一文详解实时计算一致性:Flink VS Spark

近期,在网上看到一个来自外文网站的帖子,内容是一位业内大牛讨论#在分布式系统中最难解决的几个技术难题#。该话题目前已收到超过10000+的点赞认同数。

文中提出的排行第二的难题:Exactly-Once delivery。在很多评论中,甚至被认为是理论上几乎不可解决的问题。
对于此技术话题的理解,可谓见仁见智,而在流处理领域中的Exactly-Once一致性语义则是大数据开发者必须掌握的核心知识点。
由此引出日常工作常用的计算框架思考:
海量数据实时计算:Spark和Flink引擎是如何保证Exactly-Once一致性?
话不多说,我将从如下几点内容对此问题进行阐释:
-
什么是Exactly-Once一致性语义 -
Apache Spark的Exactly-once机制 -
Apache Flink的Exactly-once机制
1 Exactly-Once一致性语义
数据流转到某分布式系统中,如果系统在整个处理过程中所有数据都仅精确处理一次,且处理结果正确,则被认为该系统满足Exactly-Once一致性。
以上仅是我个人对Exactly-once一致性语义的解释,相较于官方定义,显得更加 通俗点,主要方便大家的理解。
分布式系统天生具有跨网络、多节点、高并发等特性,难免会出现节点异常、线程死亡、网络传输失败等非可控情况,从而导致数据丢失、重复发送等异常接踵而至。如何保持系统高效运行且数据仅被精确处理一次是很大的挑战。
分布式系统Exactly-Once的一致性保障,不是依靠某个环节的强一致性,而是要求系统的全流程均保持Exactly-Once一致性!!
2 Apache Spark的Exactly-Once机制
Apache Spark是一个高性能、内存级的分布式计算框架,在大数据领域中被广泛应用于离线分析、实时计算、数据挖掘等场景,因其采用独特的RDD数据模型及内存式计算,是海量数据分析和计算的利器之一。
实时场景下,Spark在整个流式处理中如何保证Exactly-Once一致性是重中之重。这需要整个系统的各环节均保持强一致性,包括可靠的数据源端(数据可重复读取、不丢失) 、可靠的消费端(Spark内部精确一次消费)、可靠的输出端(幂等性、事务)。
2.1 数据源端
支持可靠的数据源接入(例如Kafka), 源数据可重读
1. Spark Streaming内置的Kafka Direct API (KafkaUtils.createDirectStream)。实现精确Exactly-Once一致性语义。
-
Spark Streaming 自己管理offset(手动提交offset),并保持到checkpoint中 -
Kafka partition和Spark RDD一一对应,可并行读取数据 - Executor 根据offset range消费数据并本地存储, 保障数据不丢失。
Spark Streaming此时直接调用Kafka Consumer的API,自己管理维护offset(包括同步提交offset、保存checkpoint),所以即使在重启情况下数据也不会重复。
val ssc = new StreamingContext(sc, Seconds(5))
val kafkaStream = Map[String, String](
"bootstrap.servers" -> "s1:9092,m2:9092,m3:9092",
"group.id" -> "spark",
"auto.offset.reset" -> "smallest"
)
// 直连方式,手动更新offsets
val lines = KafkaUtils.createDirectStream[
String, String,StringDecoder,StringDecoder
] (ssc, kafkaStream)
Driver进程保持与Kafka通信,定期获取最新offset range范围,Executor进程根据offset range拉取kafka消息。因为Kafka本身offset就具有唯一特性,且Spark Streaming此时作为唯一的消费者,故全过程保持Exactly-once的一致性状态。
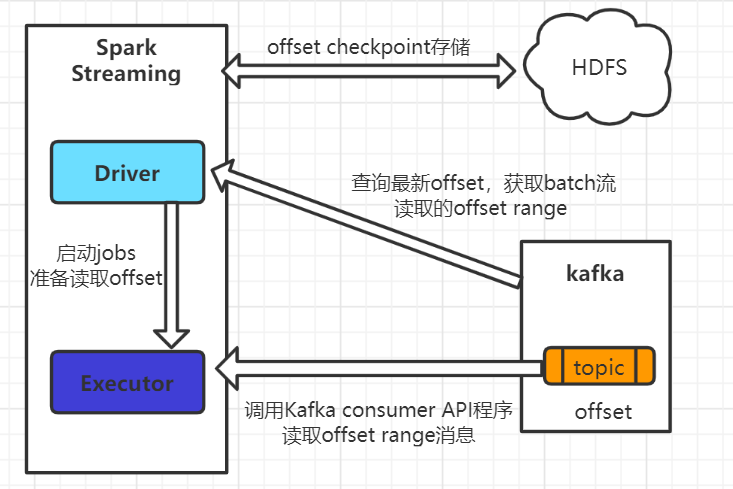
注意: 如果程序崩溃,整个流可能会从earliest、latest处恢复重读,需考虑其他后续处理
2. Spark Streaming 基于Receiver的Kafka高级API,实现At least Once语义
-
基于Spark Streaming的Receiver模式,在Executor持续拉取kafka数据流 -
kafka数据存储到Executor内存和WAL(预写日志)中 -
WAL(预先日志)写入完成后,自动更新offset至zookeeper上
利用Spark本身的Receivers线程接收数据,内部调用Kafka高级消费API,不断触发batch消息拉取。获取的kafka数据在Executor本地存储,也可以启用WAL预写文件,将数据存储到第三方介质(HDFS)中。
val ssc = new StreamingContext(sc, Seconds(5))
ssc.checkpoint("ck")
val topicMap = topics.split(".")
.map((_, numThreads.toInt))
.toMap
val lines = KafkaUtils
.createStream(ssc, zk, group, topicMap)
.map(_._2)
此过程仅可实现At least once(至少一次),也就是说数据可能会被重复读取。即使理论上WAL机制可确保数据不丢失, 但是会存在消息写入WAL完成,但因其他原因无法及时更新offset至zookeeper的情况。此时kafka会重新发送offset,造成数据在Executor中多存储一份。

3. 总结
-
高级消费者API需要启用 Receiver线程消费Kafka数据,相较于第一种增加了开销,且无法直接实现并行读取,需要使用多个Kafka Dtstream 消费同一组然后union。 -
高级消费API在Executor本地和WAL存储两份数据<开启WAL不丢失机制>,而第一种Direct API仅在Executor中存储数据<offset存储到checkpoint中> -
基于 Kafka Direct API的方式,因Spark集成Kafka API直接管理offset,同时依托于Kafka自身特性,实现了Exactly-Once一致性语义。因此在生产中建议使用此种方式!!
2.2 Spark消费端
Spark的基本数据单元是一种被称作是RDD(分布式弹性数据集)的数据结构,Spark内部程序通过对RDD的进行一系列的transform和action操作,完成数据的分析处理。
基于RDD内存模型,启用多种一致性策略,实现Exactly-Once一致性。
1. RDD特性
-
Spark的RDD是 分布式、容错、不可变的数据集。其本身是只读的,不存储真实的数据,当结构更新或者丢失时可对RDD进行重建,RDD不会发生变化。

-
每个RDD都会有自己的 Dependency RDD,即RDD的血脉机制。在开启 Checkpoint机制下,可以将RDD依赖保存到HDFS中。当RDD丢失或者程序出现问题,可以快速从血缘关系中恢复。因为记录了RDD的所有依赖过程,通过血脉追溯可重构计算过程且保证多次计算结果相同。
2. Checkpoint持久化机制 + WAL机制
-
Spark的 Checkpoint机制会在当前job执行完成后,再重新启动一个job,将程序中需要Checkpoint的RDD标记为MarkedForCheckpoint RDD, 且重新执行一遍RDD前面的依赖,完成后将结果保存到checkpoint中,并删除原先Dependency RDD依赖的血缘关系。利用Checkpoint的特性和高可用存储,保证RDD数据结果不丢失。

-
启用 WAL预写文件机制。如果存在Driver或者Executor异常挂掉的场景,RDD结果或者jobs信息就会丢失,因此很有必要将此类信息持久化到WAL预写日志中,通过对元数据和中间数据存储备份,WAL机制可以防止数据丢失且提供数据恢复功能。
3. 程序代码去重
如果实时流进入到Spark消费端已经存在重复数据,可以编写Spark程序代码进行去重操作,实现Exactly-Once一致性。
-
内存去重。采用 Hashset等数据结构,读取数据中类似主键等唯一性标识字段,在内存中存储并进行去重判断。 -
使用 Redis Key去重。借助Redis的Hset等特殊数据类型,自动完成Key去重。 -
DataFrame/SQL场景,使用 group by、over()、window开窗等SQL函数去重 -
利用groupByKey等聚合算子去重 -
其他方法。。
2.3 输出端
输出端保持Exactly-Once一致性,其输出源需要满足一定条件:
支持幂等写入、事务写入机制
1. 幂等写入
首先解释一下幂等性,先看下百度百科上的定义:
“ 幂等是一个数学与计算机学概念,常见于抽象代数中。在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。”
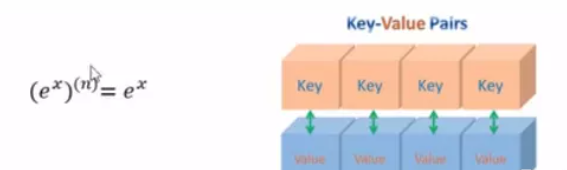
结合语义可知,幂等写入就是多次写入会产生相同的结果,结果具有不可变性。在Spark中saveAsTextFile算子就是一种比较典型的幂等写入,也经常被用来作为数据的输出源。
此类型的写入方式,如果在消息中包含唯一主键,那么即使源头存在多条重复数据,在主键约束条件下也不会重复写入,从而实现Exactly-Once语义。
2. 事务写入
相信大家对事务的概念都不陌生,在一个处理过程中的所有操作均需要满足一致性,即要不都发生,要不都不发生,常见于业务性、安全性要求比较高的场景,例如银行卡账户金额存取行为等,具有原子性、一致性、隔离性、持久性等四大特征。
Spark读取Kafka数据需满足输出端的事务写入,则一般需生成一个 唯一ID(可由批次号、时间、分区、offset等组合),之后将该ID结合计算结果在同一个事务中写入目标源,提交和写入操作保持原子性,实现输出端的Exactly-Once语义。
更多细节讨论,欢迎添加我的个人微信: youlong525
3 Apache Flink的Exactly-Once机制
Apache Flink是目前市场最受关注的流计算处理引擎,相较于Spark Streaming的依托Spark Core实现的微批处理模型,Flink是一个纯粹的流处理引擎,其基于操作符的连续流模型,可以达到微秒级别的延迟。
Flink实现了流批一体化模式,实现按照事件处理和无序处理两种形式,基于内存计算。强大高效的反压机制和内存管理,基于轻量级分布式快照checkpoint机制,从而自动实现了Exactly-Once一致性语义。
3.1 数据源端
支持
可靠的数据源(如kafka), 数据可重读
Apache Flink内置FlinkKafkaConsumer010类,不依赖于 kafka 内置的消费组offset管理,在内部自行记录和维护 consumer 的offset。
-
Flink 自己管理offset(手动提交offset),并保持到checkpoint中 -
API内部集成了Flink Checkpoint 机制, 自动实现了精确一次的处理语义 (类似于Spark的offset位移管理,但实现机制不同)
源码过程解读:
-
经过一系列初始化操作和方法调用,到达initializedState()。 -
这里 stateBackend中把offset state恢复到restoredState,然后从fetcher拉取最新的offset数据,将offset存入到stateBackend中 -
在经过后续一系列操作,更新相应的checkpoint。

3.2 Flink消费端
轻量级快照机制: 一致性checkpoint检查点
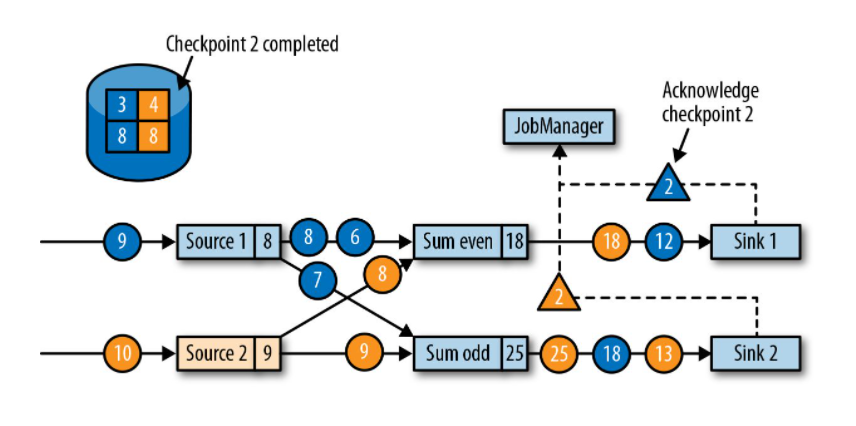
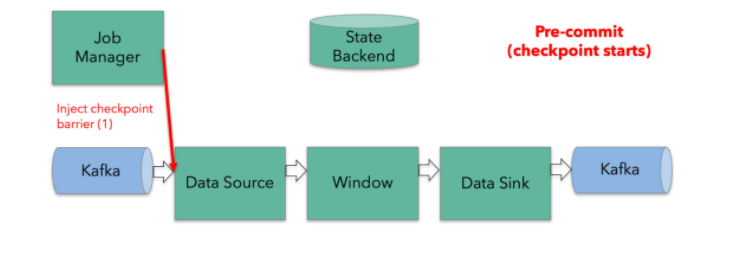
Flink采用了一种轻量级快照机制(检查点checkpoint)来保障Exactly-Once的一致性语义。所谓的一致检查点,即在某个时间点上所有任务状态的一份拷贝(快照)。该时间点是所有任务刚好处理完一个相同数据的时间。
1. 一致性检查点
间隔时间自动执行分布式一致性检查点(Checkpoints)程序,异步插入barrier检查点分界线,内存状态自动存储为cp进程文件。保证数据Exactly Oncey精确一次处理。

-
从source(Input)端开始, JobManager会向每个source(Input)发送检查点barrier消息,启动检查点。在保证所有的source(Input)数据都处理完成后,Flink开始保存具体的一致性检查点checkpoints,并在过程中启用barrier检查点分界线。 -
接收数据和 barrier消息,两个过程异步进行。在所有的source(Input)数据都处理完成后,开始将自己的检查点checkpoints保存到状态后端StateBackend中,并通知JobManager将Barrier分发到下游 -
barrier向下游传递时,会进行 barrier对齐确认。待barrier都到齐后才进行checkpoints检查点保存。 -
重复以上操作,直到整个流程完成。
3.3 输出端
与上文Spark的输出端Exactly-Once一致性上实现类似,除了目标源需要满足一定条件以外,Flink内置的二阶段提交机制也变相实现了事务一致性。支持幂等写入、事务写入机制(二阶段提交)
1. 幂等写入
这一块和上文Spark的幂写入特性内容一致,即相同Key/ID 更新写入,数据不变。借助支持主键唯一性约束的存储系统,实现幂等性写入数据,此处将不再继续赘述。
2. 事务写入: 二阶段提交 + WAL预写日志
Flink在处理完source端数据接收和operator算子计算过程,待过程中所有的checkpoint都完成后,准备发送数据到sink端,此时启动事务。其中存在两种方式:
-
WAL预写日志: 将计算结果先写入到日志缓存(状态后端/WAL)中,等checkpoint确认完成后一次性写入到sink。 -
二阶段提交: 对于每个checkpoint创建事务,先预提交数据到sink中,然后等所有的checkpoint全部完成后再真正提交请求到sink, 并把状态改为已确认。
整体思想: 为checkpoint创建事务,等到所有的checkpoint全部真正的完成后,才把计算结果写入到sink中。
4 写在最后
Exacty-Once一致性语义是分布式系统中最常见的一个话题,也是面试中最常被问到的一个知识难点,其中涉及到的技术点和设计思想值得我们投入更多时间去深入探究。
我从Spark、Flink这两个目前市场上最流行的计算引擎入手,结合实时场景粗浅的介绍了Exactly-Once一致性在这两个分布式系统中的技术实现。
因为篇幅有限和侧重点不同,Spark和Flink中的一些知识点并没有展开叙述,如果大家喜欢,后期我会单独对Spark和Flink的知识进行归纳,并输出相关文章。
》》》更多好文,请大家关注我的公众号: 大数据兵工厂

- 点赞
- 收藏
- 关注作者
评论(0)