数据分析实战 | A/B测试探寻哪种广告点击率更高?

大家好,我是丁小杰。
本篇是《数据分析实战》系列第三篇,案例来源为《数据分析实战》一书,书中使用的是 R 语言,接下来一段时间,我会用 Python + Tableau/Pyecharts 尽可能的将案例复现出来,以供大家学习。
场景描述
某个促销活动每个月都会开展一次,但和公司其他类似的促销活动相比,该促销活动的用户购买率比较低。通过调查用户购买率低的原因,发现问题可能出在促销广告上。
于是我们准备了两个不同的广告,来验证哪种广告能够带来更高的用户购买率。
A/B测试
A/B 测试能够在多个选项中找出那个能够带来最佳结果的选项。在本例中,我们只要同时投放广告 A 和广告 B,就可以排除其他外部因素的干扰,但要注意用户分组必须遵循随机原则。

在测试过程中,我们收集到了两组广告的曝光数据和点击数据,接下来就可以开始数据分析!
数据描述
ab_test_imp
广告曝光次数信息,87924 行。
| 字段 | 类型 | 含义 |
|---|---|---|
| log_date | str | 广告曝光日期 |
| app_name | str | 应用名 |
| test_name | str | 测试名 |
| test_case | str | 测试用例(A/B) |
| user_id | numpy.int64 | 用户 ID |
| transaction_id | numpy.int64 | 事务 ID |
ab_test_goal
广告点击次数信息,8598 行。
| 字段 | 类型 | 含义 |
|---|---|---|
| log_date.g | str | 广告点击日期 |
| app_name | str | 应用名 |
| test_name.g | str | 测试名 |
| test_case.g | str | 测试用例(A/B) |
| user_id.g | numpy.int64 | 用户 ID |
| transaction_id | numpy.int64 | 事务 ID |
数据分析
数据读取
读取两个数据集。
import pandas as pd
imp_df = pd.read_csv('ab_test_imp.csv')
goal_df = pd.read_csv('ab_test_goal.csv')
修改两个数据集的列名。
imp_df.columns = ['广告曝光日期', '应用名', '测试名', '测试用例(A/B)', '用户ID', '事务ID']
goal_df.columns = ['广告点击日期', '应用名', '测试名', '测试用例(A/B)', '用户ID', '事务ID']
显示 ab_test_imp 数据集后五行。
imp_df.tail()

显示 ab_test_goal 数据集后五行。
goal_df.tail()

以曝光数据作为主数据集,连接两个数据集。
all_df = imp_df.merge(goal_df, how='left', on='事务ID', suffixes=('', '_goal'))
all_df.tail()

增加标记列,判断用户是否点击
all_df['是否点击'] = all_df['用户ID_goal'].apply(lambda x:0 if pd.isnull(x) else 1)
提取分析所需的列数据。
all_df = all_df.loc[:, ['广告曝光日期', '测试用例(A/B)', '用户ID', '事务ID', '是否点击']]
all_df.tail()

A/B点击率
数据处理好后,接下来统计一下 A/B 两个广告的点击率。
pivot = all_df.pivot_table(index='测试用例(A/B)',
columns=None,
values='是否点击',
aggfunc=(lambda x: sum(x)/len(x))).reset_index()
pivot
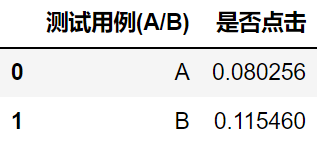
A 的点击率为 是 8% 左右,而 B 的点击率 11.5%。
卡方检验
在讨论二者的差异时,一般采用卡方检验,我们先获取 A/B 广告的点击次数。
import numpy as np
pivot = all_df.pivot_table(index='测试用例(A/B)',
columns='是否点击',
values='用户ID',
aggfunc=np.count_nonzero)
pivot

chi2_contingency 用于列联表中变量独立性的卡方检验。
chi2_contingency(observed, correction=True, lambda_=None)
参数
observed:列联表,本例中为二维数组。correction:如果为True,并且自由度为1,则应用Yates校正以保持连续性。校正的效果是将每个观察值向相应的期望值调整0.5lambda_:float或str,可选。默认情况下,此测试中计算的统计量是Pearson的卡方统计量。 lambda_允许使用Cressie-Read功率散度族的统计量来代替。
返回值
-
chi2:float,卡方值 -
p:float,p值 -
dof:int,自由程度 -
expected:ndarray,预期频率,基于表的边际总和
from scipy.stats import chi2_contingency
kf = chi2_contingency(np.array(pivot))
kf

根据上面结果,p值为 $ 4.04×10^{-69} $ ,
是一个非常小的数值。p 值越接近于 0 差异性越大。通常来说,当 p 值 小于 0.05 时,称为“存在显著性差异”。因此我们可以说:在将两种广告分为 A/B 并 同时投放后,所得到的点击率存在显著性差异。
A/B广告点击时间序列
计算两个广告每日的点击率。
res = all_df.pivot_table(index='广告曝光日期',
columns='测试用例(A/B)',
values='是否点击',
aggfunc=(lambda x: sum(x)/len(x))).reset_index()
res.head()

绘制A/B广告点击率时间序列折线图。
from pyecharts.charts import *
import pyecharts.options as opts
from pyecharts.globals import ThemeType
line_style = {
'normal': {
'width': 4,
'shadowColor': 'rgba(155, 18, 184, .3)',
'shadowBlur': 10,
'shadowOffsetY': 10,
'shadowOffsetX': 10,
'curve': 0.5
}
}
line = (Line(init_opts=opts.InitOpts(theme='ThemeType.CHALK', width='900px')))
line.add_xaxis(res['广告曝光日期'].tolist())
line.add_yaxis('A 广告',
res['A'].tolist(),
yaxis_index=0,
is_smooth=True,
is_symbol_show=False,
linestyle_opts=line_style
)
line.add_yaxis('B 广告',
res['B'].tolist(),
is_smooth=True,
is_symbol_show=False,
linestyle_opts=line_style
)
line.set_series_opts(
label_opts=opts.LabelOpts(
is_show = False,
)
)
line.set_global_opts(
title_opts=opts.TitleOpts(
title = 'A / B 广告点击率时间序列变化折线图',
pos_left = 'center',
pos_top = '2%'
),
legend_opts=opts.LegendOpts(
pos_top = '12%',
legend_icon = 'circle'
),
xaxis_opts=opts.AxisOpts(
axislabel_opts={'rotate':90},
axisline_opts=opts.AxisLineOpts(
is_show=False
),
),
yaxis_opts=opts.AxisOpts(
name='点击率 %',
axisline_opts=opts.AxisLineOpts(
is_show=False
),
splitline_opts=opts.SplitLineOpts(
is_show=True
)
),
tooltip_opts=opts.TooltipOpts(
is_show = True,
trigger = 'axis',
trigger_on = 'mousemove|click',
axis_pointer_type = 'shadow'
)
)
line.render_notebook()

通过上图可知,广告 B 的点击率在大多数时候都优于广告A。所以,分析结果是,广告B比广告A更容易被用户点击。
这就是今天要分享的内容,记得点赞哦!
案例参考
[1]《数据分析实战》 [日] 酒卷隆志 里洋平/著 肖峰/译
对于刚入门 Python 或是想要入门 Python 的小伙伴,可以通过下方小卡片联系作者,一起交流学习,都是从新手走过来的,有时候一个简单的问题卡很久,但可能别人的一点拨就会恍然大悟,由衷的希望大家能够共同进步。另有整理的近千套简历模板,几百册电子书等你来领取哦!

- 点赞
- 收藏
- 关注作者
评论(0)