Mysql基础【sql排序,聚合函数,分组】 --简单应用一目了然

目录
SQL语句操作
1 什么是 SQL
Structured Query Language 结构化查询语言
2 作用
(1) 是一种所有关系型数据库的查询规范,不同的数据库都支持。
(2) 通用的数据库操作语言,可以用在不同的数据库中。
(3) 不同的数据库 SQL 语句有一些区别

分类:
(1) Data Definition Language (DDL 数据定义语言) 如:建库,建表
(2) Data Manipulation Language(DML 数据操纵语言),如:对表中的记录操作增删改
(3) Data Query Language(DQL 数据查询语言),如:对表中的查询操作
(4) Data Control Language(DCL 数据控制语言),如:对用户权限的设置
排序
语法:
SELECT 字段名 FROM 表名 WHERE 字段=值 ORDER BY 字段名 [ASC|DESC];
参数:
ASC: 升序,默认值
DESC: 降序
单列排序:
只按某一个字段进行排序,单列排序。
代码:
SELECT * FROM emp ORDER BY id DESC; -- 按id号进行降序排序
结果:

组合排序:
同时对多个字段进行排序,如果第 1 个字段相等,则按第 2 个字段排序,依次类推。 组合排序的语法:
代码:
SELECT * FROM emp ORDER BY dept_id DESC , id ASC -- 先以dept_id进行降序,同以部门id进行升序
结果:

分组
定义:
分组查询是指使用 GROUP BY 语句对查询信息进行分组,相同数据作为一组
语法:
SELECT 字段 1,字段 2... FROM 表名 GROUP BY 分组字段 [HAVING 条件];
参数:
GROUP BY 分组字段
HAVING 条件
代码:
-
1 SELECT * FROM emp GROUP BY dept_id -- 以部分进行分组
-
2
-
select * from emp Group by dept_id having salary between 1000 and 8000 -- 以部门进行分组,并且工资在1000 -8000之间
结果:


HAVING and where的区别:
where 子句
(1) 对查询结果进行分组前,将不符合 where 条件的行去掉,即在分组之前过滤数据,即先过滤 再分组。
(2) where 后面不可以使用聚合函数
having 子句
(1) having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,即先分组再过滤。
(2) having 后面可以使用聚合函数
聚合函数
sum()
-
-- 查询数学成绩总分
-
select sum(math) 总分 from student;
max()
-
-- 查询数学成绩最高分
-
select max(math) 最高分 from student;
main()
-
-- 查询数学成绩最低分
-
select min(math) 最低分 from student;
avg()
-
-- 查询数学成绩平均分
-
select avg(math) 平均分 from student;
count()
-
-- 查询年龄大于 20 的总数
-
select count(*) from student where age>20;
三大范式
1NF
概念:
数据库表的每一列都是不可分割的原子数据项,不能是集合、数组等非原子数据项。即表中的某个列有多个值 时,必须拆分为不同的列。简而言之,第一范式每一列不可再拆分,称为原子性。
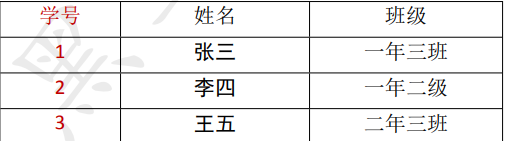
2NF
概念:
在满足第一范式的前提下,表中的每一个字段都完全依赖于主键。 所谓完全依赖是指不能存在仅依赖主键一部分的列。
简而言之,第二范式就是在第一范式的基础上所有列完全 26 / 26 依赖于主键列。
当存在一个复合主键包含多个主键列的时候,才会发生不符合第二范式的情况。
比如有一个主键有 两个列,不能存在这样的属性,它只依赖于其中一个列,这就是不符合第二范式。
第二范式的特点:
1) 一张表只描述一件事情。
2) 表中的每一列都完全依赖于主键
示例:

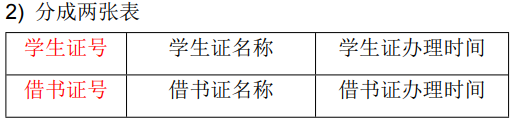
3NF
概念:
在满足第二范式的前提下,表中的每一列都直接依赖于主键,而不是通过其它的列来间接依赖于主键。 简而言之,第三范式就是所有列不依赖于其它非主键列,也就是在满足 2NF 的基础上,任何非主列不得传递 依赖于主键。所谓传递依赖,指的是如果存在"A → B → C"的决定关系,则 C 传递依赖于 A。因此,满足第三范 式的数据库表应该不存在如下依赖关系:主键列 → 非主键列 x → 非主键列 y
示例:学生信息表


![]()
![]()

文章来源: kangshihang.blog.csdn.net,作者:康世行,版权归原作者所有,如需转载,请联系作者。
原文链接:kangshihang.blog.csdn.net/article/details/112242677

- 点赞
- 收藏
- 关注作者
评论(0)