简单化MySQL优化小妙招

目录
博主介绍
💂 个人主页:苏州程序大白</ a>
💂 个人社区:CSDN全国各地程序猿</ a>
🤟作者介绍:中国DBA联盟(ACDU)成员,CSDN全国各地程序猿(媛)聚集地管理员。目前从事工业自动化软件开发工作。擅长C#、Java、机器视觉、底层算法等语言。2019年成立柒月软件工作室。
💬如果文章对你有帮助,欢迎关注、点赞、收藏(一键三连)和C#、Halcon、python+opencv、VUE、各大公司面试等一些订阅专栏哦
🎗️ 承接软件APP、小程序、网站等开发重点行业应用开发(SaaS、PaaS、CRM、HCM、银行核心系统、监管报送平台、系统搭建、人工智能助理)、大数据平台开发、商业智能、App开发、ERP、云平台、智能终端、产品化解决方案。测试软件产品测试、应用软件测试、测试平台及产品、测试解决方案。运维数据库维护(SQL Server 、Oracle、MySQL)、 操作系统维护(Windows、Linux、Unix等常用系统)、 服务器硬件设备维护、网络设备维护、 运维管理平台等。运营服务IT咨询 、IT服务、业务流程外包(BPO)、云/基础设施的管理、线上营销、数据采集与标注、内容管理和营销、设计服务、本地化、智能客服、大数据分析等。
💅 有任何问题欢迎私信,看到会及时回复
👤 微信号:stbsl6,微信公众号:苏州程序大白
🎯 想加入技术交流群的可以加我好友,群里会分享学习资料
SQL语句执行顺序

设置大小写不敏感
-
查看大小写是否敏感:
show variables like '%lower_case_table_names%'; windows 系统默认大小写不敏感,但是 linux 系统是大小写敏感的。 -
设置大小写不敏感:在
my.cnf这个配置文件 [mysqld] 中加入lower_case_table_names = 1,然后重启服务器。
| 属性设置 | 描述 |
|---|---|
| 0 | 大小写敏感 |
| 1 | 大小写不敏感。创建的表,数据库都是以小写形式存放在磁盘上,对于 sql 语句都是转换为小写对表和 DB 进行查找 |
| 2 | 创建的表和 DB 依据语句上格式存放,凡是查找都是转换为小写进行 |
注意:在设置属性为大小写不敏感前就需要将原来的数据库和表转换为小写,否则会找不到数据库名。
MySql 的用户和权限管理
用户管理:
-- 创建用户
create user ahzoo identified by '123456';
-- 查看用户和权限的相关信息
select host,user,password,select_priv,insert_priv,drop_priv from mysql.user
-- 修改当前用户密码
set password =password('1234');
-- 修改其他用户密码
update mysql.user set password=password('123456') where user='ouo';
-- 所有通过user表的操作,都必须使用下面命令才能生效
flush privileges;
-- 修改用户名
update mysql.user set user='ahzoo' where user='ouo';
flush privileges;
-- 删除用户
drop user ouo;
-- 注意:删除用户时,不建议使用下面命令进行删除,因为系统会有残留信息保留
delete from user where user='ouo'
flush privileges;
权限管理:
授予权限
grant 权限 1,权限 2,…权限 n on 数据库名称.表名称 to 用户名@用户地址 identified by '密码';
-- 授予数据库下所有表,所有权限
grant all privileges on testDB.* to ahzoo@localhost identified by '123456';
-- 授予所有库、表增删改查权限
grant select,insert,delete,drop on *.* to ahzoo@localhost identified by '123456';
-- 对网络用户授权;@'%' 表示对非本地主机用户授权,不包括localhost
grant all privileges on *.* to ouo@'%' identified by '123456'
-- 查看权限
show grants;
取消权限
revoke [权限 1,权限 2,…权限 n] on 库名.表名 from 用户名@用户地址;
revoke all privileges on testDB.* from ahzoo@localhost;
索引优化
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据, 这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。下图就是一种可能的索引方式示例:

左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址。为了加快 Col2 的查找,可以维护一个 右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指 针,这样就可以运用 二叉查找在一定的复杂度内获取到相应数据,从而快速的检索出符合条件的记录。 一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。
索引优势:
-
提高数据检索的效率,降低数据库的IO成本。
-
通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
索引劣势:
-
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为 更新所带来的键值变化后的索引信息。
-
实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的。
MySQL 索引
Btree
MySQL 使用的是 Btree 索引:

一颗 b 树,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块 1 包含数据项 17 和 35,包含指针 P1、P2、P3,P1 表示小于 17 的磁盘块,P2 表示在 17 和 35 之间的磁盘块,P3 表示大于 35 的磁盘块。
真实的数据存在于叶子节点即 3、5、9、10、13、15、28、29、36、60、75、79、90、99。
非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如 17、35 并不真实存在于数据表中。
查找过程:
如果要查找数据项 29,那么首先会把磁盘块 1 由磁盘加载到内存,此时发生一次 IO,在内存中用二分查找确定 29在 17 和 35 之间,锁定磁盘块 1 的 P2 指针,内存时间因为非常短(相比磁盘的 IO)可以忽略不计,通过磁盘块 1的 P2 指针的磁盘地址把磁盘块 3 由磁盘加载到内存,发生第二次 IO,29 在 26 和 30 之间,锁定磁盘块 3 的 P2 指针,通过指针加载磁盘块 8 到内存,发生第三次 IO,同时内存中做二分查找找到 29,结束查询,总计三次 IO。
真实的情况是,3 层的 b+树可以表示上百万的数据,如果上百万的数据查找只需要三次 IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次 IO,那么总共需要百万次的 IO,显然成本非常非常高。
B+tree

B+Tree 与 B-Tree 的区别:
1、B-树的关键字和记录是放在一起的,叶子节点可以看作外部节点,不包含任何信息;B+树的非叶子节点中只有关键字和指向下一个节点的索引,记录只放在叶子节点中。
2、在 B-树中,越靠近根节点的记录查找时间越快,只要找到关键字即可确定记录的存在;而 B+树中每个记录的查找时间基本是一样的,都需要从根节点走到叶子节点,而且在叶子节点中还要再比较关键字。从这个角度看 B- 树的性能好像要比 B+树好,而在实际应用中却是 B+树的性能要好些。因为 B+树的非叶子节点不存放实际的数据,这样每个节点可容纳的元素个数比 B-树多,树高比 B-树小,这样带来的好处是减少磁盘访问次数。尽管 B+树找到一个记录所需的比较次数要比 B-树多,但是一次磁盘访问的时间相当于成百上千次内存比较的时间,因此实际中B+树的性能可能还会好些,而且 B+树的叶子节点使用指针连接在一起,方便顺序遍历(例如查看一个目录下的所有文件,一个表中的所有记录等),这也是很多数据库和文件系统使用 B+树的缘故。
为什么 B+树比 B-树更适合实际应用中操作系统的文件索引和数据库索引:
- B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对 B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说 IO 读写次数也就降低了。
- B+树的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
聚簇索引和非聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。术语‘聚簇’表示数据行和相邻的键值聚簇的存储 在一起。
如下图,左侧的索引就是聚簇索引,因为数据行在磁盘的排列和索引排序保持一致。
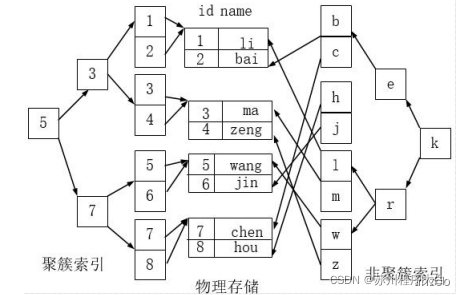
- 聚簇索引的好处:
按照聚簇索引排列顺序,查询显示一定范围数据的时候,由于数据都是紧密相连,数据库不不用从多 个数据块中提取数据,所以节省了大量的 io 操作。
- 聚簇索引的限制:
对于 mysql 数据库目前只有 innodb 数据引擎支持聚簇索引,而 Myisam 并不支持聚簇索引。 由于数据物理存储排序方式只能有一种,所以每个 Mysql 的表只能有一个聚簇索引。一般情况下就是 该表的主键。 为了充分利用聚簇索引的聚簇的特性,所以 innodb 表的主键列尽量选用有序的顺序 id,而不建议用 无序的 id,比如 uuid 这种
Mysql 索引分类
-- 创建
CREATE [UNIQUE] INDEX [indexName] ON table_name(column))
-- 删除
DROP INDEX [indexName] ON tableName;
-- 查看
SHOW INDEX FROM tableName;
-- 使用Alter命令:
-- 该语句添加一个主键,这意味着索引值必须是唯一的,且不能为 NULL:
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list)
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list)
-- 添加普通索引,索引值可出现多次:
ALTER TABLE tbl_name ADD INDEX index_name (column_list)
--该语句指定了索引为 FULLTEXT ,用于全文索引:
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list)
单值索引
即一个索引只包含单个列,一个表可以有多个单列索引。
-- 在表创建时直接创建索引
CREATE TABLE customer (
id INT(10) UNSIGNED AUTO_INCREMENT ,
customer_no VARCHAR(200),
customer_name VARCHAR(200),
PRIMARY KEY(id),
KEY (customer_name)
);
-- 单独创建索引:
CREATE INDEX idx_customer_name ON customer(customer_name);
唯一索引
索引列的值必须唯一,但允许有空值。
-- 随表一起创建:
CREATE TABLE customer (
id INT(10) UNSIGNED AUTO_INCREMENT ,
customer_no VARCHAR(200),
customer_name
VARCHAR(200),
PRIMARY KEY(id),
KEY (customer_name),
UNIQUE (customer_no)
);
-- 单独建唯一索引:
CREATE UNIQUE INDEX idx_customer_no ON customer(customer_no
主键索引
设定为主键后数据库会自动建立索引,innodb为聚簇索引。
-- 随表创建
CREATE TABLE customer (
id INT(10) UNSIGNED AUTO_INCREMENT ,
customer_no VARCHAR(200),
customer_name
VARCHAR(200),
PRIMARY KEY(id)
);
-- 单独建主键索引:
ALTER TABLE customer add PRIMARY KEY customer(customer_no)
-- 删除建主键索引:
ALTER TABLE customer drop PRIMARY
复合索引
即一个索引包含多个列。
-- 随表一起建索引:
CREATE TABLE customer (
id INT(10) UNSIGNED AUTO_INCREMENT ,
customer_no VARCHAR(200),
customer_name
VARCHAR(200),
PRIMARY KEY(id),
KEY (customer_name),
UNIQUE (customer_name),
KEY (customer_no,customer_name)
);
-- 单独建索引:
CREATE INDEX idx_no_name ON customer(customer_no,customer_name);
索引优化
- 最佳左前缀法则
使用复合索引时,需遵循最左前缀法则(查询从索引的最左前列开始并且不跳过索引中的列)。即过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。
- 不要在索引列上做任何计算
索引列上做【计算、函数、(自动\手动)类型转换】等操作时,会导致索引失效而转向全表扫描。
- 索引列上不能有范围查询
执行mysql命令时应将可能做范围查询的字段的索引顺序放在最后。
- 尽量使用覆盖索引
覆盖索引:SQL 只需要通过索引就可以返回查询所需要的数据,而不必通过二级索引查到主键之后再去查询数据。即查询列和索引列时不要使用 select *…而是使用select a,b,c….。
1、使用不等于(!= 或者<>)时,有时会无法使用索引会导致全表扫描。
2、字段的 is null 可以用到索引 而 is not null 不会使用索引。
3、不能使用前缀进行模糊匹配:
... like '%a%' √... like '%a' √... like 'a%' ×
使用 union all 或者 union 来替代or示例:
假设abc为索引
-- 索引被使用:
where a = 3;
where a = 3 and b = 5;
where a = 3 and b = 5 and c = 4;
-- 索引未被使用:
where a <> 3;
where abs(a) =3;
where b = 3;
where b = 3 and c = 4;
where c = 4;
-- 使用到a索引,但是未使用b、c索引
where a = 3 and c = 5;
where a = 3 and b > 4 and c = 5;
where a is null and b is not null;
子查询优化
在范围判断时,尽量不要使用 not in 和 not exists,使用 left join on xxx i。
排序分组优化
- 无过滤,不索引
where,limt 都相当于一种过滤条件,所以才能使用上索引。
- 顺序错,必排序
where 两侧列的顺序可以变换,效果相同,但是 order by 列的顺序不能随便变换。
- 方向反,必排序
如果可以用上索引的字段都使用正序或者逆序,实际上是没有任何影响的,无非将结果集调换顺序。
-- 两个排序方式都是desc:
select * from mytest where name='ahzoo' order by deptid desc, name desc
如果排序的字段,顺序有差异,就需要将差异的部分,进行一次倒置顺序,因此还是需要手动排序的。
-- 两个排序方式相反,一个是降序一个是升序
select * from mytest where name='ahzoo' order by deptid desc, name asc
🌟作者相关的文章、资源分享🌟
🌟让天下没有学不会的技术🌟
学习C#不再是难问题
🌳《C#入门到高级教程》🌳</ a>
有关C#实战项目
👉C#RS232C通讯源码👈</ a>
👉C#委托数据传输👈</ a>
👉C# Modbus TCP 源代码👈</ a>
👉C# 仓库管理系统源码👈</ a>
👉C# 欧姆龙通讯Demo👈</ a>
👉C#+WPF+SQL目前在某市上线的车管所摄像系统👈</ a>
👉2021C#与Halcon视觉通用的框架👈</ a>
👉2021年视觉项目中利用C#完成三菱PLC与上位机的通讯👈</ a>
👉VP联合开源深度学习编程(WPF)👈</ a>
✨有关C#项目欢迎各位查看个人主页✨
🌟机器视觉、深度学习🌟
学习机器视觉、深度学习不再是难问题
🌌《Halcon入门到精通》🌌</ a>
🌌《深度学习资料与教程》🌌</ a>
有关机器视觉、深度学习实战
👉2021年C#+HALCON视觉软件👈</ a>
👉2021年C#+HALCON实现模板匹配👈</ a>
👉C#集成Halcon的深度学习软件👈</ a>
👉C#集成Halcon的深度学习软件,带[MNIST例子]数据集👈</ a>
👉C#支持等比例缩放拖动的halcon WPF开源窗体控件👈</ a>
👉2021年Labview联合HALCON👈</ a>
👉2021年Labview联合Visionpro👈</ a>
👉基于Halcon及VS的动车组制动闸片厚度自动识别模块👈</ a>
✨有关机器视觉、深度学习实战欢迎各位查看个人主页✨
🌟Java、数据库教程与项目🌟
学习Java、数据库教程不再是难问题
🍏《JAVA入门到高级教程》🍏</ a>
🍏《数据库入门到高级教程》🍏</ a>
有关Java、数据库项目实战
👉Java经典怀旧小霸王网页游戏机源码增强版👈</ a>
👉js+css类似网页版网易音乐源码👈</ a>
👉Java物业管理系统+小程序源码👈</ a>
👉JavaWeb家居电子商城👈</ a>
👉JAVA酒店客房预定管理系统的设计与实现SQLserver👈</ a>
👉JAVA图书管理系统的研究与开发MYSQL👈</ a>
✨有关Java、数据库教程与项目实战欢迎各位查看个人主页✨
🌟分享Python知识讲解、分享🌟
学习Python不再是难问题
🥝《Python知识、项目专栏》🥝</ a>
🥝《Python 检测抖音关注账号是否封号程》🥝</ a>
🥝《手把手教你Python+Qt5安装与使用》🥝</ a>
🥝《用一万字给小白全面讲解python编程基础问答》🥝</ a>
🥝《Python 绘制Android CPU和内存增长曲线》🥝</ a>
🥝《☀️苏州程序大白用万字解析Python网络编程与Web编程☀️《❤️记得收藏❤️》》🥝</ a>
有关Python项目实战
👉Python基于Django图书管理系统👈</ a>
👉Python管理系统👈</ a>
👉2021年9个常用的python爬虫源码👈</ a>
👉python二维码生成器👈</ a>
✨有关Python教程与项目实战欢迎各位查看个人主页✨
🌟分享各大公司面试题、面试流程🌟
面试成功不是难事
🍏《2021年金九银十最新的VUE面试题☀️《❤️记得收藏❤️》》🍏</ a>
🍏《只要你认真看完一万字☀️Linux操作系统基础知识☀️分分钟钟都吊打面试官《❤️记得收藏❤️》》🍏</ a>
🍏《❤️用一万字给小白全面讲解python编程基础问答❤️《😀记得收藏不然看着看着就不见了😀》》🍏</ a>
✨有关各大公司面试题、面试流程欢迎各位查看个人主页✨
💫点击直接资料领取💫

这里有各种学习资料还有有有趣好玩的编程项目,更有难寻的各种资源。

- 点赞
- 收藏
- 关注作者
评论(0)