一日一技:在 Puppeteer 中如何拦截并修改网站的 JavaScript 代码


在我的爬虫书中,讲到了使用 Charles 或者 MitmProxy 实现中间人攻击,从而绕过反爬虫机制的方法。但这两种方法都需要安装根证书。
今天,我们来试一试在 Puppeteer 中,使用中间人攻击,攻击目标是我们自己,来绕过反爬虫机制。
首先,我们用以下代码访问网站http://exercise.kingname.info/exercise_ajax_1.html:
const puppeteer = require('puppeteer-core');
(async () => {
const browser = await puppeteer.launch({
executablePath: '/Applications/Microsoft Edge.app/Contents/MacOS/Microsoft Edge',
headless:false,
});
const [page] = await browser.pages()
await page.goto('http://exercise.kingname.info/exercise_ajax_1.html');
})();
运行效果如下图所示:
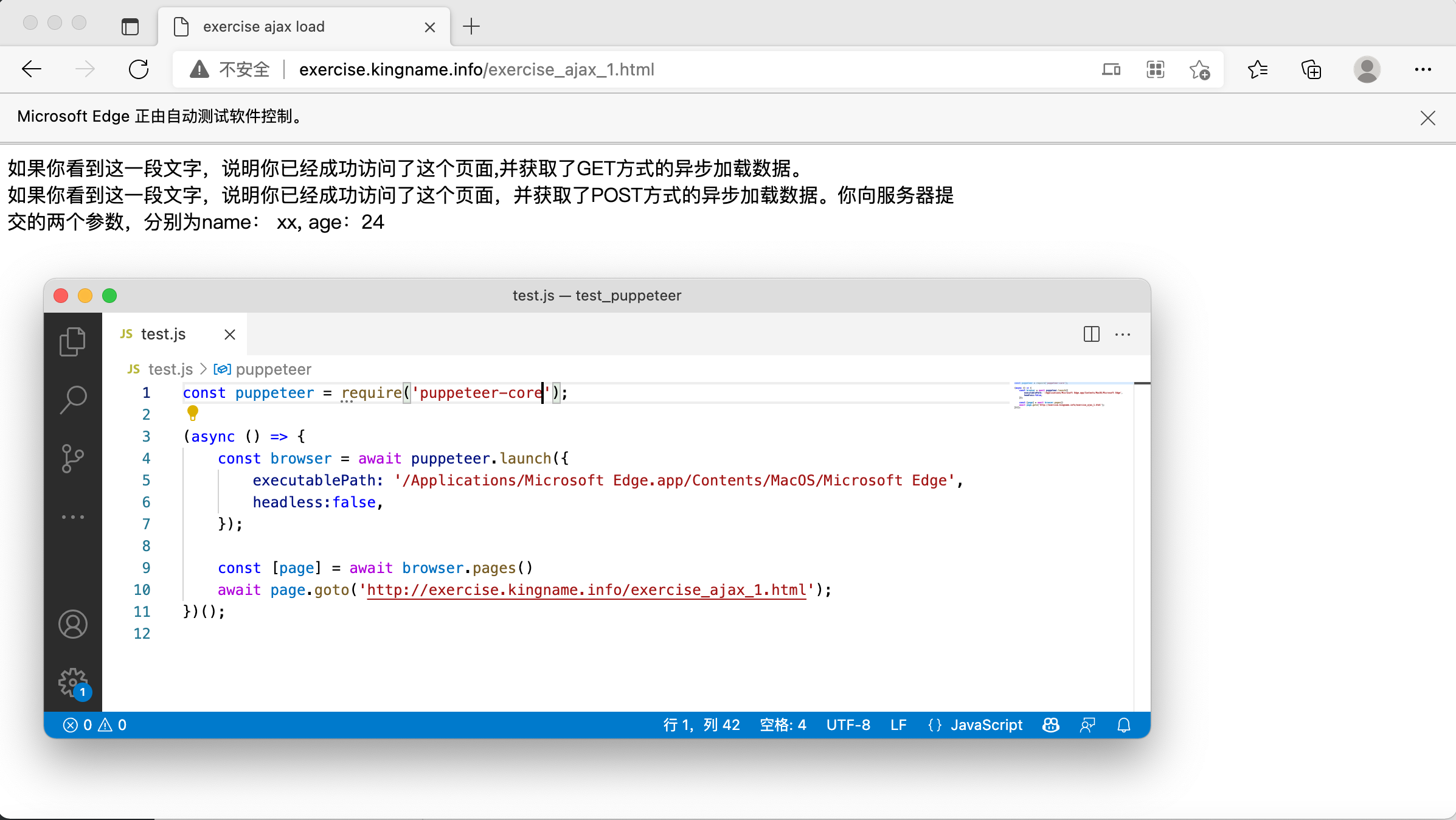
现在,我想拦截网站返回的数据,并篡改它。首先我们打开 Chrome 的开发者工具,看看这个页面有哪些 Ajax 请求:
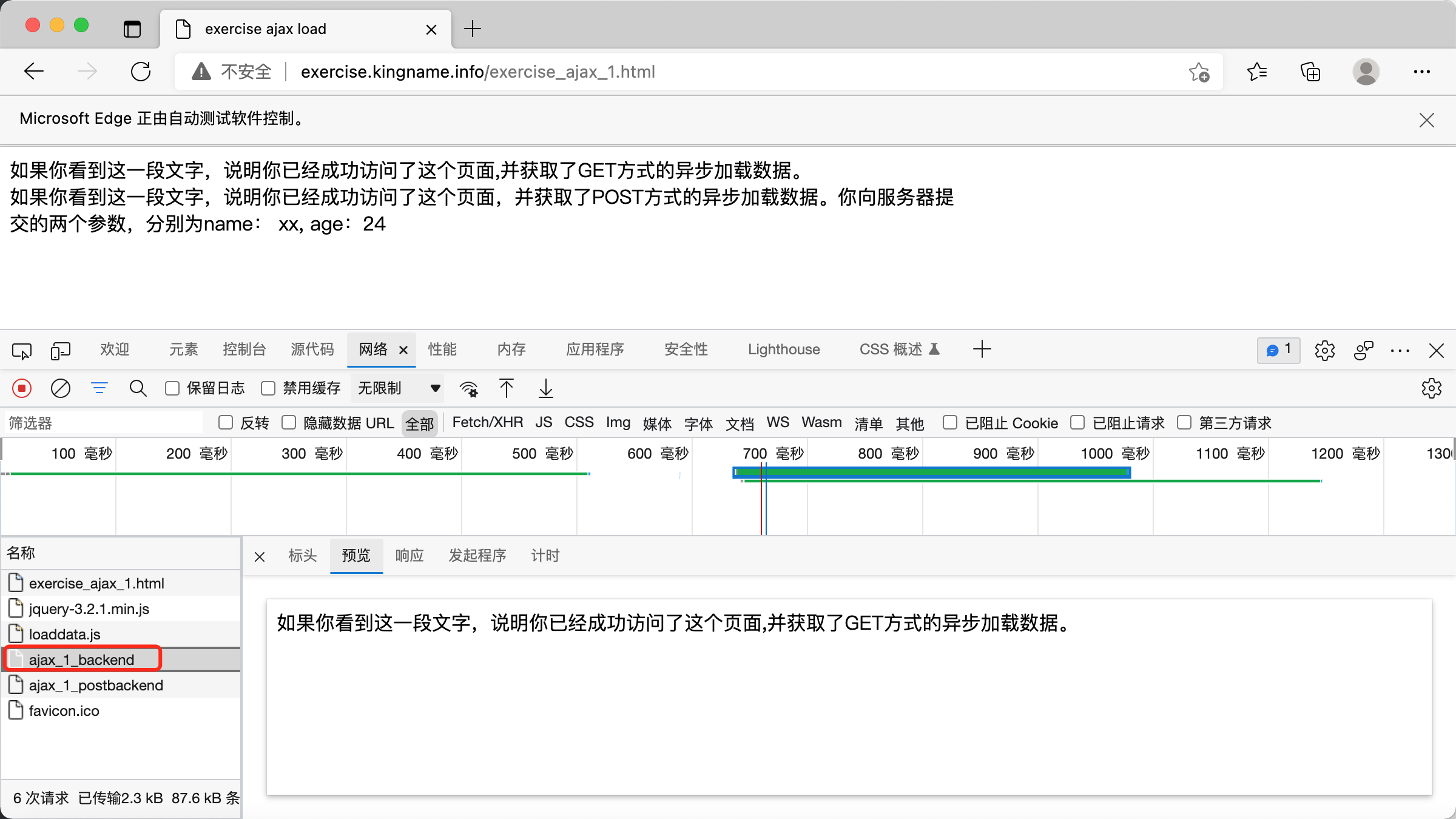
红框框住的这个 Ajax 请求,返回了网页上面的文字。这个请求对应的地址是:http://exercise.kingname.info/ajax_1_backend,如下图所示:

现在,我们就来尝试篡改这个请求的返回数据。首先使用npm安装一个包:npm install puppeteer-interceptor。然后修改代码:
const puppeteer = require('puppeteer-core');
const { intercept, patterns } = require('puppeteer-interceptor');
(async () => {
const browser = await puppeteer.launch({
executablePath: '/Applications/Microsoft Edge.app/Contents/MacOS/Microsoft Edge',
headless:false,
});
const [page] = await browser.pages();
intercept(page, patterns.XHR('*ajax_1_backend'), {
onResponseReceived: event => {
console.log(`${event.request.url} intercepted, going to modify`)
var content = `You are hacked by me`;
event.response.body = content;
return event.response;
}
});
await page.goto('http://exercise.kingname.info/exercise_ajax_1.html');
})();
运行效果如下图所示:
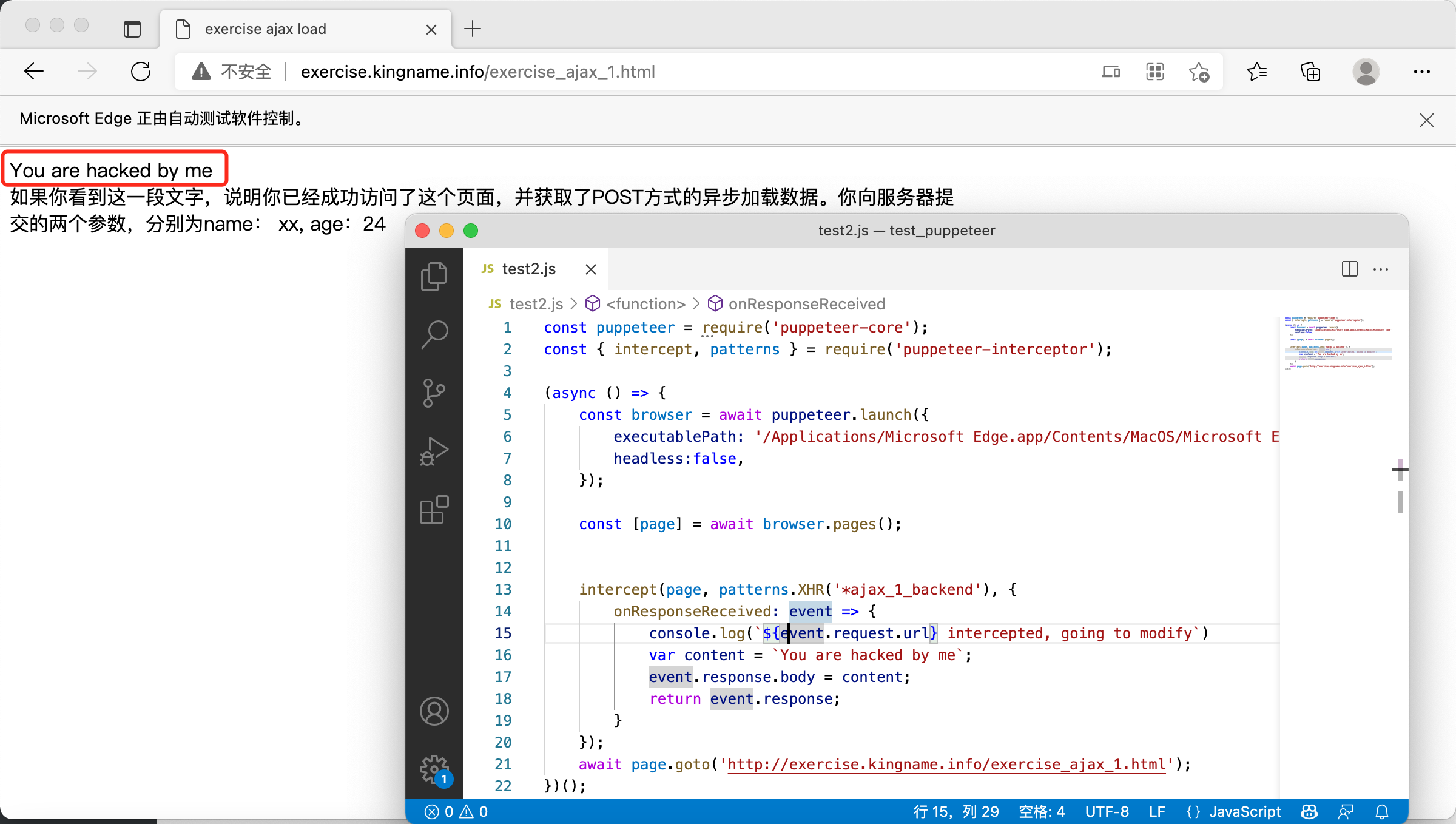
其中关键的代码如下:
intercept(page, patterns.XHR('*ajax_1_backend'), {
onResponseReceived: event => {
console.log(`${event.request.url} intercepted, going to modify`)
var content = `You are hacked by me`;
event.response.body = content;
return event.response;
}
});
这一段代码指定,要修改一个 XHR 请求的返回。这个 XHR 请求的 URL 是以ajax_1_backend结尾的。所谓的 XHR 请求,全称是XMLHttpRequest,大家可以把它近似看做 Ajax 请求。
当检测到满足这个通配符的请求时,无论它的内容是什么,都改写成You are hacked by me,然后返回给浏览器。
有人可能会问,你这样修改,简单是简单,但它有什么用呢?它的用处非常大,比如你在做爬虫的时候,把网站的 JavaScript 的一部分代码替换了,这样就能绕过反爬虫检测。
我做了一个示例的页面来说明。这个页面直接访问,如下图所示:

使用开发者工具,我们可以看到核心的反爬虫逻辑在http://127.0.0.1:8000/backend.js这个 js 文件中,如下图所示:
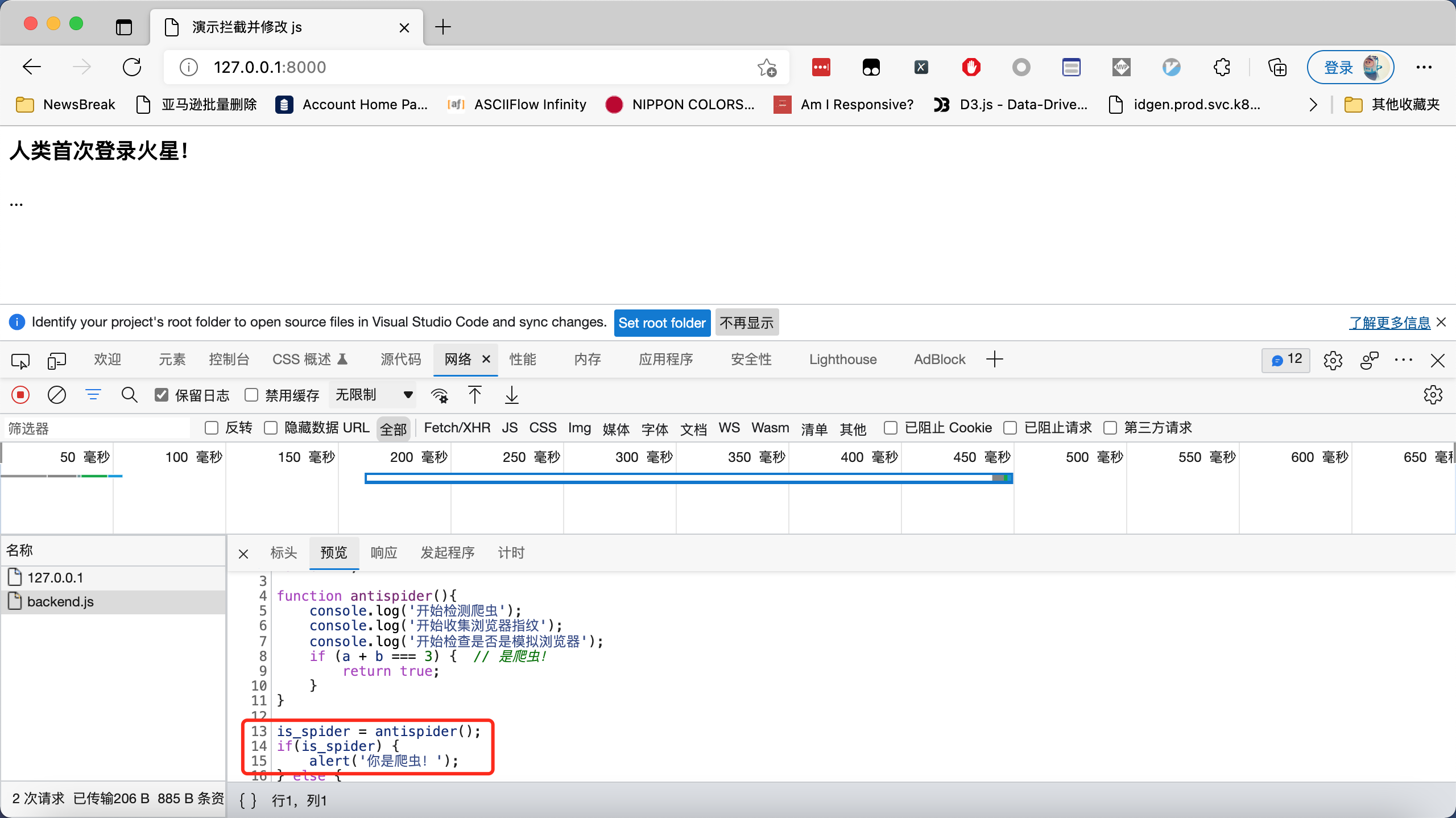
这个演示的例子中,这个反爬虫函数非常简单。但在真实的场景中,它的逻辑非常复杂。然而,逻辑再复杂,也有个调用入口。简单分析这个JavaScript 代码,我们可以知道,只需要把代码第14行注释掉,强制设置is_spider = false,就可以绕过这个反爬虫逻辑了。
为了绕过反爬虫逻辑,首先,我们把网站的这个JavaScript 代码复制下来,保存成safe.js文件。然后修改里面的代码,绕过反爬虫逻辑:
var a = 1;
var b = 2;
function antispider(){
console.log('开始检测爬虫');
console.log('开始收集浏览器指纹');
console.log('开始检查是否是模拟浏览器');
if (a + b === 3) { // 是爬虫!
return true;
}
}
is_spider = false; //这里强制写成 false
if(is_spider) {
alert('你是爬虫!');
} else {
document.getElementById("content").innerHTML = "In America, leave airplane, inner People, related to the benefit, know everything, know nothing, said nothing, above.";
}
接下来,修改 Puppeteer 的代码,从本地读取这个修改后的 js 文件,然后拦截真正的请求并使用修改后的代码替换:
const puppeteer = require('puppeteer-core');
const fs = require('fs');
const { intercept, patterns } = require('puppeteer-interceptor');
(async () => {
const safe_code = fs.readFileSync('./safe.js', 'utf8');
const browser = await puppeteer.launch({
executablePath: '/Applications/Microsoft Edge.app/Contents/MacOS/Microsoft Edge',
headless:false,
});
const [page] = await browser.pages();
intercept(page, patterns.Script('*backend.js'), {
onResponseReceived: event => {
console.log(`${event.request.url} intercepted, going to modify`)
event.response.body = safe_code;
return event.response;
}
});
await page.goto('http://127.0.0.1:8000');
})();
运行效果如下图所示:

从图中可以看到,我们成功绕过了反爬虫的逻辑,获得了真正的页面数据。
这里有两个地方需要注意:
- 要拦截哪个请求,对应到的是
intercept函数的第二个参数。这个参数的值是patterns.XXX(地址通配符)。其中的 XXX 可以是如下几个关键词:Document, Stylesheet, Image, Media, Font, Script, TextTrack, XHR, Fetch, EventSource, WebSocket, Manifest, SignedExchange, Ping, CSPViolationReport, Preflight, Other。地址通配符注意是通配符不是正则表达式。通配符里面,*表示多个字符,?表示一个字符。 puppeteer-interceptor对中文的支持不太好。拦截到请求返回的数据以后,如果要修改文本,尽量修改成英文的。否则可能会报错。
puppeteer-interceptor不仅可以修改返回的内容,还可以修改网站的请求。更多强大功能,大家可以阅读它的官方文档。

- 点赞
- 收藏
- 关注作者
评论(0)