读书笔记:《亿级流量网站架构核心技术 -- 跟开涛学搭建高可用高并发系统》

from 《亿级流量网站架构核心技术 – 跟开涛学搭建高可用高并发系统》
概述
一个好的设计要做到,解决现有的需求和问题,把控实现和进度风险,预测和规划未来,不要过度设计,从迭代中演进和完善。
在设计系统时,应多思考墨菲定律:
1、任何事情都没有表面看起来那么简单。
2、所有的事都会比你预计的时间长。
3、可能出错的事总会出错。
在系统划分时,也要思考康威定律:
1、系统架构是公司组织架构的反映。
2、应该按照业务闭环进行系统拆分/组织架构划分,实现闭环/高内聚/松耦合,减少沟通成本。
3、如果沟通出现问题,那么就应该考虑进行系统和组织架构的调整。
4、在合适的时机进行系统拆分,不要一开始就把系统/服务拆的非常细,虽然闭环,但是维护成本高。
高并发原则
1、无状态。应用无状态,配置文件有状态。(可以用在我的毕设指导里)
你可以轻易修改配置文件,但是应用发布了,就是发布了。
2、拆分。在系统设计初期,是做一个大而全的系统,还是按功能模块拆分系统,这个需要根据环境进行权衡。
有很多维度可以考虑,比方说:系统维度、功能维度、读写维度、and so on。
我jio的吧,有资源就拆,不然就先憋着吧。
3、服务化(不知道怎么概括那段话,经验不足)
4、消息队列。基本概念就不说啦。使用消息队列时,还要注意处理生产消息失败,以及消息重复接收时的场景。对于不能容忍生产失败的业务场景来说,一定要做好后续的数据处理工作。对于消息重复的问题,特别是一些分布式消息队列,处于对性能和开销的考虑,在一些场景下会发生消息重复接收,需要在业务层面进行防重处理。
大流量缓冲:
扣减库存设计(正打算这样干)
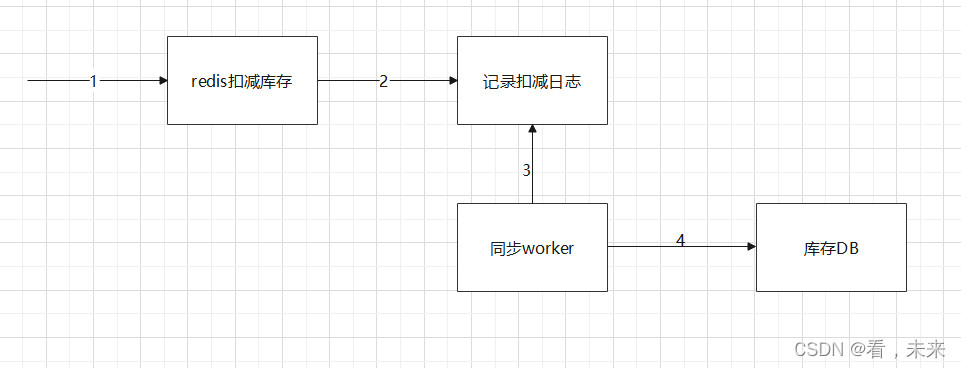
订单交易系统

数据校对:
在使用了消息异步机制的场景下,可能存在消息的丢失,需要考虑进行数据校对和修正来保证数据的一致性和完整性。可以通过扫描原始表,通过对业务数据进行校对,有问题的要进行补偿,扫描周期根据实际场景进行定义。
5、数据异构与数据闭环
6、缓存银弹
浏览器缓存、APP客户端缓存、CDN缓存、接入层缓存、应用层缓存、分布式缓存
7、并发化
高可用原则
1、降级(在我的毕设后续版本迭代中会出现,不过之前不是很明朗具体要怎么做)。
对于高可用服务,很重要的一个设计就是降级开关。
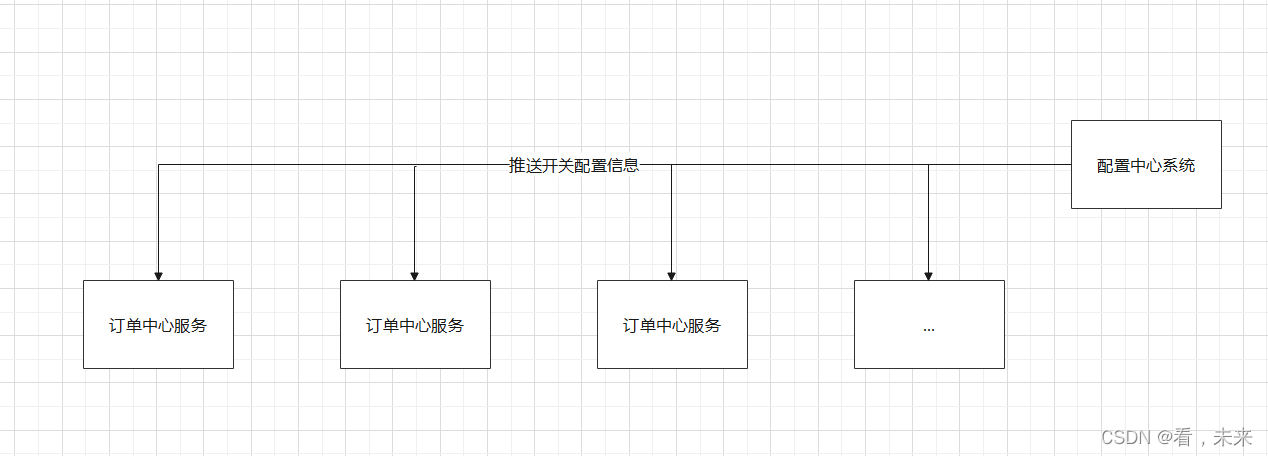
2、限流(这个也知道要做,也知道要用什么做,但是目前也是不知道要怎么做,还没去研究)
1、对于恶意请求流量只访问到cache
2、对于穿透到后端应用的流量可以考虑使用 Nginx 的 limit 模块处理
3、对于恶意 IP 可以使用 nginx deny 进行屏蔽
不过要怎么区分恶意流量呢?是在一定的时间内请求过于频繁吗?或者是爬虫?或者二者都是,加上一些其他的未知的。
那就反过来看,只放过善意流量。
3、切流量
这个目前我会用 nginx 做故障服务器下线,切换备胎上线。
4、可回滚
业务设计原则
防重设计(流水号 + 滑窗)、幂等设计、流程可定义(模板方法模式)、状态与状态机(待付款、待发货、已发货、完成)(取消、退款)等,要考虑是否要使用状态机来驱动状态的变更和后续流程节点操作,尤其是当状态很多的时候。还要考虑并发下的状态修改问题。
文档和注释
在一个系统发展的一开始就应该有文档库(设计架构、设计思想、数据字典、业务流程、现有问题),业务代码和特殊需求都要有注释、
包括代码和人员都应该有备份。
代码备份就不用多说了。人员备份可以参考一下结对编程。既能提高效率,而且即使其中一名离职了也不会出现新人接收之后手忙脚乱事故频发的状况。
隔离术
线程池隔离
进程隔离
集群隔离
机房隔离
读写隔离
动静隔离
爬虫隔离
热点隔离
资源隔离
工具:
Hystrix
servlet3
这些目前先知道,要系统学习之后才能使用
限流术
在压测时我们可以找出每个系统的处理峰值,然后通过设定峰值阈值,来防止当系统过载时,通过拒绝处理过载的请求来保障系统可用。
限流需要评估好,不然会导致正常的流量出现异常,被用户投诉。
限流算法
常见的限流算法有:令牌桶。漏桶。计数器也可以用来进行简单粗暴限流实现。
令牌桶算法
存放固定容量令牌的桶,按照固定的速率往桶里添加令牌。
1、按照一定速率往桶里添加令牌。
2、桶里最多放m个令牌。
3、当一个n个字节大小的数据包到达,将从桶中删除n个令牌,接着数据包被发送到网络上。
4、如果桶中的令牌不足n个,则不会删除令牌,该数据包要么丢弃,要么在缓冲区等待。
漏桶算法
1、一个固定容量的漏桶,按照常量速率流出水滴。
2、如果桶是空的,则不需流出水滴。
3、可以以任意速率流入水滴到漏桶。
4、如果流入的水滴超出了桶的容量,则流入的水滴溢出(被丢弃),而漏桶容量不变。
应用级限流
1、限制 总并发/连接/请求数
对于一个应用系统来说,一定会有极限并发/请求数。如果超了阈值,则系统就会不响应用户请求或响应的非常慢,因此我们最好进行过载保护,以防止大量请求涌入击垮系统。
2、限流总资源数
3、限流某个接口的总并发/请求数
4、限流某个接口的时间窗请求数
5、平滑限流某个接口的请求数(令牌桶和漏桶)
分布式限流
redis + lua
local key = KEY[1] --限流 KEY
local limit = tonumber(ARGV[1]) --限流大小
local current = tonumber(redis.call('get',key) or "0") --请求数加1
if current+1 > limit then --超出限流大小
return 0
else then --请求数+1,并设置2秒过期
redis,call("INCRBY",key,"1")
redis.call("expire",key,"2")
return 1
end
Java中判断是否需要限流的代码:
public static boolean acquire() throws Exception{
string luaScript = Files.toString(new File("limit.lua"),Charset,defaultCharset());
Jedis jedis = new Jedis("127.0.0.1",6379);
String key = "ip:" + System.currentTimeMillis()/1000;
String limit = "3";
return (long)jedis.eval(luaScript,Lists.newArrayList(key),Lists.newArrayList(limit))
}
nginx + lua 实现
local locks = require "resty.lock"
local function acquire()
local lock = locks:new("locks")
local elapsed,err = lock:lock("limit_key") --互斥锁,实际使用的时候要考虑获取锁的超时问题
local limit_counter = ngx.shared.limit_counter --计数器
local key = "ip:" ..os.time()
local limit = 5 -- 限流大小
local current = limit_counter:get(key)
if current ~= nil and current + 1 > limit then --如果超出限流大小
lock:unlock()
return 0
end
if current == nil then
limit_counter:set(key,1,1) --第一次需要设置过期时间,设置key值为1,过期时间为1秒
else
limit_counter:incr(key,1) --第二次开始加1
end
lock:unlock()
return 1
end
ngx.print(acquire())
使用时需要定义两个共享字典:
http{
···
lua_shared_dict locks 10m;
lua_shared_dict limit_counter 10m;
}
接入层限流
接入层通常指流量的入口,该层的主要目的有:负载均衡、非法请求过滤、请求聚合、缓存、降级、限流、A/B测试、服务质量监控等。
这个在我的毕设后面的版本需要系统学习nginx的时候会补充。目前强行看用处没那么大。
超时与重试机制
在实际开发过程中,有太多故障是因为没有设置超时或者设置的不对而造成的(想想我好像也根本没有把超时当一回事儿过,项目里的Timestamp模块从来就是个摆设)。
如果应用不设置超时,则可能乎导致请求响应慢,慢请求积累导致连锁反应,甚至造成应用雪崩。
对于重试,写服务大多不能重试,重试次数太多会导致多倍请求流量,后果可能是灾难性的。
因此,务必设置合理的重试机制,并且应该和熔断、快速失败机制配合。
压测与预案
读了《重构》之后,我就一直在做这件事情。但是自认为没有做的很好、
系统压测
压测之前要有压测方案(如压测接口、并发量、压测策略(突发、逐步加压、并发量)、压测指标(机器负载、QPS/TPS、响应时间)),之后要产出压测报告(压测方案、机器负载、QPS/TPS、响应时间(平均、最小、最大)、成功率、相关参数 等),最后根据压测报告分析的结果进行系统优化和容灾。
线下压测的环境和线上压测完全不一样,仿真度也不高,很难进行全链路压测,适合组件级的压测,数据只能作为参考。
线上压测的方式非常多:读压测、写压测、混合压测、仿真压测、隔离集群压测、单机压测、离散数据压测、全链路压测等。
系统优化
在进行系统优化时,要进行代码走查,发现不合理的参数配置。
在系统压测中进行慢查询排查,包括redis、mysql等。
在应用系统扩容方面,可以根据往年的流量来进行评估是否需要扩容等。
扩容之后还要预留一些机器以应对突发状况,在扩容上尽量支持快速扩容(上云),从而完成出现突发状况可以及时扩容。
做好容灾。

- 点赞
- 收藏
- 关注作者
评论(0)