你真的懂使用Group by?

前言
IT学习日记的"第六十八篇",最近接触到的项目主要是数据分析为主,经常使用关于分组的功能实现,原来以为直接使用group by就可以解决需求,但是实际场景确实更为复杂,group by的作用也不仅仅只是实现按一个或者多个字段进行分组,官方其实还提供着更多的功能,本文主要通过项目的业务来分析group by使用的场景。
注: 本文的测试用例都是使用postgresql数据库11.9版本
SQL的执行顺序
在平常的工作中,后端开发或者数据库管理员应该是接触到SQL编写场景最频繁的用户,虽然,我们能够正常的通过需求完成SQL语句的编写,但是还是存在许多的小伙伴对SQL的执行顺序不了解的。其实,了解SQL的执行顺序对我们编写SQL、理解SQL、优化SQL都有很大的帮助,所以在在开始讲解Group by的使用之前,先简单了解下SQL执行的一个顺序。
1、SQL案例:
select…distinct…count()…from…table_name…on…join…where…group by…having…order by…limit
2、SQL执行的顺序(操作中临时表不使用了会被回收)
from -> on -> join -> where -> group by -> count(聚合函数) -> having -> select -> distinct -> order by -> limit
执行的顺序步骤解释
(1)、from: 表示数据的来源
(2)、on: 表示数据的关联表,执行完后生成一个临时表t1,提供给下一步的操作使用
(3)、join: 将join表的数据补充到on执行完成的临时表t1中,如: left join则将坐标剩余的数据添加到临时表t1中,如果join超过3个,则重复on…join之间的步骤。
(4)、where: 根据携带的条件,从临时表中筛选出符合条件的数据,并生成临时表t2。
(5)、groub by: 根据携带的条件,将临时表t2进行相应的数据分组,并形成临时表t3,如果语句包含了group by则它后面的字段必须出现在select中或者出现在聚合函数中,否则会报SQL语法错误。
(6)、count等聚合函数: 对临时表进行指定字段的聚合函数操作,形成临时表t5。
(7)、having: 筛选分组后临时表t3的数据,得到临时表t4。
(8)、select: 从临时表筛选出需要返回的数据,形成临时表t6。
(9)、distinct: 对临时表t6进行指定的去重筛选,形成临时表t7。
(10)、order by: 对临时表t7排序,形成临时表t8。
(11)、limit: 筛选返回的数据条数
SQL执行顺序的一些疑问
1、是先执行group by还是先执行select
答: 通过上面的SQL顺序执行可知,其实是限制性分组group by再进行查询数据的筛选。
2、为什么group by和select同时使用时,select中的字段必须出现在group by后或者聚合函数中。
答: 在SQL执行顺序中可以发现,是先执行group by再执行select,所以此时数据就可以能存在分组的一个字段对应非分组字段的多条数据,如果此时查询非分组字段,则可能出现歧义。如:使用班级分组,但是查询班级中的学生,此时一个班级对应多个学生,无法在分组的同时又查询单个学生,所以会出现歧义。
3、如何实现数据去重
答: 在SQL中可以通过关键字distinct去重,也可以通过group by分组实现去重,但实际上,如果数据量很大的话,使用distinct去重的效率会很慢,使用Group by去重的效率会更高,而且,很多distinct关键字在很多数据库中只支持对某个字段去重,无法实现对多个字段去重,如Postgresql数据库。(测试数据300w+,使用distinct去重需要十几秒,使用group by去重只需要几秒)。
Group by的用途
1、分组: 可以多一个字段或者多个字段进行分组数据统计
2、去重: 可以多一个字段或者多个字段去重,数据量大时比distinct效率更高,且使用场景更大。
3、分组并统计: 在分组的使用并实现对所有分组的数据总数统计,在数据分析中按组统计并展示合计数据的时候非常好用。
Group by的分组并统计功能介绍
场景:
对某些字段进行分组统计,同时或者到所有分组中的统计数据的综合,这是是数据分析中经常会遇到的场景。一般的解决方案都是先执行分组SQL,然后再执行查下总数SQL,但这样其实就重复请求了数据库,如果数据量表大条件复杂的时候,对效率的影响是很大的。
那么有没有方式可以在分组的同时也将总数统计出来,这样就无需重复查询数据,提高效率了,答案是有,就是使用官方提供的rollup或者cube或者grouping sets来实现。
一: Rollup、Cube、Grouping sets的介绍:
作用:
都是用于进行分组集合计算,不支持聚合函数中的DISTINCT或GROUP BY ALL子句,GROUP BY字句,ROLLUP/Cube/Grouping sets可以为 GROUP BY 运行结果的每一个分组返回一个统计,并且为所有分组返回一个总的统计行其中。Rollup和Cube是Grouping sets提供的速记的使用方式。
格式:
group by rollup/cube/grouping sets(分组字段)
相似点:
它们是group by的子集,cube和rollup都可以直接在group by 字句中使用,他们是grouping sets的一个简单实用方式
区别:
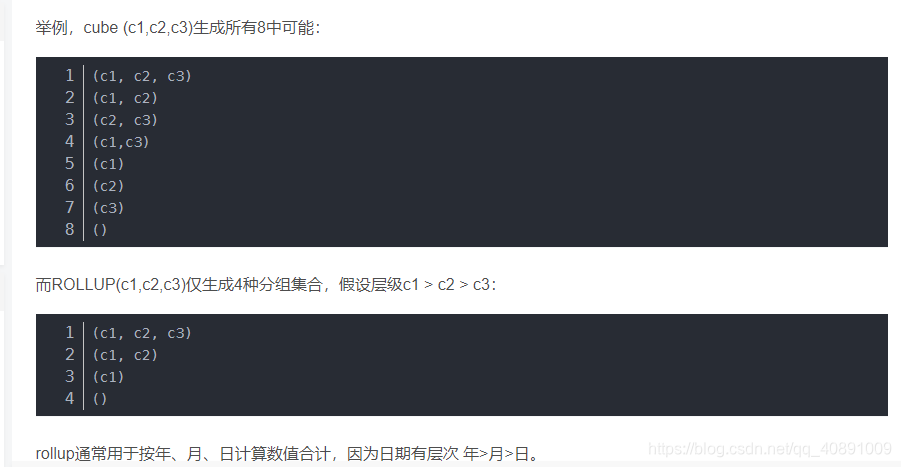
1、cube生成分组中特定列所有可能的层次组合。
2、rollup只会按照层次生成有可能的组合。
3、默认的group by语句相当于grouping set在grouping set后的参数填上所有group by。
Group by的分组并统计功能测试
1、测试分组后并统计到所有分组的一个统计结果(分组字段数据不为空)
(1)、使用rollup:

(2)、使用cube:
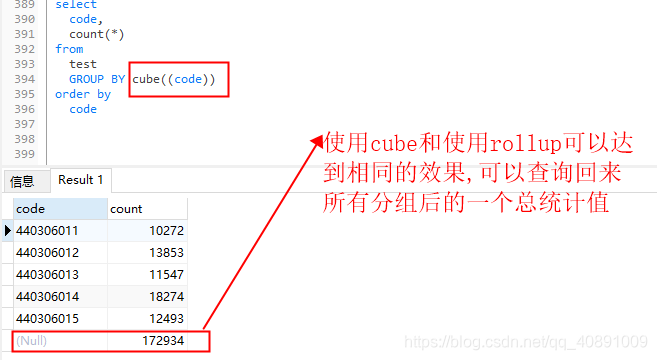
(3)、使用grouping sets:

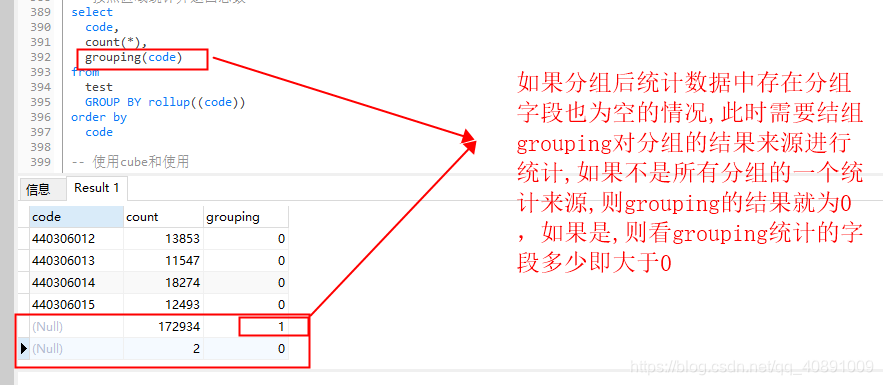
2、分组字段存在空的时候,区分空组统计和所有分组统计
3、grouping函数介绍
作用:
GROUPING() 函数用来返回每个分组是否为 ROLLUP(汇总)结果,是大于0,否为 0。GROUPING函数既可以与CUBE操作一起使用, 也可以与ROLLUP操作一起使用, 它能帮助你理解概要值是怎样产生的,就能区分哪些 NULL 是正常记录,哪些是 ROLLUP 的结果。。
使用:
GROUPING函数使用一个单独的列表示。在GROUPING函数中的expr必须匹配一个GROUP BY子句中的表达式, 该函数的返回值0或大于0。
返回的值计算方式:
(1)、ROUPING(r1,r2) 等价于 GROUPING(r2) + GROUPING(r1) << 1
(2)、GROUPING(r1,r2,r3,…) 等价于 GROUPING(r3) + GROUPING(r2) << 1 + - GROUPING(r1) << 2,其他的以此类推
总结
平常的工作中,可能很多人不会遇到这种场景,或者说,可以遇到了可能也不会去很深入的了解是否可以通过效率更高的方式来实现需求,所以不会去深挖,但是,如果想成为一名优秀的开发者,其实有时候要求我们有“咬文嚼字”的精神。
可能很多人遇到问题,如果论坛上无法找到需要的答案,可能就会选择将就的方式去实现,但其实很多问题,可以通过官方的文档找到一些解决方案。考虑到可能很多人感觉官方文档都是英文为主,不太适合阅读,在此处推荐一个关于PostGresql的中文网站,大家感兴趣的话可以去了解,地址: http://www.postgres.cn/v2/document
最后,如果大家觉得文章对你有些帮助,可以点击个关注和点赞,非常感谢,后面也会出更多在实际工作中遇到的问题的解决文章,如果有建议,也可以在下方留言。
由于之前说要将自己之前面试的问题总结出来,但是因为入职新公司的原因,鸽了大家太久,准备这两天将问题归类一下,刚好趁着“金三银四”的时间点,应该对大家会有一些帮助,后面搞个抽奖,补偿下被鸽的朋友

文章来源: it-learning-diary.blog.csdn.net,作者:IT学习日记,版权归原作者所有,如需转载,请联系作者。
原文链接:it-learning-diary.blog.csdn.net/article/details/115429440

- 点赞
- 收藏
- 关注作者
评论(0)