吴恩达老师机器学习笔记(七:推荐系统)

第17章节——推荐系统
问题规划: ——电影推荐系统的案例
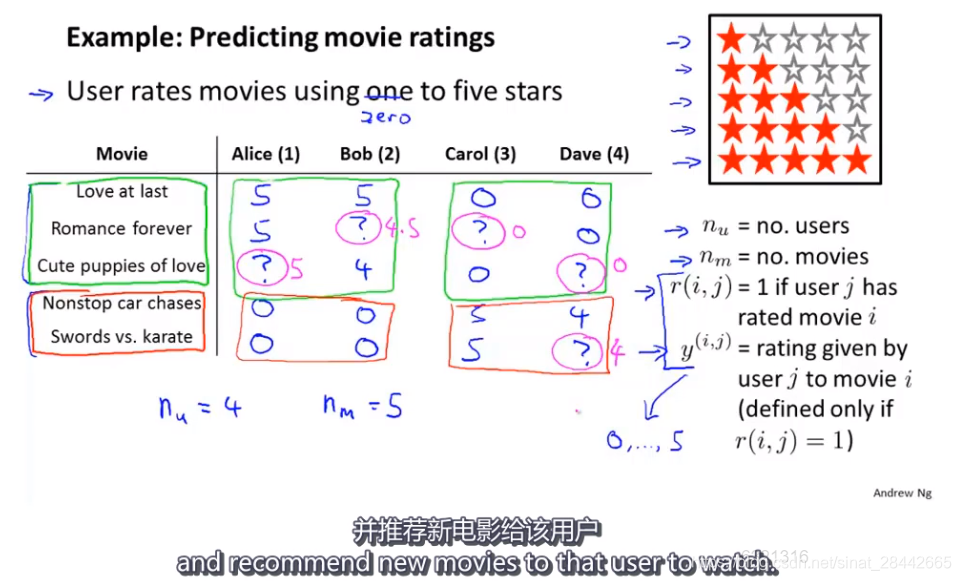
基于内容的推荐算法:
如上图,预测用户对某个电影可能的 评分 情况, 即最小化 预测值 与 实际评分 之间的 差值的 平方 和,y代表实际 值,给出的优化目标函数如下:

协同过滤算法:
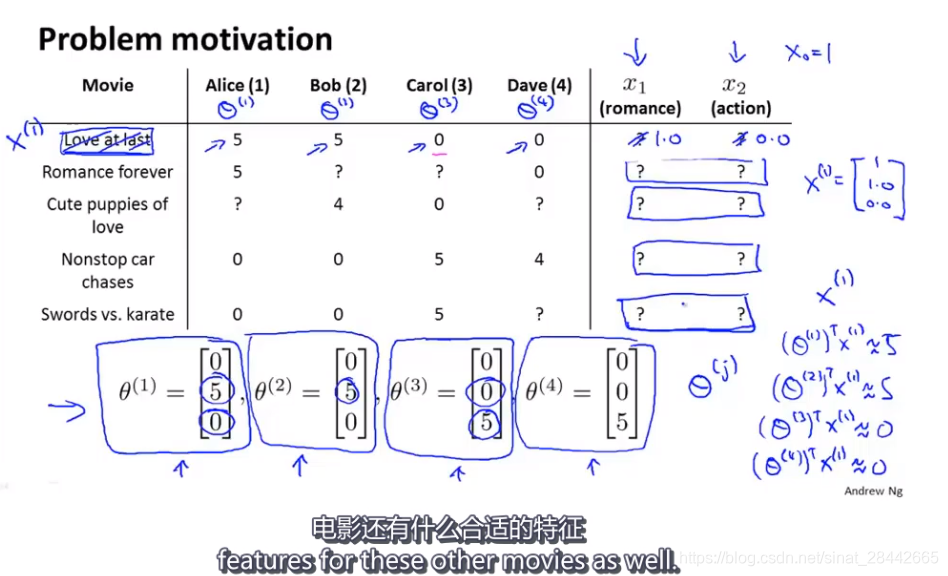
上面的式子是:学习 电影 i 的特征 Xi , 我们加上一个正则化项,来防止特征值变得太大。 学习所有电影的所有特征的 目标函数如下:

该算法建立在 每位用户都对数个电影进行了评价,并且每部电影都被数位用户评价过的情况下。
基本的协同过滤算法: 算法收敛到一组合理的 电影特征 和 不同用户的参数的估计
协同过滤算法 指的是,当你执行算法时,要观察大量的用户,观察这些用户的实际行为,来协同地得到更好的每个人对电影的评分值,因为如果每个用户都对一部分电影作出了评价,那么每个用户都在帮助算法 学习出更合适特征,这些 学习出来的特征又可以被用来更好地预测 其他 用户的评分。

协同地另一个意思是说:每位用户都在帮助算法,更好地进行特征学习。
随机初始化 参数, 来 学习 不同电影的 特征, 有了特征,可以用 基于内容的推荐 来 预测用户的 评分,然后 更多用户的 评分 又可以用来 得到更好的 参数的 估计,如此迭代 即可 使算法 最终 收敛 到一组 合理的电影 特征,以及一组合理的对不同用户的参数的估计。 这就是基本的协同过滤算法。
改进的协同过滤算法: 把 电影特征找到用户对新电影的评分(参数),也可以由电影的评分估计电影的特征 , 可以将 特征 和 参数 同时计算出来,


改进的协同过滤算法:
可以同时学习 几乎所有电影的特征 和 所有用户参数,能对不同 用户会如何 对他们尚未评分的电影做出评价,给出相当准确的预测
改进的协同过滤算法步骤如下:

低秩矩阵分解:

相似电影推荐:

相似电影推荐:电影的特征向量与电影 i 的特征向量的距离最小。
均值规范化: 作为协同过滤算法的预处理步骤

当用户 5 没有给任何电影打分评价时,我们对其进行预测,最小化目标函数,则 我们将预测 用户5 给所以电影的评分都是 0 ,那么这样的预测是无意义的。
使用均值规范化来 预测 用户5 的初始评分值,方法如下:
如下图,过程分析:
计算每个电影已有评分的平均值为u,矩阵都减去均值,再进行协同过滤,但是预测原数据的评分,需要再加上均值,同理最小化目标函数得到的数值为 0 ,则预测的评分 就是 0 加上 均值,即该电影已有评分的平均值作为该用户评分的初始值预测值。

文章来源: positive.blog.csdn.net,作者:墨理学AI,版权归原作者所有,如需转载,请联系作者。
原文链接:positive.blog.csdn.net/article/details/94461048

- 点赞
- 收藏
- 关注作者
评论(0)