【数据挖掘】关联规则挖掘 Apriori 算法 ( Apriori 算法过程 | Apriori 算法示例 )

参考博客 :
- 【数据挖掘】关联规则挖掘 Apriori 算法 ( 关联规则简介 | 数据集 与 事物 Transaction 概念 | 项 Item 概念 | 项集 Item Set | 频繁项集 | 示例解析 )
- 【数据挖掘】关联规则挖掘 Apriori 算法 ( 关联规则 | 数据项支持度 | 关联规则支持度 )
- 【数据挖掘】关联规则挖掘 Apriori 算法 ( 置信度 | 置信度示例 )
- 【数据挖掘】关联规则挖掘 Apriori 算法 ( 频繁项集 | 非频繁项集 | 强关联规则 | 弱关联规则 | 发现关联规则 )
- 【数据挖掘】关联规则挖掘 Apriori 算法 ( 关联规则性质 | 非频繁项集超集性质 | 频繁项集子集性质 | 项集与超集支持度性质 )
一、 Apriori 算法过程
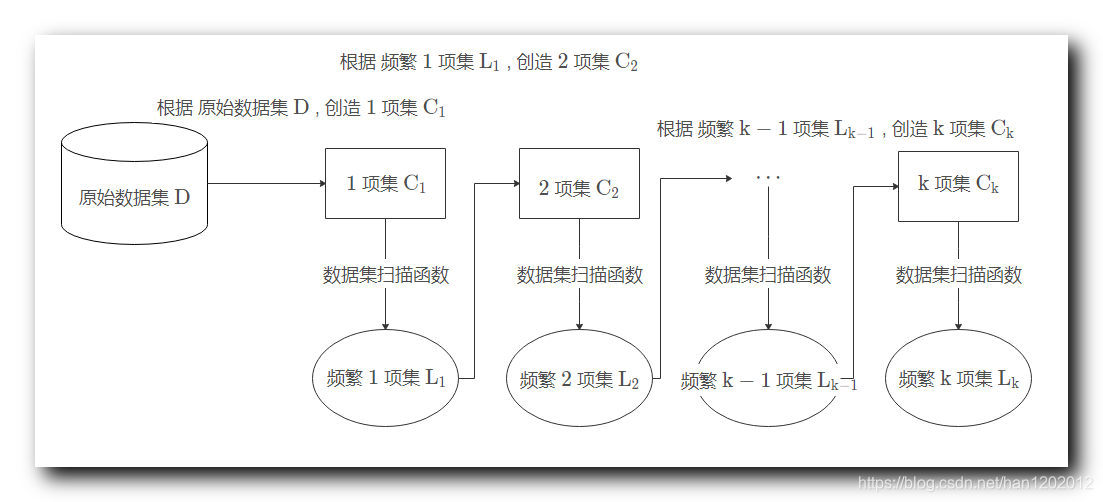
原始数据集 D \rm D D ,
1 1 1 项集 C 1 \rm C_1 C1 , 2 2 2 项集 C 2 \rm C_2 C2 , ⋯ \cdots ⋯ , k \rm k k 项集 C k \rm C_k Ck , 这些项集都是候选项集 ,
根据 原始数据集 D \rm D D , 创造 1 1 1 项集 C 1 \rm C_1 C1 , 然后对 C 1 \rm C_1 C1 执行 数据集扫描函数 , 找到其中的 频繁 1 1 1 项集 L 1 \rm L_1 L1 ,
根据 频繁 1 1 1 项集 L 1 \rm L_1 L1 , 创造 2 2 2 项集 C 2 \rm C_2 C2 , 然后对 C 2 \rm C_2 C2 执行 数据集扫描函数 , 找到其中的 频繁 2 2 2 项集 L 2 \rm L_2 L2 ,
⋮ \vdots ⋮
根据 频繁 k − 1 \rm k-1 k−1 项集 L k − 1 \rm L_{k-1} Lk−1 , 创造 k \rm k k 项集 C k \rm C_k Ck , 然后对 C k \rm C_k Ck 执行 数据集扫描函数 , 找到其中的 频繁 k \rm k k 项集 L k \rm L_k Lk ,
二、 Apriori 算法示例
| 事物编号 | 事物 ( 商品 ) |
|---|---|
| 001 001 001 | 奶粉 , 莴苣 |
| 002 002 002 | 莴苣 , 尿布 , 啤酒 , 甜菜 |
| 003 003 003 | 奶粉 , 尿布 , 啤酒 , 橙汁 |
| 004 004 004 | 奶粉 , 莴苣 , 尿布 , 啤酒 |
| 005 005 005 | 奶粉 , 莴苣 , 尿布 , 橙汁 |
最小支持度阈值为 m i n s u p = 0.6 \rm minsup= 0.6 minsup=0.6
根据 原始数据集 D \rm D D , 创造 1 1 1 项集 C 1 \rm C_1 C1 , 然后对 C 1 \rm C_1 C1 执行 数据集扫描函数 , 找到其中的 频繁 1 1 1 项集 L 1 \rm L_1 L1 ,
1 1 1 项集 { 奶 粉 } \{ 奶粉 \} {奶粉} 支持度 0.8 0.8 0.8
1 1 1 项集 { 莴 苣 } \{ 莴苣 \} {莴苣} 支持度 0.8 0.8 0.8
1 1 1 项集 { 尿 布 } \{ 尿布 \} {尿布} 支持度 0.8 0.8 0.8
1 1 1 项集 { 啤 酒 } \{ 啤酒 \} {啤酒} 支持度 0.6 0.6 0.6
1 1 1 项集 { 甜 菜 } \{ 甜菜 \} {甜菜} 支持度 0.2 0.2 0.2
1 1 1 项集 { 诚 挚 } \{ 诚挚 \} {诚挚} 支持度 0.4 0.4 0.4
1 1 1 项集中只有 { 奶 粉 } \{ 奶粉 \} {奶粉} , { 莴 苣 } \{ 莴苣 \} {莴苣} , { 尿 布 } \{ 尿布 \} {尿布} , { 啤 酒 } \{ 啤酒 \} {啤酒} 是频繁 1 1 1 项集 ;
根据 频繁 1 1 1 项集 L 1 \rm L_1 L1 , 创造 2 2 2 项集 C 2 \rm C_2 C2 , 然后对 C 2 \rm C_2 C2 执行 数据集扫描函数 , 找到其中的 频繁 2 2 2 项集 L 2 \rm L_2 L2 ,
2 2 2 项集 { 奶 粉 , 莴 苣 } \{ 奶粉 , 莴苣 \} {奶粉,莴苣} 支持度 0.6 0.6 0.6
2 2 2 项集 { 莴 苣 , 尿 布 } \{ 莴苣 , 尿布 \} {莴苣,尿布} 支持度 0.6 0.6 0.6
2 2 2 项集 { 莴 苣 , 啤 酒 } \{ 莴苣 , 啤酒 \} {莴苣,啤酒} 支持度 0.4 0.4 0.4
2 2 2 项集 { 尿 布 , 啤 酒 } \{ 尿布 , 啤酒 \} {尿布,啤酒} 支持度 0.8 0.8 0.8
2 2 2 项集 { 奶 粉 , 尿 布 } \{ 奶粉 , 尿布 \} {奶粉,尿布} 支持度 0.6 0.6 0.6
2 2 2 项集 { 奶 粉 , 啤 酒 } \{ 奶粉 , 啤酒 \} {奶粉,啤酒} 支持度 0.4 0.4 0.4
2 2 2 项集中只有 { 奶 粉 , 尿 布 } \{ 奶粉 , 尿布 \} {奶粉,尿布} , { 尿 布 , 啤 酒 } \{ 尿布 , 啤酒 \} {尿布,啤酒} , { 莴 苣 , 尿 布 } \{ 莴苣 , 尿布 \} {莴苣,尿布} , { 奶 粉 , 莴 苣 } \{ 奶粉 , 莴苣 \} {奶粉,莴苣} 是 频繁 2 2 2 项集 ;
根据 频繁 2 2 2 项集 L 1 \rm L_1 L1 , 创造 3 3 3 项集 C 3 \rm C_3 C3 , 然后对 C 3 \rm C_3 C3 执行 数据集扫描函数 , 找到其中的 频繁 3 3 3 项集 L 3 \rm L_3 L3 ,
3 3 3 项集 { 奶 粉 , 莴 苣 , 尿 布 } \{ 奶粉 , 莴苣 , 尿布 \} {奶粉,莴苣,尿布} 支持度 0.4 0.4 0.4
3 3 3 项集 { 奶 粉 , 莴 苣 , 啤 酒 } \{ 奶粉 , 莴苣 , 啤酒 \} {奶粉,莴苣,啤酒} 支持度 0.2 0.2 0.2
3 3 3 项集 { 莴 苣 , 尿 布 , 啤 酒 } \{ 莴苣 , 尿布 , 啤酒 \} {莴苣,尿布,啤酒} 支持度 0.4 0.4 0.4
3 3 3 项集 { 奶 粉 , 尿 布 , 啤 酒 } \{ 奶粉 , 尿布 , 啤酒 \} {奶粉,尿布,啤酒} 支持度 0.4 0.4 0.4
3 3 3 项集中没有频繁项集 ;
文章来源: hanshuliang.blog.csdn.net,作者:韩曙亮,版权归原作者所有,如需转载,请联系作者。
原文链接:hanshuliang.blog.csdn.net/article/details/109687195

- 点赞
- 收藏
- 关注作者
评论(0)