Spark案例:Python版统计单词个数

【摘要】
1、Python项目PythonSparkWordCount
2、input目录里的文本文件test.txt
3、创建word_count.py文件实现词频统计
import osimport shutil from pyspark import SparkContext inputpath = 'input'output...
1、Python项目PythonSparkWordCount
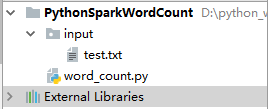
2、input目录里的文本文件test.txt

3、创建word_count.py文件实现词频统计
-
import os
-
import shutil
-
-
from pyspark import SparkContext
-
-
inputpath = 'input'
-
outputpath = 'result'
-
-
sc = SparkContext('local', 'wordcount')
-
-
# 读取文件
-
input = sc.textFile(inputpath)
-
# 切分单词
-
words = input.flatMap(lambda line: line.split(' '))
-
# 转换成键值对并计数
-
counts = words.map(lambda word: (word, 1)).reduceByKey(lambda x, y: x + y)
-
-
# 输出结果
-
counts.foreach(print)
-
-
# 删除输出目录
-
if os.path.exists(outputpath):
-
shutil.rmtree(outputpath, True)
-
-
# 将统计结果写入结果文件
-
counts.saveAsTextFile(outputpath)
运行程序,结果如下:
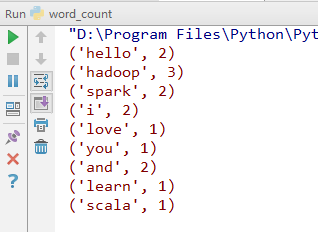
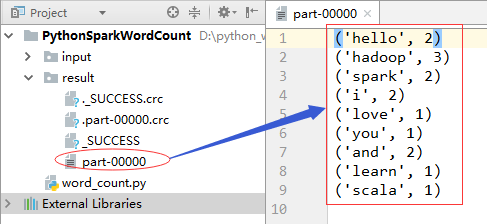
统计结果还保存在result目录下的part-00000文件里:
文章来源: howard2005.blog.csdn.net,作者:howard2005,版权归原作者所有,如需转载,请联系作者。
原文链接:howard2005.blog.csdn.net/article/details/79331562

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)