DDD - 聚合与聚合根_如何理解 Respository与DAO


Pre
通常情况,我们都会面临这样的一个问题: 架构图说的是一回事,代码说的却是另一回事 。 当然了这里面的影响因素很多,有一个原因就是某些约束没有在设计中体现出来,也就是说设计的表现力不够 , 而这些约束需要阅读代码才能够知道,这就增加了理解和使用这个组件的难度。
这个问题在基于数据建模的设计方法上比较明显, 举个例子:
DDD - 如何理解Entity与VO提到的购物场景 ,我们以数据驱动的方式来设计订单和产品表,
CREATE TABLE `order` (
`rec_id` BIGINT(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`seller_id` BIGINT(11) NOT NULL COMMENT '卖家',
`buyer_id` BIGINT(11) NOT NULL COMMENT '买家',
`price` BIGINT(11) NOT NULL COMMENT '订单总价格,按分计算',
...
PRIMARY KEY (`rec_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
CREATE TABLE `order_detail` (
`rec_id` BIGINT(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`order_id` BIGINT(11) NOT NULL COMMENT '订单主键',
`product_name` VARCHAR(50) COMMENT '产品名称',
`product_desc` VARCHAR(200) COMMENT '产品描述',
`product_price` BIGINT(11) NOT NULL COMMENT '产品价格,按分计算',
...
PRIMARY KEY (`rec_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
从表关系上,只能知道order与order_detail是一对多的关系。
CREATE TABLE `product` (
`rec_id` BIGINT(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` VARCHAR(50) COMMENT '产品名称',
`desc` VARCHAR(200) COMMENT '产品描述',
...
PRIMARY KEY (`rec_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
CREATE TABLE `product_comment` (
`rec_id` BIGINT(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`product_id` BIGINT(11) NOT NULL COMMENT '产品',
`cont` VARCHAR(2000) COMMENT '评价内容',
...
PRIMARY KEY (`rec_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
从表关系上,也只能知道product与product_comment之间是一对多的关系
Question
Q: order与order_detail之间的关系与product与product_comment之间的关系是一样的吗 ?

这mmp, 单单从数据模型上完全区分不出来啊 ,那只能看下业务代码
@Service
@Transactional
public class OrderService {
public void createOrder(Order order,List<OrderDetail> orderDetailList) throws Exception {
// 保存订单
// 保存订单详情
}
}
}
@Service
@Transactional
public class ProductService {
public void createProduct(Product prod) throws Exception {
// 保存产品
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 订单和订单明细是一起保存的,也就是说两者可以作为一个整体来看待 (这个整体就是我们说的聚合)
- 产品和产品评论之间并不能被看做一个整体,所以没有在一起进行操作
这层逻辑,光看上面的设计是看不出来的,只有看到代码了,才能理清这一层关系 , 无形中就增加了理解和使用难度。
「聚合」就是缓解这种问题的一种手段!

如何理解 聚合和聚合根
public class Artisan {
public void say() {
System.out.println("1");
System.out.println("2");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
对于上面的代码,如何保障在多线程情况下1和2能按顺序打印出来?最简单的方法就是使用synchronized关键字进行加锁操作
public class Artisan {
public synchronized void say() {
System.out.println("1");
System.out.println("2");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
synchronized保证了代码的原子性执行. 就像 事务保证了原子性操作一样。
但是,这和「聚合」有什么关系呢?
如果说,synchronized是多线程层面的锁;事务是数据库层面的锁,那么「聚合」就是业务层面的锁!
在业务逻辑上,有些对象需要保持操作上的原子性,否则就没有任何意义。这些对象就组成了「聚合」!
利用聚合解决业务上的原子性操作
对于上面的订单与订单详情,从业务上来看,订单与订单明细需要保持业务上的原子性操作:
- 订单必须要包含订单明细
- 订单明细必须要属于某个订单
- 订单和订单明细被视为一个整体,少了任何一个都没有意义
所以其对象模型可以表示为:
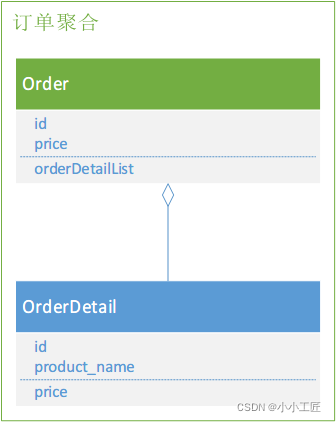
- 订单和订单明细组成一个「聚合」
- 订单是操作的主体,所以订单是这个「聚合」的「聚合根」
- 所有对这个「聚合」的操作,只能通过「聚合根」进行

相应的,产品和产品评价就不构成「聚合」。虽然在表设计时,订单和订单明细的结构关系与产品与产品评价的结构关系是一样的!因为:
- 虽然产品评价需要属于某个产品
- 但是产品不一定就有产品评价
- 产品评价可以独立操作
所以产品与产品评论的模型则可以表示为:
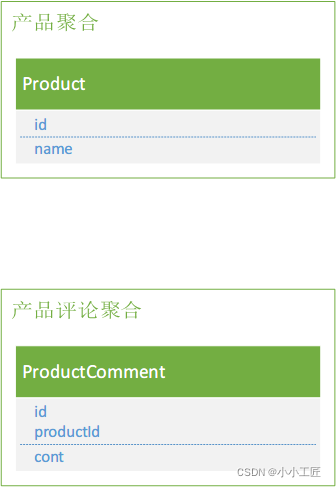
- 产品和产品评论是两个「聚合」
- 产品评论通过productId与「产品聚合」进行关联
如何确定聚合和聚合根
对象在业务逻辑上是否需要保证原子性操作是确定聚合和聚合根的其中一个约束。
还有一个约束就是「边界」,即聚合多大才合适?过大的「聚合」会带来各种问题。
还是以锁举例,看下面的代码
public class Artisan{
public synchronized void say() {
System.out.println("0");
System.out.println("1");
System.out.println("2");
System.out.println("4");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
只希望12能按顺序打印出来,而0和4没有这个要求!上面的代码能满足要求,但是影响了性能。优化方式是使用同步块,缩小同步范围:
public class Artisan{
public void say() {
System.out.println("0");
synchronized(Locker.class){
System.out.println("1");
System.out.println("2");
}
System.out.println("4");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
「边界」就像上面的同步块一样,只将需要的对象组合成聚合!
假设上面的产品和产品评论构成了一个聚合!那会发生什么事情呢?当A,B两个用户同时对这个商品进行评论,A先开始评论,此时就会锁定该产品对象以及下面的所有评论,在A提交评论之前,B是无法操作这个产品对象的,显然这是不合理的。

Respository VS DAO
在理解了聚合之后,就可以很容易的区分Respository与DAO了
- DAO是技术手段,Respository是抽象方式
- DAO只是针对对象的操作,而Respository是针对「聚合」的操作
【DAO的操作方式】
@Service
@Transactional
public class OrderService {
public void createOrder(Order order,List<OrderDetail> orderDetailList) throws Exception {
Long orderId = orderDao.save(order);
for(OrderDetail detail : orderDetailList) {
detail.setOrderId(orderId);
orderDetailDao.save(detail);
}
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 订单和和订单明细都有一个对应的DAO
- 订单和订单明细的关系并没有在对象之间得到体现

【Respository的操作方式】
// 订单和订单明细构成聚合
public clas Order{
List<OrderDetail> itemLine; // 这里就保证了设计与编码的一致性
...
}
@Service
@Transactional
public class OrderService {
public void createOrder(Order order) throws Exception {
orderRespository.save(order);
//or
order.save(); // 内部调用orderRespository.save(this);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
当然,orderRespository的save方法中,可能还是数据库相关操作,但也可能是NoSql操作甚至内存操作。

文章来源: artisan.blog.csdn.net,作者:小小工匠,版权归原作者所有,如需转载,请联系作者。
原文链接:artisan.blog.csdn.net/article/details/122443342

- 点赞
- 收藏
- 关注作者
评论(0)