关于 CPU

愿打开此篇对你有所帮助

@[toc]
这不,要做毕设了嘛。之前写的那些项目勉勉强强能跑起来,但是性能方面是没有太在意的,这次准备精打细算一番。看看瓶颈到底都在哪里。
32位CPU && 64位CPU
CPU 看了那么多,我们都知道 CPU 通常分为 32 位和 64 位,你知道 64 位相比 32 位 CPU 的优势在哪吗?64 位 CPU 的计算性能一定比 32 位 CPU 高很多吗?
- 32 位 CPU 一次可以计算 4 个字节;
- 64 位 CPU 一次可以计算 8 个字节;
这里的 32 位和 64 位,通常称为 CPU 的位宽。CPU 位宽越大,可以计算的数值就越大。
这并不代表 64 位 CPU 性能比 32 位 CPU 高很多,很少应用需要算超过 32 位的数字,所以如果计算的数额不超过 32 位数字的情况下,32 位和 64 位 CPU 之间没什么区别的,只有当计算超过 32 位数字的情况下,64 位的优势才能体现出来。
另外,32 位 CPU 最大只能操作 4GB 内存,就算你装了 8 GB 内存条,也没用。而 64 位 CPU 寻址范围则很大,理论最大的寻址空间为 2^64。
CPU Cache && 内存 && 硬盘
认识一下CPU架构:
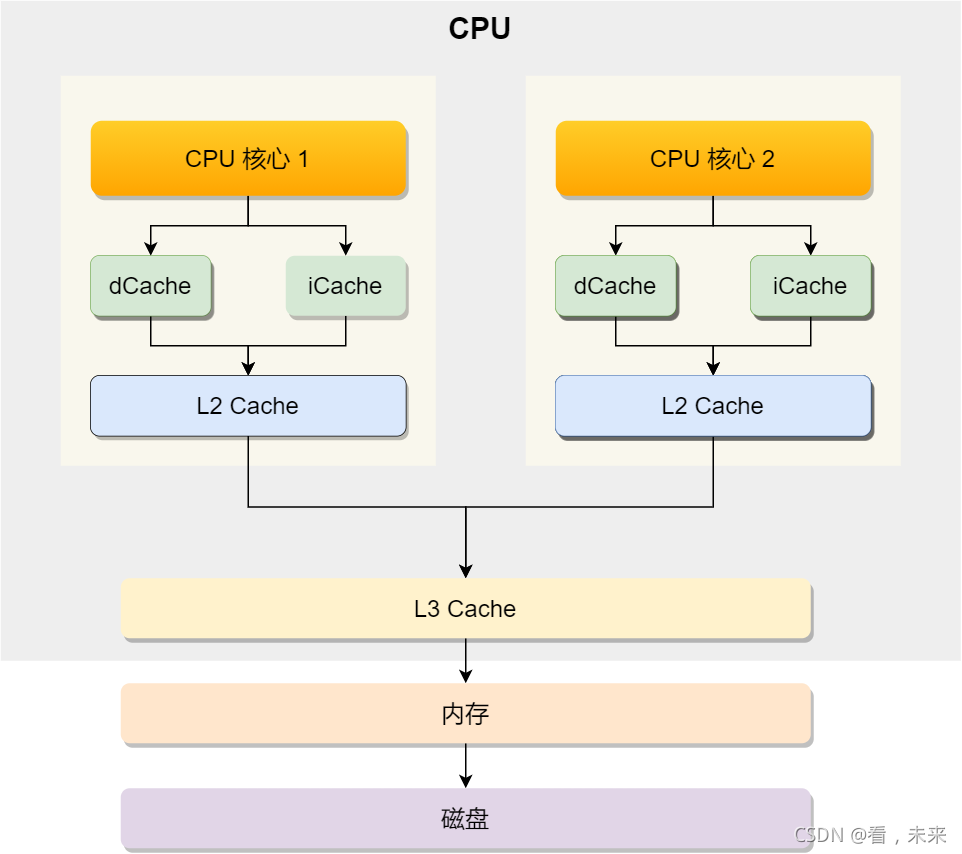
在网上(小林coding)看到这么一张图:
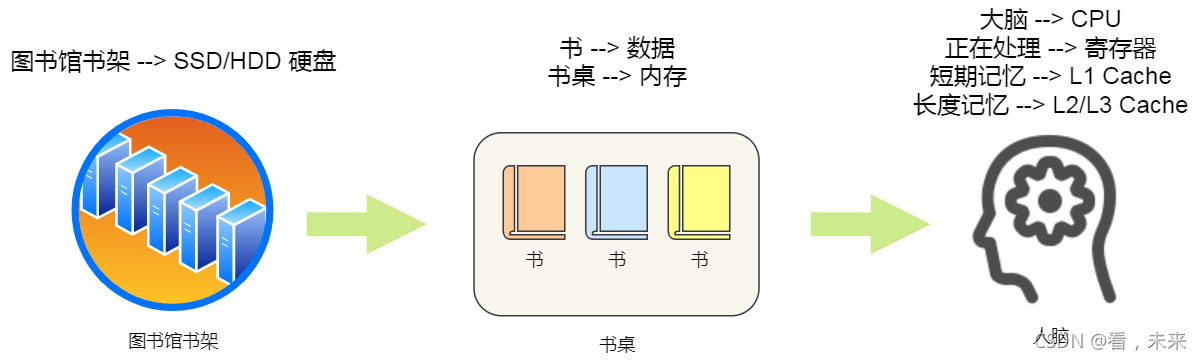
生动形象吧。
曾经一直有个误区,认为redis是和调用进程放在一块儿的,后来才知道,进程存取redis也是要走 IO 的,那时候就不太理解,那 redis 是比MySQL 快在哪里了?我觉得其中有一个重要因素就是 redis 数据在内存里,MySQL 数据在磁盘上吧。
CPU 并不会直接和每一种存储器设备直接打交道,而是每一种存储器设备只和它相邻的存储器设备打交道。
比如,CPU Cache 的数据是从内存加载过来的,写回数据的时候也只写回到内存,CPU Cache 不会直接把数据写到硬盘,也不会直接从
(图片来源网络)
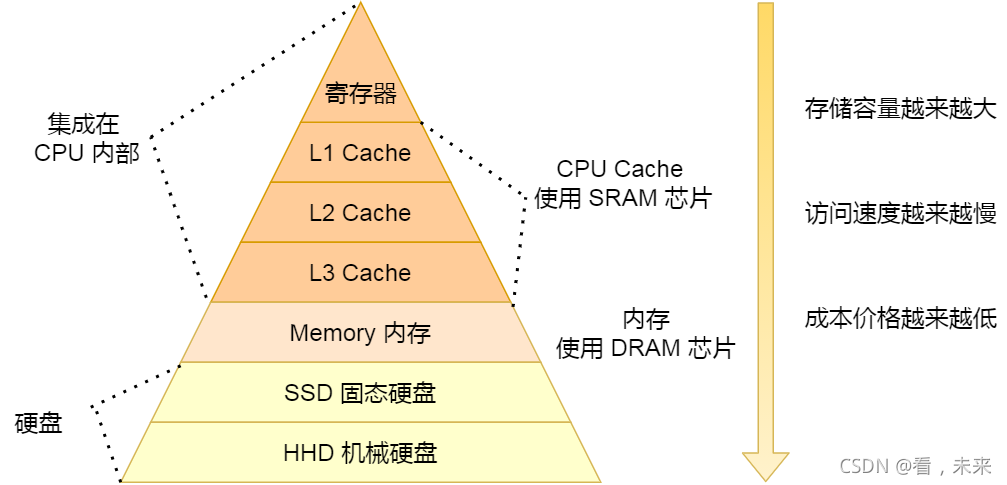
另外,当 CPU 需要访问内存中某个数据的时候,如果寄存器有这个数据,CPU 就直接从寄存器取数据即可,如果寄存器没有这个数据,CPU 就会查询 L1 高速缓存,如果 L1 没有,则查询 L2 高速缓存,L2 还是没有的话就查询 L3 高速缓存,L3 依然没有的话,才去内存中取数据。
(图片依旧来自网络)
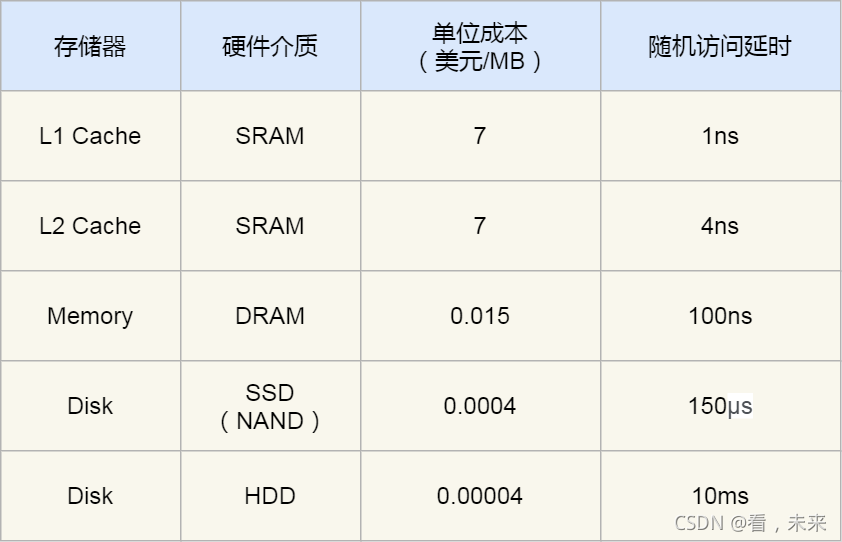
查看 1/2/3 级缓存大小

程序执行时,会先将内存中的数据加载到共享的 L3 Cache 中,再加载到每个核心独有的 L2 Cache,最后进入到最快的 L1 Cache,之后才会被 CPU 读取。
L1 Cache 通常会分为「数据缓存」和「指令缓存」,这意味着数据和指令在 L1 Cache 这一层是分开缓存的。index0是数据缓存,index1是指令缓存。
另外,你也会注意到,L3 Cache 比 L1 Cache 和 L2 Cache 大很多,这是因为 L1 Cache 和 L2 Cache 都是每个 CPU 核心独有的,而 L3 Cache 是多个 CPU 核心共享的。
如何写出让 CPU 跑得更快的代码?
这个问题可以翻译为:如何写出 CPU 缓存命中率高的代码?
那我们需要来看一下什么叫CPU缓存命中(就是要用的数据在CPU缓存里边呗)。
//查看 L1 数据缓存一次载入数据量的大小:
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
剩余的可以自己上网搜一下,无非就是教你怎么排版代码顺序。
按照内存布局顺序访问,将可以有效的利用 CPU Cache 带来的好处,这样我们代码的性能就会得到很大的提升。
太细了,以我现在的认知水平,先记着吧。
如果是多核呢?虽然 L3 Cache 是多核心之间共享的,但是 L1 和 L2 Cache 都是每个核心独有的,如果一个进程在不同核心来回切换,各个核心的缓存命中率就会受到影响,相反如果进程都在同一个核心上执行,那么其数据的 L1 和 L2 Cache 的缓存命中率可以得到有效提高,缓存命中率高就意味着 CPU 可以减少访问 内存的频率。
当有多个同时执行「计算密集型」的线程,为了防止因为切换到不同的核心,而导致缓存命中率下降的问题,我们可以把线程绑定在某一个 CPU 核心上,这样性能可以得到非常可观的提升。
进程绑核函数:sched_setaffinity
线程绑核函数:pthread_setaffinity_np
需要用到的小伙伴自行百度这两个函数,有现成代码拿去测试一下。
这些技巧在计算密集型的时候好用,如果是IO密集型的嘛,哈哈。不如想想SQL语句优化来的实在。

- 点赞
- 收藏
- 关注作者
评论(0)