python介绍函数

什么是函数
函数可以看做是一个容器,它吧可执行的命令通过一定格式包裹起来,再起个名字。如果有程序调用这个函数的时候,就会触发执行函数中的代码块。
两个概念:
- 面向过程式编程:根据业务逻辑从上到下实现功能,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,也就是将之前实现的代码块复制到现需功能处
- 面向函数式编程:执行多次重复操作的时候,可以用到函数式编程,可以减少代码重复率
定义函数格式:
-
def 函数名(参数):
-
函数体
-
return()
函数定义要点:
- def:表示函数的关键字
- 函数名:函数的名称,日后根据函数名调用函数
- 函数体:函数中进行一系列的逻辑计算,如:发送邮件,计算出[11,22,38,888,2]中的最大数等….
- 参数:为函数体提供数据
- 返回值:为函数执行完毕后,可以调用者返回数据。
执行函数:
函数名() #括号内不加内容的话只执行没有参数的函数。
函数名(a, b) #如果括号内有参数,则执行有参数的函数
例:
-
def sam(形参):
-
for i in range(1, 100, 2):
-
print(i)
-
return("dsa")
-
-
a = sam(实参)
函数的返回值:return
在函数中如果执行return了,函数下的代码就不再执行了
函数是个功能块,该功能块到底执行成功与否,需要通过返回值来告知调用者。,这个返回值可以定义为任意代码,默认的返回值为None。
-
def sam():
-
for i in range(1, 100, 2):
-
print(i)
-
return("bac")
-
-
a = sam()
-
print(a)
函数的参数:
-
def door(name2): #上面这个参数叫形式参数
-
if name2 == "eric":
-
print("开门")
-
return 1
-
else:
-
print("不开")
-
return 0
-
num = 0
-
while True:
-
name = input("请输入用户名:")
-
fh = door(name) #这个参数叫实际参数
-
num += 1
-
if fh == True:
-
print("eric开门"+str(num)+"次" )
函数可以上传参数,可以把参数作为判断条件,参数可以是多个。
参数分类
普通参数
-
def fc(a, b, c,):
-
函数体
-
return
-
-
fc(1, 2, 3,)
默认,实参与形参的位置是相互对应,数量一致。
-
def fc(a, b, c,):
-
函数体
-
return
-
-
fc(b=2, a=1, c=3,)
也可以指定参数位置,这样就不用按顺序排列位置了。
默认参数
-
def fc(a, b, c=3): #添加默认函数时直接在形参后面添加函数
-
函数体
-
return
-
-
fc(b=2, a=1, c=5) #如果默认函数位被指定函数后,就会使用指定了的函数
注意:
默认参数必须在形参的最后一个
形参里面有几个参数,实参中也要有上传几个参数,即使没用。
动态参数一
把参数变成元组,根据顺序一个一个写入参数,动态参数可以用一个形式参数表示多个不同类型的实际参数。
-
def fc(*a): #配置动态参数只需在参数前面加一个星号“*”
-
print(a, type(a))
-
return
-
-
fc("adfa", 123)
动态参数二
把参数变成字典,需要输入键值对。
-
def fc(**a):
-
print(a, type(a))
-
return
-
-
fc(kaf="daf", dak="alfd")
各种参数也可以组合起来使用,我们把这种参数称之为万能参数。
-
def fc(a, *b, **c): #一个星的在前面,两个星的在后面
-
print(a, type(a))
-
print(b, type(b))
-
print(c, type(c))
-
-
fc(12,14,15,k1=123,k2="bdc")
-
-
12 <class 'int'>
-
(14, 15) <class 'tuple'>
-
{'k1': 123, 'k2': 'bdc'} <class 'dict'>
向函数中传入,列表,元组。
-
def fc(*a): #这里用带一个星号的形参就可以了
-
print(a, type(a))
-
-
li = [22, 33, 44,]
-
tup = (1, 3, 5,)
-
fc(*li, *tup) #传入变量名前面必须加星号
-
-
(22, 33, 44, 1, 3, 5) <class 'tuple'>
这样传入的列表不会把整个列表作为元素
传入字典
-
def fc(**a): #这里要用两个星号的形参
-
print(a, type(a))
-
-
dic = {"k1":"adf","k2":123}
-
fc(**dic) #实参也要用两个星号
-
-
{'k1': 'adf', 'k2': 123} <class 'dict'>
局部变量和全局变量
局部:一段语句,一段功能模块,或者某个用户的环境下
局部变量:在局部环境创建的变量,只能在局部调用,修改。
全局变量:将变量定义在代码语句外,所有语句调用都可用。
在局部环境改变全局变量需要用globle,globle 变量名
规范:全局变量名用大写,局部变量名用小写。 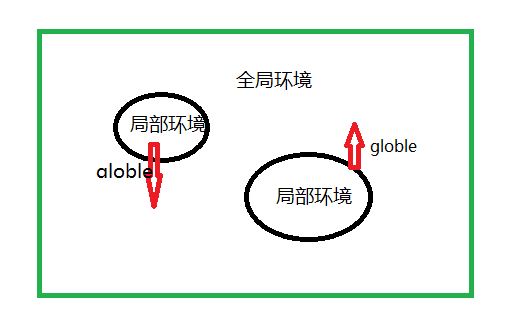
lambda表达式
简单if语句可以用三元运算表示,简单函数也可以用lambda表达式表示。
格式:
-
变量名 = lambda 参数,参数 : 函数体(含返回值)
-
-
例子:
-
f4 = lambda a1,a2 : a1+a2
-
d = f4(1,5)
-
print(d)
内置函数

-
abs #取绝对值
-
all #每个元素都为真则为真
-
0,None,空列表,空字符串,空字典和空元组都是假的,其他的都是真的。
-
any #真要有一个人则为真
-
ascii() #在对象类型中找 __repr__,获取其返回值
-
bool #对象转换成布尔值
-
bytes #字节
-
bytearray #字节列表
-
bytes("alilang", encoding="utf-8") 把字符转换成字节
-
chr() #接受数字把这个数字代表的字符表示出来,默认使用ascii 显示:chr(112)
-
ord() #得出字符用什么十进制的数字表示,一次只能接受一个参数,默认使用ascii编码显示:ord("A")
-
compile #把字符串编译成可执行代码
-
dir #寻找类里面提供的方法
-
dict #字典
-
divmod(10,3) #取整数和余数
-
enumrate() #为可迭代的对象添加序号
-
eval("1+2") #自动把str格式转换成int运算返回格式为int,有返回值
-
exec() #执行py代码,没有返回值
-
-
filter #过滤,循环可迭代的对象,获取每一个参数,函数(参数)
-
用法:
-
def f1(x):
-
if x > 22:
-
return True
-
else:
-
return False
-
-
ret = filter(f1, [11,22,33,44])
-
for i in ret:
-
print(i)
-
-
通过lambda表达式也可以达到同样的作用
-
def f1(x):
-
return x > 22
-
ret = filter(lambda x: x > 22, [11,22,33,44])
-
for i in ret:
-
print(i)
-
-
map() #map与filter函数用法差不多,作用是对每一个可迭代的对象加上指定的书。
-
globals() #获取当前代码中的所有全局变量
-
locals() #获取当前代码中所有的局部变量
-
help() #查看帮助文档
-
id() #查看代码在内存的id号
-
input #将输入的内容赋值给一个变量
-
isinstance() #判断某个对象是否是某个类创建的
-
issubclass() #判断对象是否为子类
-
iter() #创建可迭代对象的next
-
next() #取下一个对象,取的时候要增加next
-
len() #取对象长度
-
list() #列表
-
max() #取对象中的最大值
-
min() #取对象中的最小值
-
pow() #求多少幂:i = pow(2, 10)
-
reversed() #反转
-
round() #四舍五入
-
slice() #取对象的索引
-
sorted() #排序
-
sum() #求和
-
zip() #不同列里相同索引的对象组成同一个元组
-
_import_ #带入模块
-
-
十进制转不同进制的数,在参数内输入十进制数
-
bin() 二进制
-
hex() 十六进制
-
oct() 八进制
-
int() 十进制
-
不同进制的数转十进制,这是一种方式
-
num = int("0b11", base=2) 二进制转十进制
-
num = int("0o11", base=8) 八进制转十进制
-
num = int("0xea", base=16) 十六进制转十进制
-
-
排序:sorted()
-
排序只能排列统一的数据类型
-
p = [1,11,88,2,10,66]
-
print(sorted(p))
-
[1, 2, 10, 11, 66, 88] #数字排序从小到大安数字的大小排序
-
a = ["3","1","?","张","fd","何"]
-
print(sorted(a))
-
['1', '3', '?', 'fd', '何', '张'] #字符排序,按照字符用十进制数表现的大小排序
文件操作:open
- 打开文件
- 操作文件
- 关闭文件
基本模式
open(文件名, 模式, 编码)
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。用什么模式打开文件,就只能对文件做哪些操作
模式
r 只读模式(默认)
w 只写模式(不可读,不存在则创建,存在则清空内容重新创建)
x 只写模式(也不可读,存不存在则创建,存在则报错)
a 追加模式(不可读,不存在则创建,存在则只追加内容)
- 只读模式
-
file = open('sha.txt','r') #文件名可以为是个路径,默认为只读模式
-
r = file.read() #打开文件
-
print(r)
-
file.close() #关闭
- 只写模式
-
file1 = open('ben.txt', 'w')
-
a = file1.write('adixw123') #文件存在则覆盖原有内容,文件不存在则创建
-
file1.close()
- x 只写模式
-
file2 = open('sha1.txt', 'x') #文件存在则报错,不存在则创建
-
file2.write("999999")
-
file2.close()
- a 追加模式
-
file3 = open('ben.txt', 'ra') #追加模式不可读
-
file3.write("aa445")
-
file3.close()
“b”表示以字节的方式操作
直接用二进制方式打开,打开不用转码
- rb 或 r+b
- wb 或 w + b
- xb 或 w + b
-
ab 或 a + b
-
rb,以二进制方式打开
rb:读的时候是以字节的形式读取的,写入的时候也要通过二进制的方式写入。
-
file = open('ben.txt', 'rb',)
-
a = file.read()
-
file.close()
-
print(str(a, encoding="utf-8")) #用utf-8格式,把输出的二进制转成字符显示
- wb;xb;ab 三种写入方式格式类似
-
file = open('ben.txt', 'rb',)
-
a = file.write(bytes("中国", encoding="utf-8"))
-
file.close()
”+“表示可以同时读写某个文件
- r+ 读写(在末尾追加)
- w+ 写读
- x+ 写读
- a+ 写读
- tell() #获取指针位置
-
seek() #改变指针位置
-
r+ :读写,先写再读
-
file = open('ben.txt', 'r+', encoding=('utf-8')) #win默认用gdk格式,linux默认用utf-8格式
-
d = file.read(1) #指定读取一个字符
-
print(file.tell())
-
print(d)
-
-
#file.write("中华")
-
a = file.read(2) #指定读取两个字符
-
file.write("花花") #写入时指针就到了最后一位
-
print(file.tell())
-
file.close()
-
print(a)
- w+ :读写,先清空,写完以后才能读
-
file = open('ben.txt', 'w+', encoding='utf-8')
-
file.write("中华")
-
file.seek(0) #写入以后指针会到最后一位,seek可以改变指针位置
-
a = file.read()
-
file.close()
-
print(a)
-
x+:与读写格式基本相同,有一点不同如果文件存在则报错
-
a+:与上面的读写差不多,可以追加数据
-
file = open("ben.txt", "a+", encoding="utf-8")
-
file.write("人民")
-
file.seek(0)
-
d = file.read()
-
file.close()
-
print(d)
总结:r+:从后向后读;w+:先清空写完之后指针在最后;x+:如果没有文件存在则报错;a+:追加,写完之后指针在最后。
对文件进行操作
-
def close(self, *args, **kwargs): #real signature unknown 关闭文件
-
pass
-
def fileno(self, *args, **kwargs): #real signature unknown 文件描述符
-
pass
-
def flush(self, *args, **kwargs): 将内存的文件信息写入硬盘
-
-
#def isatty(self, *args, **kwargs): 判断文件是否同意tty设备
-
-
def read(self, *args, **kwargs): 读取指定字符数据
-
-
#def readable(self, *args, **kwargs): 是否可读
-
-
def readline(self, *args, **kwargs): 仅读取一行数据
-
-
def seek(self, *args, **kwargs): 指定文件中指针位置
-
-
#def seekable(self, **args, **kwargs): 指针是否可操作
-
-
def truncate(self, *args, **kwargs): 截取数据,仅保留指针之前的数据,依赖于指针
-
-
#def writable(self, *args, **kwargs): 是否可写
-
-
def write(self, *args, **kwargs): 写内容
读取所有的数据(无论几行几列)
-
f1 = open("ben.txt", "r+", encoding="utf-8")
-
for line in f1:
-
print(line)
自动写入:with
每次打开一个文件都需要close才能进行下一步操作,如果用上with之后就可以不用每次都关闭了。
格式:
-
with open("ben.txt", "r", "#") as file:
-
file.read()
-
......
Python2.7之后,with同时打开两个文件
-
with open("ben.txt", "r") as file1, open("sha.txt", "r") as file2
-
......
实例:
同时打开两个文件file1的数据复制到file2文件里面,可以进行一下操作。
-
with open("ben.txt", "r+", encoding="utf-8") as file1, open("sha.txt", "w+", encoding="utf-8") as file2:
-
for line in file1:
-
file2.write(line)
-
file2.seek(0)
-
a = file2.read()
-
print(a)
转载自:https://blog.csdn.net/ydydyq/article/details/51445510
文章来源: brucelong.blog.csdn.net,作者:Bruce小鬼,版权归原作者所有,如需转载,请联系作者。
原文链接:brucelong.blog.csdn.net/article/details/80266858

- 点赞
- 收藏
- 关注作者
评论(0)