解读MySQL 8.0新特性:Skip Scan Range

MySQL从8.0.13版本开始支持一种新的range scan方式,称为Loose Skip Scan。该特性由Facebook贡献。我们知道在之前的版本中,如果要使用到索引进行扫描,条件必须满足索引前缀列,比如索引idx(col1,col2), 如果where条件只包含col2的话,是无法有效的使用idx的, 它需要扫描索引上所有的行,然后再根据col2上的条件过滤。
新的优化可以避免全量索引扫描,而是根据每个col1上的值+col2上的条件,启动多次range scan。每次range scan根据构建的key值直接在索引上定位,直接忽略了那些不满足条件的记录。
示例
下例是从官方文档上摘取的例子:
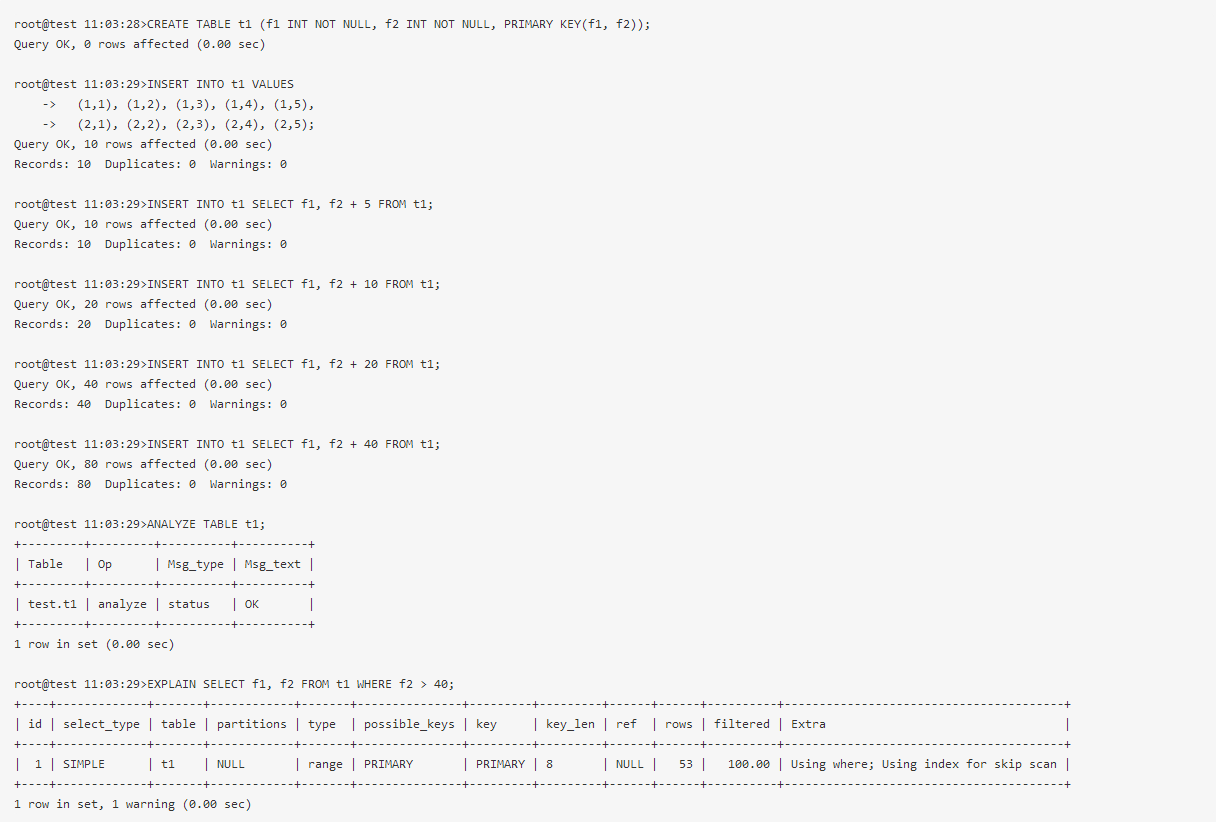
也可以从optimizer trace里看到如何选择的skip scan:

我们从innodb的角度来看看这个SQL是如何执行的,我们知道每个index scan都会走到ha_innobase::index_read来构建search tuple,上述查询的执行步骤:
- 第一次从Index left side开始scan
- 第二次使用key(1,40) 扫描index,直到第一个range结束
- 使用key(1), find_flag =HA_READ_AFTER_KEY, 找到下一个Key值2
- 使用key(2,40),扫描Index, 直到range结束
- 使用Key(2),去找大于2的key值,上例中没有,因此结束扫描
代码注入了日志,打印search_tuple(dtuple_print())

从上述描述可以看到使用skip-scan的方式避免了全索引扫描,从而提升了性能,尤其是在索引前缀列区分度比较低的时候
条件
skip scan可以通过Hint或者optimizer_switch来控制(skip_scan),默认是打开的。根据worklog的描述,对于如下query:

需要满足如下条件才能使用skip scan:
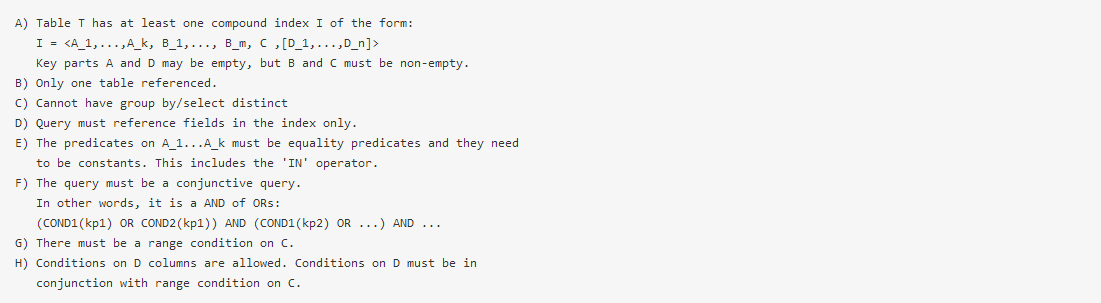
ref: get_best_skip_scan()
当skip scan拥有更低的cost时,会被选择,计算cost的函数是cost_skip_scan(),由于索引统计信息中已经基于不同的前缀列值估算了distinct value的个数(rec_per_key), 可以基于此去预估可能需要读的行数。 更具体的可以参考wl#11322中的描述,笔者对此不甚了解,故不做笔墨ref: cost_skip_scan()
文章来源: aaaedu.blog.csdn.net,作者:tea_year,版权归原作者所有,如需转载,请联系作者。
原文链接:aaaedu.blog.csdn.net/article/details/89810283

- 点赞
- 收藏
- 关注作者
评论(0)