吴恩达老师机器学习笔记(三:神经网络学习)

吴恩达老师机器学习视频课程笔记简记
- 1
第9章节
课时64:
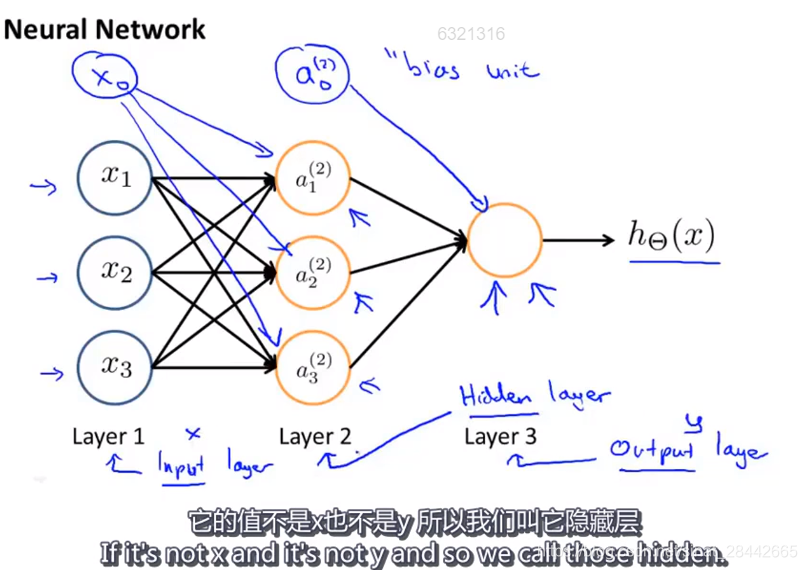
通常除了输入层和输出层,其他层都成为 隐藏层
定义基本的神经网络
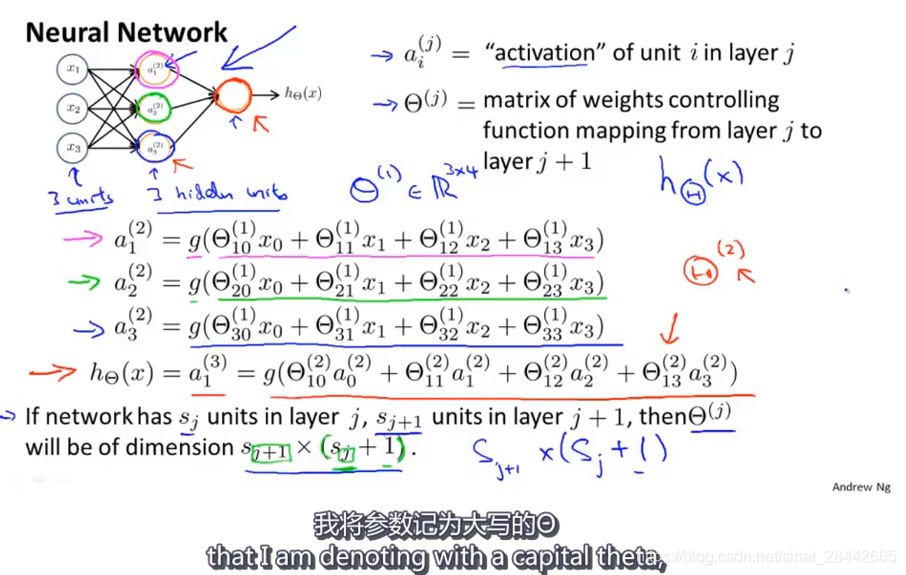
课时65:
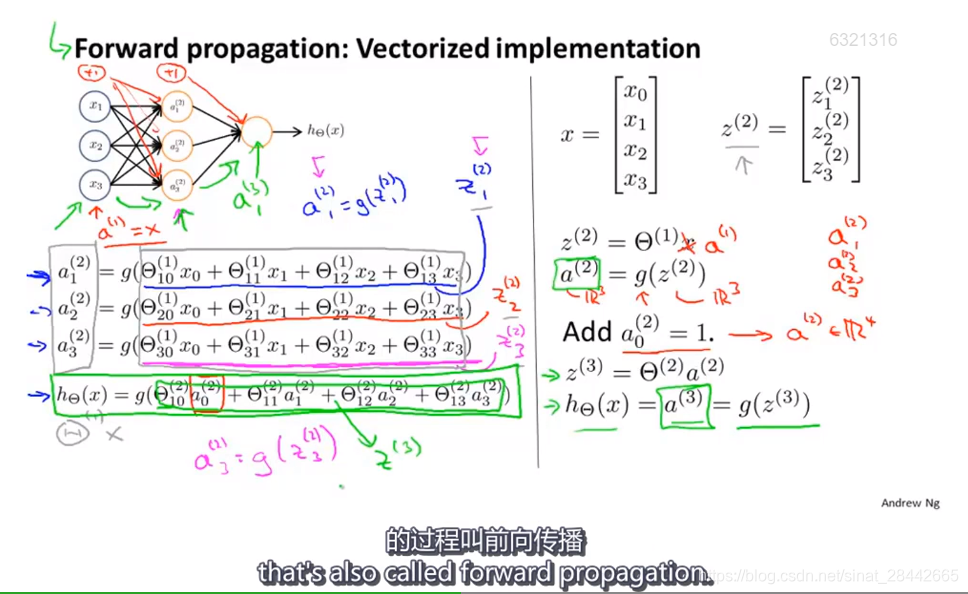
前向传播: 依次计算激活项,从输入层到隐藏层再到输出层的过程 叫做 前向传播
如图右侧:是向量化的表示方式
二分类与多分类
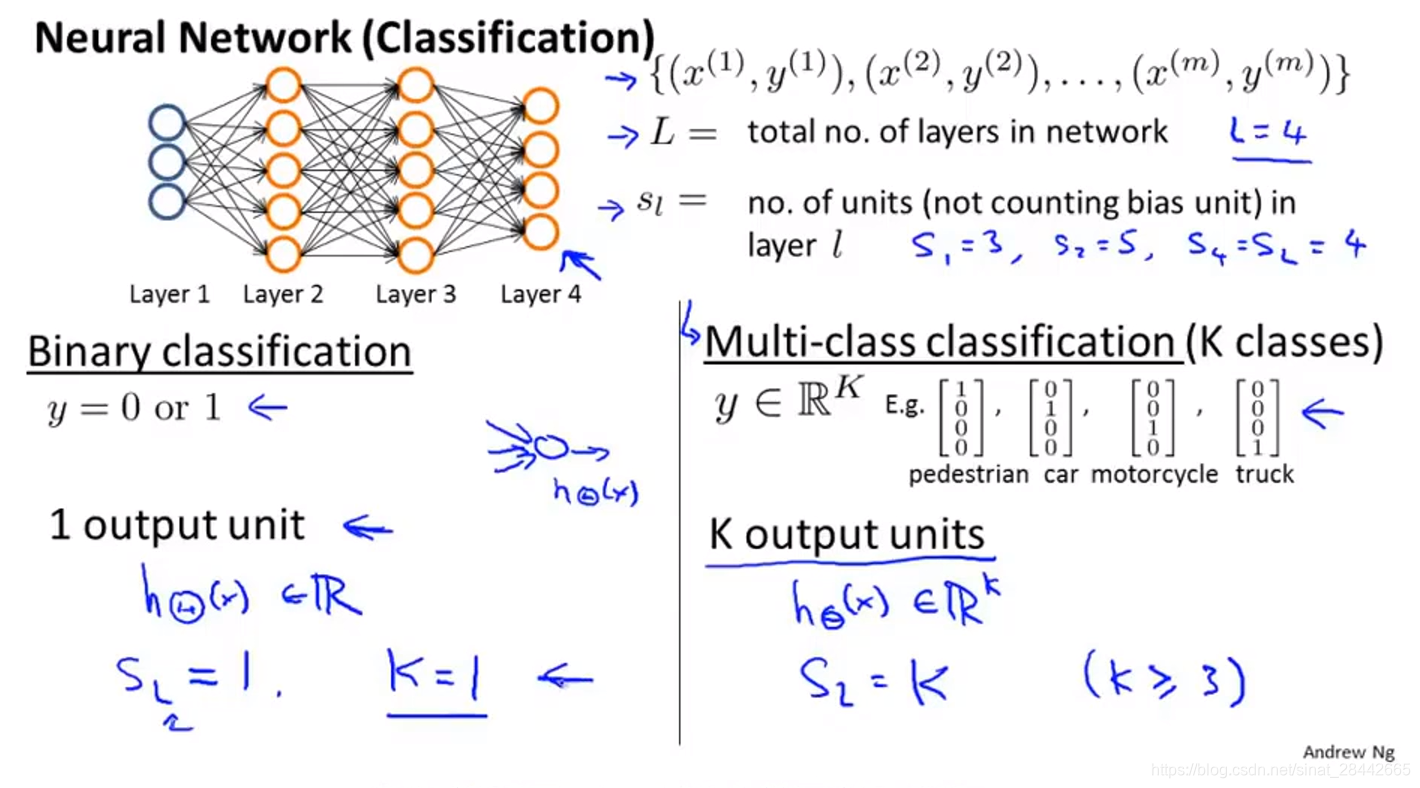
如图所示:
L 表示 网络的总层数
Sl 表示 L 层的单元个数
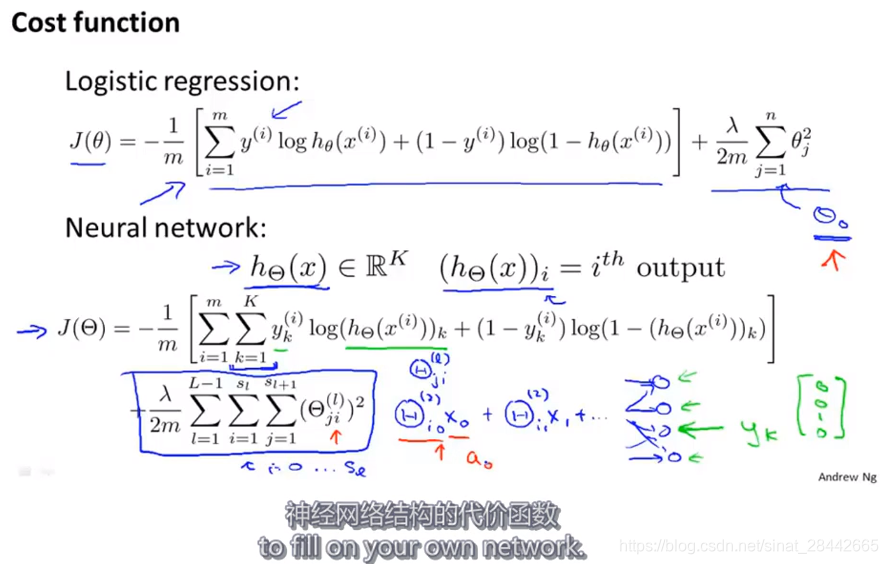
反向传播算法:

先进行正向传播,计算出输出层的值,与样本值 Y 相减 得到 输出层的误差,然后输出层的误差 * 输出层元素到 上一层各个元素的权重,该元素对应的 乘上权重的误差项的 和 就是 该元素的更新后的误差项,依次反向传播。

课时76:
检测反向传播是否正确的方法:


在运行代码时,要把梯度检验的代码注释或者禁用,以免影响程序效率。
随机初始化:
参数初始值全部设为0,则所有的隐藏单元都在计算相同的特征, 意味着最后的逻辑回归只能得到一个特征,起不到任何作用,为了解决这个问题, 在神经网络中对参数初始化时选择了随机初始化。
训练神经网络的过程:
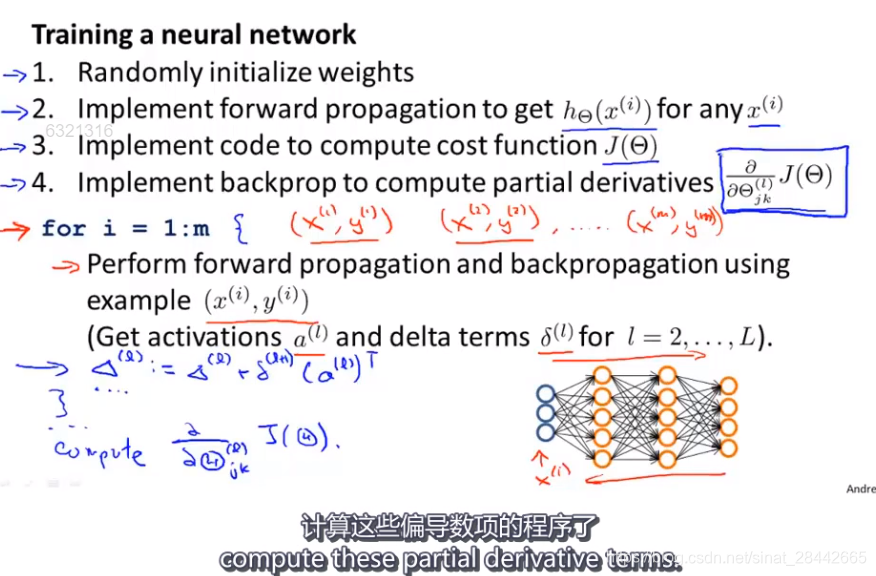

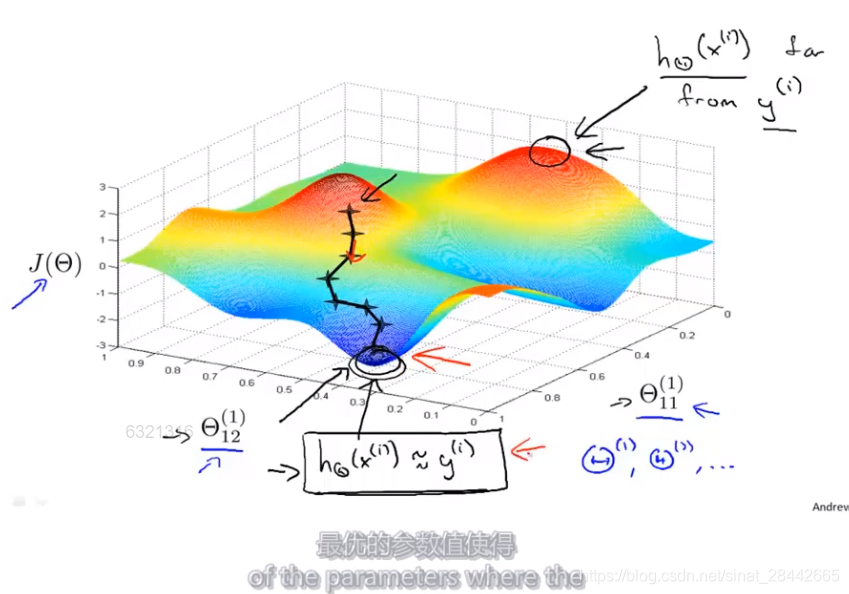
反向传播算法的目的: 算出梯度下降的方向
梯度下降的作用: 找到最优的参数值,使得神经网络的输出值与训练集中的 y 的实际值尽可能的接近
评估假设:
数据集分隔方法:
- 数据量大的情况可以:70%作为训练集,30%作为测试集
- 数据量小的情况可以:60%作为训练集,20%作为验证集,20%作为测试集, 使用交叉验证集 来选择最合适的模型,使用测试集进行评估。


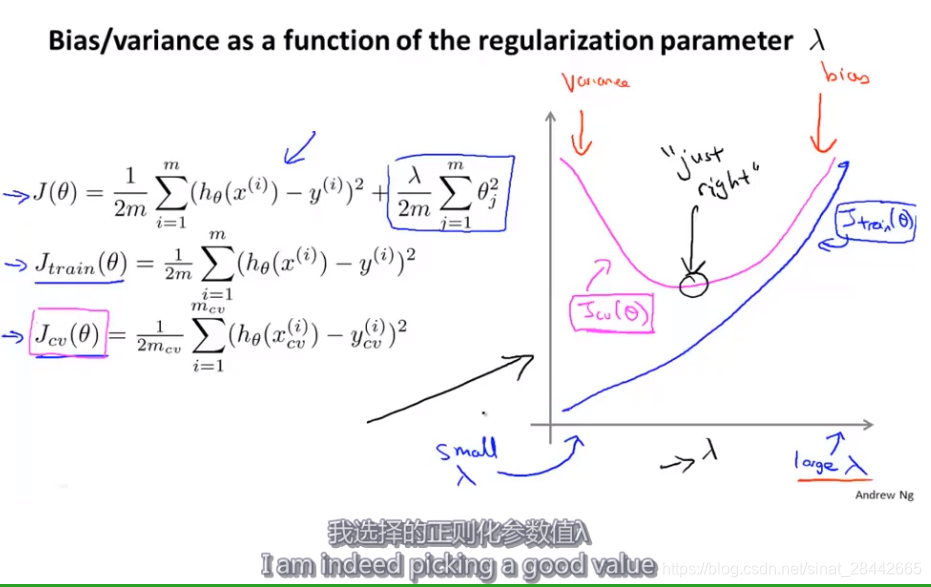
诊断偏差和方差:
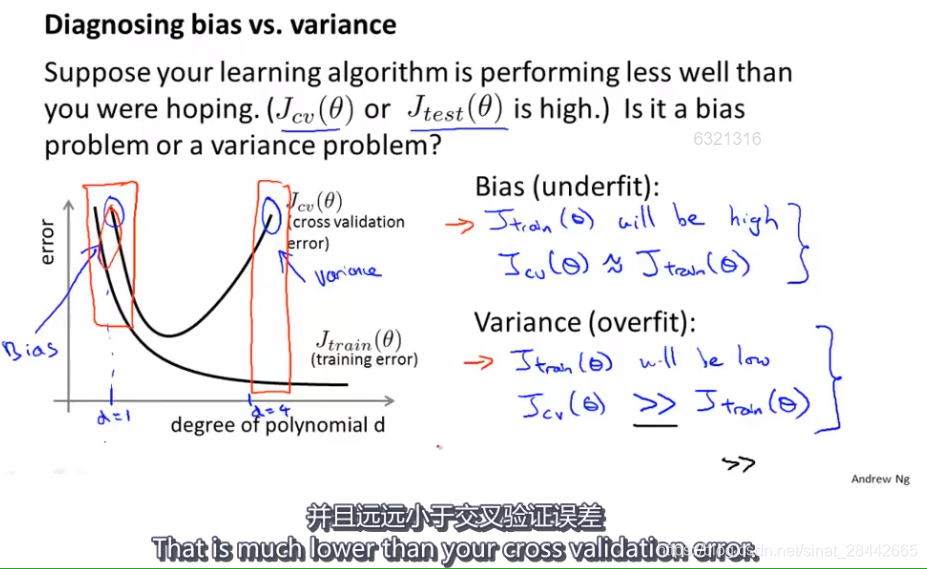
如图:随着拟合曲线次数 d 的增大,训练误差逐渐变小,交叉验证误差先变小后变大。
前半部分是 高偏差,后半部分为高方差。
欠拟合时: 训练误差和验证误差都很大
过拟合时: 训练误差很小,但是验证误差很大
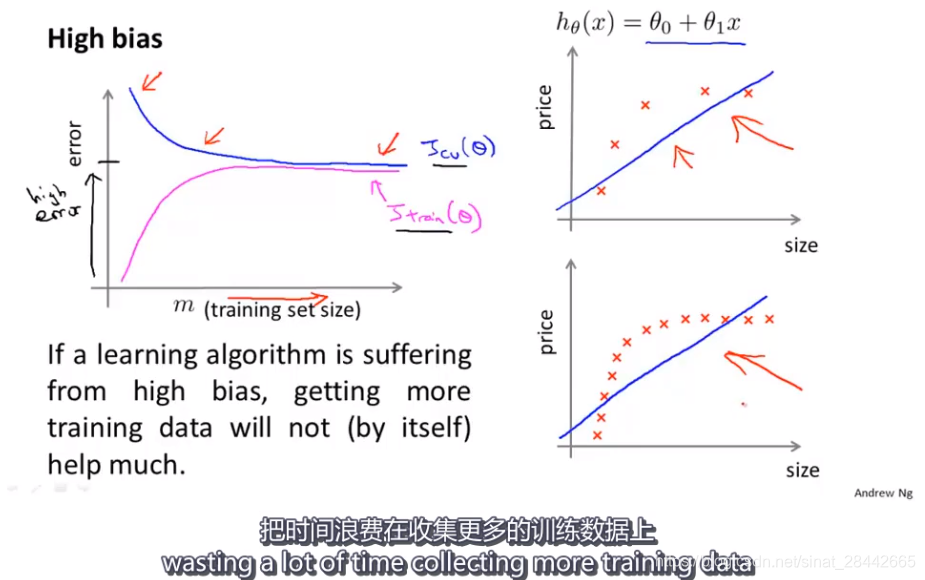
学习曲线:
当学习算法处于高偏差时,拥有更多的训练数据,也不能让交叉验证误差下降很多。
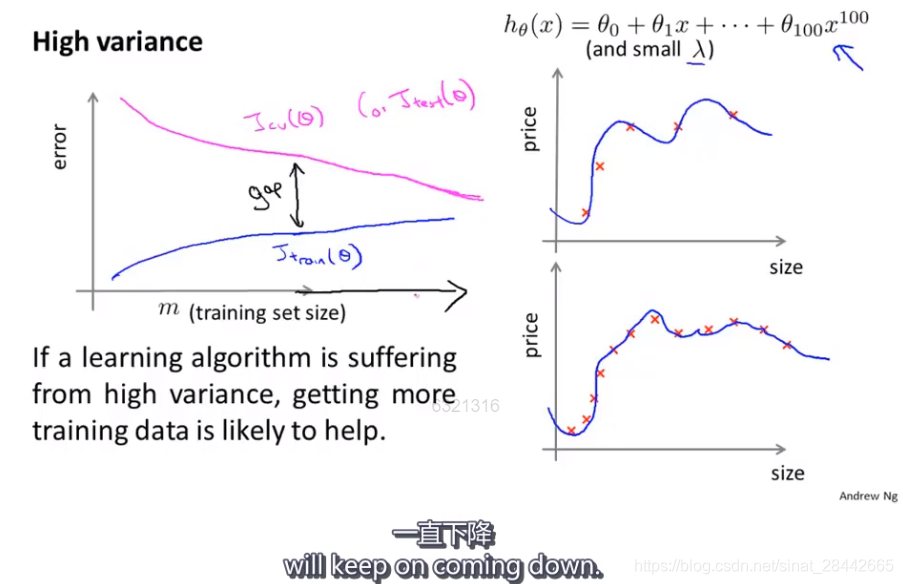
第12章节——机器学习系统设计:
当学习算法处于高方差时,使用更多的训练数据,对改进算法是有帮助的,验证误差会逐渐变小,但是验证误差往往会始终大于训练误差。
总结,对一个算法进行改进,针对不同情况的方法如下图:

通常来说,使用一个大型的神经网络,并使用正则化来修正过拟合问题,比使用一个小型的神经网络效果更好.
误差分析:
推荐在交叉验证集上做误差分析,总结:在研究一个新的机器学习问题时,推荐快速实现一个简单尽管效果不一定好的算法
不对称分类的误差评估:
对于倾斜分类的情况,使用查准率和召回率来评价学习算法比使用分类误差或者分类准确率好得多,因此如果一个分类算法拥有较高的查准率和召回率,我们可以确信这个算法表现很好。

案例:癌症分类检测——实际数据中,阳性非常少,因此99%的准确率并不能说明这个分类模型质量好。因此需要使用查准率和召回率来进行模型质量的判定。
阳性:1,阴性:0
查准率 = 预测的真阳性 / 所有预测为阳性的数量
召回率 = 预测的真阳性 / 实际为阳性的数量

得到不同的查准率和召回率可以通过修改逻辑回归的阈值
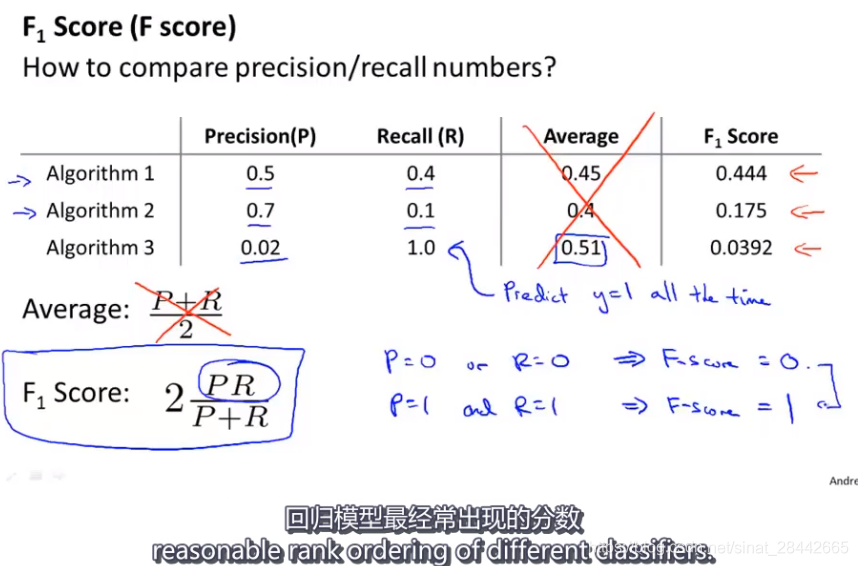
权衡查准率和召回率的适用的计算方法如上图 F 值的计算
自动选取临界值的方法为:尝试不同的临界值在交叉验证集上得到最高的F值

对于一些领域来说,拥有更多的训练数据,模型质量效果(泛化能力)往往能够得到提升
文章来源: positive.blog.csdn.net,作者:墨理学AI,版权归原作者所有,如需转载,请联系作者。
原文链接:positive.blog.csdn.net/article/details/89853845

- 点赞
- 收藏
- 关注作者
评论(0)