开发习惯。

这里面还多了两个参数为过滤函数的方法,这个和RDD的filter是一样的,过滤函数返回true则保留,false舍去数据。
使用实例:
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
// 读取文件转成JavaRDD
Dataset<Row> studentDataset = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student2.json");
// filter(String conditionExpr)
studentDataset.filter("age > 13 and sex = '男'").show();
// filter(Column condition)
studentDataset.filter(studentDataset.col("age").gt(13).and(studentDataset.col("sex").equalTo("男"))).show();
// filter(new FilterFunction<Row>(){...})
studentDataset.filter(new FilterFunction<Row>() {
@Override
public boolean call(Row value) throws Exception {
return (long)value.getAs("age") > 13 && value.getAs("sex").equals("男");
}
}).show();
// 关闭saprkSesison 这里的close和stop是一个样 2.1.X开始用close 2.0.X使用的stop
sparkSession.close();
}
日志:

结果也是一样的。
2.2 查询指定列
- select:获取指定字段值

根据传入的String类型参数和Column类型参数可以适应于多种情况
使用实例:
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local").appName("SparkSQLDemo1").config("spark.testing.memory", 471859200).getOrCreate();
// 读取文件转成JavaRDD
Dataset<Row> studentDataset = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student2.json");
// select(String col, String... cols)
studentDataset.select("name","age","sex").show(2);
// select(String col, scala.collection.Seq<String> cols)
ArrayStack<String> arraySeq = new ArrayStack<>();
arraySeq.push("sex");
arraySeq.push("age");
studentDataset.select("name",arraySeq).show(2);
// select(Column... cols) colum可以对字段做一些处理,例如给年龄+5 并取别名age+5
studentDataset.select(studentDataset.apply("name"),studentDataset.col("age").plus(5).as("age+5"),studentDataset.col("sex")).show(2);
// select(scala.collection.Seq<Column> cols)
ArrayStack<Column> arraySeqClumn = new ArrayStack<>();
arraySeqClumn.push(studentDataset.col("sex"));
arraySeqClumn.push(studentDataset.col("age"));
arraySeqClumn.push(studentDataset.col("name"));
studentDataset.select(arraySeqClumn).show(2);
// 关闭saprkSesison 这里的close和stop是一个样 2.1.X开始用close 2.0.X使用的stop
sparkSession.close();
}
日志:

-
selectExp:可以对指定字段进行特殊处理

两种方式供开发调用,看个人习惯。
studentDataset.selectExpr("name","age","age+1 as otherAge","round(age)","sex as性别").show(2);age全部加1了
-
col和apply :获取字段或者某一列
这两个方法的参数类型,个数以及返回值类型均相同,返回的都是Column类型
-
drop:去除指定字段,保留其他字段
drop的重载方法也与很多,但是都大同小异只是参数的不同方式的体现,喜欢哪一个就用那一个吧。




使用实例:
studentDataset.drop("age").show(2);
日志截图:

没有了age列
2.3 Column的应用
Column有很多方法,各种各样的方法,也是操作查询等必要会的,未完待续!!!
2.4 limit操作
limit方法获取指定Dataset的前n行记录,得到一个新的Dataset对象。

和take与head不同的是,limit方法不是Action操作,因为take,head均获得的均为Array(数组),而limit返回的是一个新的转化生成的Dataset对象
studentDataset.limit(10).show();
日志截图:

2.5 排序操作:order by 和 sort
order by 和 sort 都是按照指定字段排序,默认为升序。并且使用方法相同,支持多字段排序。


使用实例:
studentDataset.sort(studentDataset.col("age").desc(),studentDataset.apply("name").desc()).show(5);
studentDataset.orderBy(studentDataset.col("age").desc(),studentDataset.apply("name").desc()).show(5);
日志:

sort还有个sortWithinPartitions,这个和sort方法功能类似,区别在于sortWithinPartitions方法返回的是排好序的每一个分区的Dataset对象
2.6 group by 操作
groupBy的方法如下:

-
groupBy:根据字段进行分组操作
groupBy方法有四种调用方式,只是对参数类型和个数的不同应用。
使用实例:
// String类型 RelationalGroupedDataset age = studentDataset.groupBy("age","name"); // Column类型 RelationalGroupedDataset age1 = studentDataset.groupBy(studentDataset.apply("age"),studentDataset.apply("name")); -
RelationalGroupedDataset对象
groupBy()方法得到的是RelationalGroupedDataset类型的对象,在RelationalGroupedDataset的API中提供了groupBy之后的操作,比如:
- max(String…colNames)方法,获取分组中指定字段或者所有的数字类型字段的最大值,只能作用于数字类型字段。
- min(String…colNames)方法,获取分组中指定字段或者所有的数字类型的最小值,只能作用于数字类型字段。
- mean(String…colNames)方法,获取分组中指定字段或者所有的数字类型的平均值,只能作用于数字类型字段。
- sum(String…colNames)方法,获取分组中指定字段或者所有的数字类型的和值,只能作用于数字类型字段。
- count()方法,获取分组中元素的个数
使用实例:
// 按照年龄分组 显示不同年龄组内的个数 studentDataset.groupBy("age").count().show(); // 按照班级分组,找到班级内最大的年龄 studentDataset.groupBy("institute").max("age").show(); // 按照班级分组,找到班级内的平均年龄 studentDataset.groupBy("institute").mean("age").show();日志截图:

2.7 distinct,dropDuplicates 去重操作
distinct:

dropDuplicates:

distinct()返回一个包含重复记录的Dataset,和不带参数的dropDuplicates()方法不传入指定字段时的结果相同。而带有参数的dropDuplicates(...)是可以指定字段(可以多个字段组合)去重。
使用实例:
// 对查询的班级和性别结果去重 distinct
studentDataset.select("institute","sex").distinct().show();
// 对查询的班级和性别结果去重 dropuicates
studentDataset.select("institute","sex").dropDuplicates().show();
// 对查询的班级和性别结果指定字段去重 dropuicates
studentDataset.select("sex").dropDuplicates(new String[]{"sex"}).show();
日志:

2.8 聚合操作
聚合操作是指agg方法:

聚合操作调用的是agg方法,该方法输入的是对于聚合操作的表达(aggExpr),可同时对多个列进行聚合操作(aggExprs),一般与groupBy方法配合使用。
小提示:在Scala中可以直接使用max("XX")等对字段做操作,但是在Java中同样可以这样操作,只不过需要借助工具类functions,这样就可以实现了。
使用实例:
studentDataset.agg(functions.max(studentDataset.apply("age")),functions.mean(studentDataset.apply("age"))).show();
日志截图:

用这种方式就可以实现对一个字段的多种操作,如果使用Map的形式,只能对一个字段操作一次。
2.9 union 合并操作
union方法对两个字段一致的Dataset进行合并,返回是组合生成的新的Dataset。类似于Sql的UNION操作。

在源码中,union和unionAll是相同的,没有区分。这里还有个unionByName这个方法,其实我们主要用的是这个,因为union在合并的时候只按照列合并,不会考虑两个表的列是否相对应,而unionByName会根据列名一一对应的合并。
注意,unionByName是2.3.0才开始加入的,我是2.1.1 所以没有实例了。给个截图吧。

使用实例:
studentDataset.select("name","age","institute").limit(3).union(studentDataset.select("name","institute","age").limit(3)).show();
日志截图:

2.10 join操作!!!重点
重点来了。在SQL语言中用得很多的就是join操作,DataFrame中同样也提供了join的功能。
接下来隆重介绍join方法。在DataFrame中提供了以下六个重载的join方法:

这里我们添加一个addr.json文件:
{"name":"王明","addr":"阳光小区7号"}
{"name":"李红","addr":"阳光小区2号"}
{"name":"刘强","addr":"阳光小区1号"}
{"name":"张三","addr":"阳光小区5号"}
{"name":"李四","addr":"阳光小区4号"}
{"name":"王五","addr":"阳光小区3号"}
{"name":"刘旺","addr":"阳光小区2号"}
{"name":"赵笋","addr":"阳光小区1号"}
{"name":"刘晓红","addr":"阳光小区2号"}
6个join()函数,发现其主要区别在于输入参数的个数与类型不同。其中1,2,4,6 join()方法皆为内连接(inner join),因为这4个join()方法并没有调节join类型的joinType的参数输入,因此是默认的内连接,而3,5方法皆有String joinType该参数,因此可从inner、cross、outer、ull、full_outer、left、left_outer、right、right_outer、left_semi,left_anti选择任何一种连接类型进行join操作。
-
观察
4,6 join()函数,这两者主要区别在于输入参数分别为scala.collection.Seq<String> usingColumns和String usingColumn,前者是表示多个字段的String的Seq(序列),后者是表示单个字段的String类型,即当我们在两个Dataset对象进行连接操作时,不仅可以基于一个字段,也可以用多个字段进行匹配连接。使用实例:
// 读取地址数据 Dataset<Row> addrDataset = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\addr.json"); // join(Dataset<?> right, String usingColumn) studentDataset.join(addrDataset,"name").show(); // join(Dataset<?> right, scala.collection.Seq<String> usingColumns) ArrayStack<String> arrayStack = new ArrayStack<>(); arrayStack.push("name"); studentDataset.join(addrDataset,arrayStack).show();日志截图:
都是内连接(inner join)
-
观察
2,3 join方法,可看到出这二个输入参数不再是象征着字段的scala.collection.Seq<String> usingColumns和String usingColumn,而是Column joinExprs这种表示两个参与join运算的连接字段的表述(expression)。使用实例:
// join(Dataset<?> right, Column joinExprs) Column joinExprs = studentDataset.apply("name").equalTo(addrDataset.apply("name")); studentDataset.join(addrDataset,joinExprs).show();日志截图:
这里可以看到,如果使用String类型的参数,关键字段只出现一次,使用Column类型,使用到的关键字是不会有任何处理的,都会显示出来。
-
观察
3,5join方法,可以看到他们的参数都有一个String joinType字符串,这个就是需要指定的连接方式:Type of join to perform. Default `inner`. Must be one of: `inner`, `cross`, `outer`, `full`, `full_outer`, `left`, `left_outer`, `right`, `right_outer`, `left_semi`, `left_anti`.默认是
inner内连接使用实例:
Column joinExprs = studentDataset.apply("name").equalTo(addrDataset.apply("name")); studentDataset.join(addrDataset,joinExprs,"left").show();日志截图:



2.11 获取指定字段的统计信息
暂无
2.12 获取两个Dataset中共有的记录
获取两个Dataset中共有的记录方法:

intersect方法可以计算出两个Dataset中相同的记录,返回值也为Dataset
使用实例:
studentDataset.intersect(studentDataset.limit(3)).show();
日志截图:

2.13 获取一个Dataset中有另外一个Dataset中没有的记录
获取一个Dataset中有另一个Dataset中没有的记录,方法如下:

使用实例:
studentDataset.except(studentDataset.limit(15)).show();
日志截图:

去除了15个记录
2.14 操作字段名
withColumn可以在当前Dataset中新增一列,该列可来源于本身Dataset对象,不可来自其他非自己的Dataset对象
withColumnRenamed可以重命名dataset指定的字段名,如果指定的字段名不存在,不作任何操作。

使用实例:
// 添加一列age+2 年龄加2 修改name字段名为myname
studentDataset.withColumn("age+2",studentDataset.col("age").plus(2)).withColumnRenamed("name","Myname").show(5);
日志截图:

2.15 处理空值列
使用带有空值的数据:
{"name":"张三","age":12,"sex":"男","institute":"计算机3班","phone":"4"}
{"name":"李四","age":12,"sex":null,"institute":"计算机2班","phone":"5"}
{"name":"王五","age":null,"sex":"男","institute":"计算机3班","phone":null}
{"name":null,"age":null,"sex":null,"institute":null,"phone":null}
{"name":"赵笋","age":18,"sex":"女","institute":"计算机2班","phone":"8"}
{"name":"刘晓红","age":20,"sex":"女","institute":"计算机1班","phone":"9"}
{"name":"王志利","age":15,"sex":"男","institute":"计算机2班","phone":null}
使用na方法对具有空值列的行数据进行处理,例如删除缺失某一列值的行或用指定值(缺失值)替换空值列的值,方法如下:

需要注意的是,在Dataset对象上使用na方法后返回的是对应的DataFrameNaFunctions对象,进而调用对应的drop,fill方法来处理指定列为空值的行。
-
drop:删除指定列为空值的行
无参数的drop(),只要行数据有空值列(一个或者多个空值列)就进行删除,而其他重载方法,可通过将指定列的列名组成的数组传入drop方法。
在注释中有这样一句话:
If `how` is "any", then drop rows containing any null or NaN values in the specified columns.* If `how` is "all", then drop rows only if every specified column is null or NaN for that row.也就是
String how参数的用处,在没有这个参数的方法中默认用的是any,指定了all则必须指定的字段列都为空才会删除这条记录。使用实例:
Dataset<Row> studentDataset3 = sparkSession.read().json("D:\\sparksqlfile\\jsondata\\student3.json"); studentDataset3.show(); DataFrameNaFunctions na = studentDataset3.na(); // 只要有空值就删除 等同于 na.drop("any").show(); na.drop().show(); // 只有行数据全部都为空 才会删除 na.drop("all").show(); // age和phone有一个为空就删除 等同于na.drop("any",new String[]{"age","phone"}).show(); na.drop(new String[]{"age","phone"}).show(); // age和phone都为空才删除 na.drop("all",new String[]{"age","phone"}).show();日志截图:
-
fill:使用指定的值替换指定空值列的值
fill太难了。。。11个方法。。。但是都是大同小异只是不同类型,这里就挑几个说说吧
通过传入指定空值列列名以及该空值列替换值传入fill方法来替换指定空值列的值。
使用实例:
// 对于不同的字段类型会有默认的,只有设置好对应的默认值才会修改为模默认值 na.fill("我是空值").show(); // int的空值会被替换为1234 na.fill(1234).show(); // name和phone的空值会被替换为 空值 如果想替换其他类型 需要找其他类型的方法 na.fill("空值", new String[]{"name","phone"}).show(); // 在map中指定空列的替换值 类型要对应好 int类型就要给个int的默认值 HashMap<String,Object> map = new HashMap<>(); map.put("age",123); map.put("name","我是姓名"); na.fill(map).show();




- 点赞
- 收藏
- 关注作者
评论(0)