机器学习算法源码全解析(三)-范数规则化之核范数与规则项参数选择

【摘要】
前言
参见上一篇博文,我们聊到了L0,L1和L2范数,这篇我们絮叨絮叨下核范数和规则项参数选择。知识有限,以下都是我一些浅显的看法,如果理解存在错误,希望大家不吝指正。谢谢。
机器学习算法源码全解析(二)-范数规则化之L0、L1与L2范数
https://wenyusuran.blog.csdn.net/article/detai...
前言
参见上一篇博文,我们聊到了L0,L1和L2范数,这篇我们絮叨絮叨下核范数和规则项参数选择。知识有限,以下都是我一些浅显的看法,如果理解存在错误,希望大家不吝指正。谢谢。
机器学习算法源码全解析(二)-范数规则化之L0、L1与L2范数
https://wenyusuran.blog.csdn.net/article/details/25868893
三、核范数
核范数||W||*是指矩阵奇异值的和,英文称呼叫Nuclear Norm。这个相对于上面火热的L1和L2来说,可能大家就会陌生点。那它是干嘛用的呢?霸气登场:约束Low-Rank(低秩)。OK,OK,那我们得知道Low-Rank是啥?用来干啥的?
我们先来回忆下线性代数里面“秩”到底是啥?举个简单的例子吧:
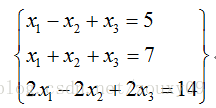
对上面的线性方程组,第一个方程和第二个方程有不同的解,而第2个方程和第3个方程的解完全相同。从这个意义上说,第3个方程是“多余”的,因为它没有带来任何的信
文章来源: wenyusuran.blog.csdn.net,作者:文宇肃然,版权归原作者所有,如需转载,请联系作者。
原文链接:wenyusuran.blog.csdn.net/article/details/25868737

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)