增强学习(三)----- MDP的动态规划解法

【摘要】
上一篇我们已经说到了,增强学习的目的就是求解马尔可夫决策过程(MDP)的最优策略,使其在任意初始状态下,都能获得最大的Vπ值。(本文不考虑非马尔可夫环境和不完全可观测马尔可夫决策过程(POMDP)中的增强学习)。
那么如何求解最优策略呢?基本的解法有三种:
动态规划法(dynamic programming meth...
上一篇我们已经说到了,增强学习的目的就是求解马尔可夫决策过程(MDP)的最优策略,使其在任意初始状态下,都能获得最大的Vπ值。(本文不考虑非马尔可夫环境和不完全可观测马尔可夫决策过程(POMDP)中的增强学习)。
那么如何求解最优策略呢?基本的解法有三种:
动态规划法(dynamic programming methods)
蒙特卡罗方法(Monte Carlo methods)
时间差分法(temporal difference)。
动态规划法是其中最基本的算法,也是理解后续算法的基础,因此本文先介绍动态规划法求解MDP。本文假设拥有MDP模型M=(S, A, Psa, R)的完整知识。
1. 贝尔曼方程(Bellman Equation)
上一篇我们得到了Vπ和Qπ的表达式,并且写成了如下的形式
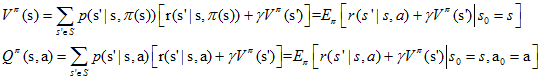
在动态规划中,上面两个式子称为贝尔曼方程,它表明了当前状态的值函数与下个状态的值函数的关系。
优化目标π*可以表示为: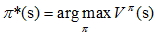
分别记最优策略π*对应的状态值函数和行为值函数为V*(s)和Q*(s, a),由它们的定义容易知道,V*(s)和Q*(s, a)存在如下关系: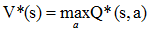
状态值函
文章来源: wenyusuran.blog.csdn.net,作者:文宇肃然,版权归原作者所有,如需转载,请联系作者。
原文链接:wenyusuran.blog.csdn.net/article/details/85760953

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)