编译原理实验题

实验一 小型词法分析器的设计
一、实验原理
1、词法分析器
词法分析器的功能输入源程序,按照构词规则分解成一系列单词符号。词法分析是编译过程中的一个阶段,在语法分析前进行。词法分析作为一遍,可以简化设计,改进编译效率,增加编译系统的可移植性。也可以和语法分析结合在一起作为一遍,由语法分析程序调用词法分析程序来获得当前单词供语法分析使用。
2、词法分析器的设计目标
(1)正确性;
(2)可读性;
(3)健壮性;
(4)高时间效率;
(5)高空间效率;
二、实验要求和目的
1、理解符号串的基本特点;
2、理解符号串切割的特点;
3、理解单词符号的特点与基本特点。
三、实验环境
环境不限。
四、作业要求
编写一个程序,对于输入的一段英语文本,可以统计:
(1)该文本中有多少英语单词,并把每个单词都列出来;
(2)该文本中有多少不同的英语单词,并把不同的单词都列出来。
如,输入 I am a good student. I am in Zhengzhou.
则可以统计出有9个英语单词、7个不同的英语单词。
实验二 小型词法分析器的设计
一、实验原理
1、词法分析器
词法分析器的功能输入源程序,按照构词规则分解成一系列单词符号。单词是语言中具有独立意义的最小单位,包括关键字、标识符、运算符、界符和常量等。
(1) 关键字 是由程序语言定义的具有固定意义的标识符。例如,Pascal 中的begin,end,if,while都是保留字。这些字通常不用作一般标识符。
(2) 标识符 用来表示各种名字,如变量名,数组名,过程名等等。
(3) 常数? 常数的类型一般有整型、实型、布尔型、文字型等。
(4) 运算符 如+、-、*、/等等。
(5) 界符? 如逗号、分号、括号、等等。
2、词法分析器设计目标
(1) 正确性
(2) 可读性
(3) 健壮性
(4) 高时间效率
(5) 高空间效率
二、实验要求和目的
1、理解词法分析器的基本原理;
2、能够根据词法分析器的原理设计小型词法分析器,该词法分析器可以获取单词符号并判断符号的类别。
三、实验环境
环境不限。
四、作业要求
1、编写一个词法分析器,对于输入的算术表达式,可以获取该字符串中的所有运算数和运算符。
如,输入25.6 + 1752.9e10 -62^ 3
则要求得到输出如下,
25.6
+
17
*
52.9e10
6
*
2
^
3
2、编写一个词法分析器,对于输入的一段程序,可以获取该程序的单词符号。单词符号的类别有基本字、标识符、常数、算符和界符。关键字为基本字,由字母组成,如int、for和while;变量名和函数名为标识符,由字母和数字构成,如fun1和age;固定不变的数值为常数,如12、13.86和25e8(科学计数法);算符如+、-、、/ 、%、&&;界符如 {、[、(、 ;和:等。
如,若输出源程序如下,
public?static?void?main (String []?args)?{
???double sum5 = 0.0;
for ( int?i=1;i<=5;i++)?{
sum5=sum5+(i+10);
sum5=sum5+(i2);
???}
}
则要求得到输出如下,
public 基本字
static?基本字
void?基本字
main 标识符
( 界符
String基本字
[ 界符
] 界符
args标识符
)? 界符
{ 界符
double基本字
sum5标识符
= 算符
0.0 常数
; 界符
for基本字
( 界符
int?基本字
i标识符
=算符
1常数
; 界符
i标识符
<=算符
5常数
; 界符
i标识符
++算符
)? 界符
{ 界符
sum5 标识符
= 算符
sum5 标识符
- 算符
(界符
i标识符 - 算符
10常数
) 界符
; 界符
sum5 标识符
= 算符
sum5 标识符 - 算符
(界符
i 标识符
- 算符
2常数
) 界符
;? 界符
}界符
}界符
作业步骤:
(1) 了解该语言的单词符号
(2) 为单词符号构造对应的状态转换图。状态转换图的构造可以参考课本P41(图3.2)和P43(图3.3)
(3) 根据状态转图的结构进行计算机实现。
注:
数字52.9e10为一个数据,切记不可将其分开为52.9和10; <=为一个操作符,切记不可将其分开为< 和 =
作业二 (选做)
flex 是- fast lexical analyzer generator 的简称,即快速词法分析器。
给出的“lex_实验”是一个通过flex得到的词法分析器及相关文件,该词法分析器可以统计源程序的行数及字符数。
(一) 目录介绍
参考 “lex_实验”,在完成实验后,实验目录中包括两个子目录。
1、子目录 flex
它包含了 flex.exe, flex.hlp, libfl.lib 三个文件,另外还有一个例子文件 example.l 及该例子生成的 lex.yy.c。
2、子目录 lex_yy
这个目录是为 lex.yy.c 建立的一个项目(如,使用 VC6)。它包含有 lex.yy.c, libfl.lib (拷贝自目录 flex),以及相关的项目文件。在debug 子目录中是已经生成的 词法分析器 lex.yy.exe, 利用它可以进行词法分析。
(二)实验示范
生成“lex_实验”的各文件的步骤如下:
1、编写 lex 程序,如 example.l 文件所示
2、调用 flex 以生成 lex.yy.c, DOS命令格式: flex < example.l
3、新建一个目录(如 lex_yy), 把lex.yy.c 及 libfl.lib 拷贝到该目录下。
4、用VC6或其它的C语言集成开发环境,打开lex.yy.c,并生成一个新项目。
5、编译并链接libfl.lib, 得到词法分析器 debug/ley.yy.exe。
6、验证词法分析器的功能:
1)编写一输入文件(如lex_yy/debug/12.txt)
2) 调用 lex.yy.exe(DOS 命令格式 lex.yy.exe < 12.txt )
3) 观察输出结果是否与预想的相符(实际是有点不相符的)。
注意:flex.exe, flex.hlp, libfl.lib 三个文件是flex工具,自带的。
实验三 小型语法分析器的设计
一、实验原理
语法分析器通常是作为编译器或解释器的组件出现的,它的作用是进行语法检查、并构建由输入的单词组成的数据结构(一般是语法分析树、抽象语法树等层次化的数据结构)。
语法分析器通常使用一个独立的词法分析器从输入字符流中分离出一个个的“单词”,并将单词流作为其输入。实际开发中,语法分析器可以手工编写,也可以使用工具(半)自动生成
二、实验要求和目的
1、加深对语法分析器工作过程的理解;
2、加强对递归下降法实现语法分析程序的掌握;
3、能够采用一种编程语言实现简单的语法分析程序;
4、能够使用自己编写的分析程序对简单的程序段进行语法翻译。
三、实验环境
环境不限。
四、作业要求
在实验2的基础上,用递归下降分析法编制语法分析程序,语法分析程序的实现可以采用任何一种编程工具。
编写的分析程序能够进行正确的语法分析;对于遇到的语法错误,能够做出简单的错误处理,给出简单的错误提示,保证顺利完成语法分析过程;
给定文法
E E + T | E – T | T
T T * F | T / F | F
F (E) | i
取消左递归后,改为:
E TE’
E’ +TE’ | -TE’ |ε
T FT’
T’ *FT’ | /FT’|ε
F (E) | i
该文法为LL(1)方法。
请根据第4.4节的递归下降分析程序构造方法,为该文法构造程序,对于给定的输入,程序按照先后顺序将使用的产生式输出。
如,输入25.6 * 14.5 + 2, 首先经过词法分析器,得到五个单词符号 i * i + i
经过语法分析,则输出
E TE’
T FT’
F i
T’*FT’
F i
T’ε
E’+TE’
T FT’
F i
T’ε
E’ε
提示:
(1) 该程序应该为每个非终结符( E、E’、T、T’、F)分别写一个函数,写函数时,需要考虑first集和follow集。
(2) 在验证程序正确性时,要考虑语法正确的串和语法不正确的串。
如: 正确的串有 25.6 * 14.5 + 2 ( i * i + i), 2 / 5.2 + 78 - 6 ( i / i + i - i)
错误的串有 2 / 5.2 + 78 – ( i / i + i - ) +56 * 7 ( + i * i)
对于给定的输入,大家可以通过手写推导过程,然后再核对计算机输出的产生式顺序的方法,检验程序写的对错。
实验四 小型语法分析器的设计
一、实验原理
1、语法分析器
语法分析器通常是作为编译器或解释器的组件出现的,它的作用是进行语法检查、并构建由输入的单词组成的数据结构(一般是语法分析树、抽象语法树等层次化的数据结构)。
语法分析器通常使用一个独立的词法分析器从输入字符流中分离出一个个的“单词”,并将单词流作为其输入。实际开发中,语法分析器可以手工编写,也可以使用工具(半)自动生成
2、算符优先分析
对于一个算符优先文法,只要能构造出它的算符优先表,就可以利用算符优先分析方法,分析一个句子是否符合这个文法的定义。在算符优先文法中,仅存在终结符号之间的优先关系,完全不考虑非终结符号。我们根据算符优先关系,给句型寻找一个被归约的最左素短语。一旦发现最左素短语,即可规约。
二、实验要求和目的
1、加深对语法分析器工作过程的理解;
2、加强对终结符之间的优先关系的掌握;
3、能够采用一种编程语言实现简单的算符优先分析过程。
三、实验环境
环境不限。
四、作业要求
1、在实验2的基础上,用算符优先分析法编制语法分析程序,语法分析程序的实现可以采用任何一种编程工具。
编写的分析程序能够进行正确的语法分析;对于遇到的语法错误,能够做出简单的错误处理,给出简单的错误提示,保证顺利完成语法分析过程。
给定文法及其优先关系表,如下:
(1)输入正确的表达式,则给出详细的操作步骤。如,给出表达式T+T*F+i,则输出
符号栈 优先关系 剩余输入串 动作
T+T*F+i# 移进
#T < +TF+i# 移进
#T+ TF+i# 移进
#T+T > F+i# 移进
#T+T F+i# 移进
#T+TF > +i# 归约TF
#T+N > +i# 归约T+N
#N < +i# 移进
#N+ < i# 移进
#N+i > # 归约i
#N+N > # 归约N+N
#N = # 接受
(2)输入错误的表达式,如 i+i *, 则报错。
2、选做
请设计一个小型公式编辑器的上下文无关文法,并进行自上而下分析的实现。
实验五 小型编译程序的设计
一、实验原理
(1) 词法分析
(2) 语法分析
(3) 语义分析
二、实验要求和目的
1、加深对词法分析器的理解;
2、加深对语法分析器的理解;
3、加深对属性文法的理解;
三、实验环境
环境不限。
四、作业要求
1、请大家在实验2和实验3的基础之上,利用翻译模式制作可编程计算器,如图1所示。要求: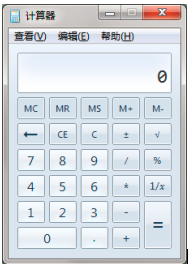
图1 可编程计算器界面
(1)点击 25.6 * 14.5 + 2 这11个符号,按‘=’,可输出结果373.2
(2)点击2 / (5.2 + 78) – 6这12个符号, 按‘=’,可输出结果 -5.97596
(3)若输入语法错误的串,如2 / 5.2 + 78 –, 则需报错。
(4)考虑整型和浮点型问题。对于浮点型,还需考虑精度问题。
(5)考虑除0问题。
(6)考虑键盘操作问题。
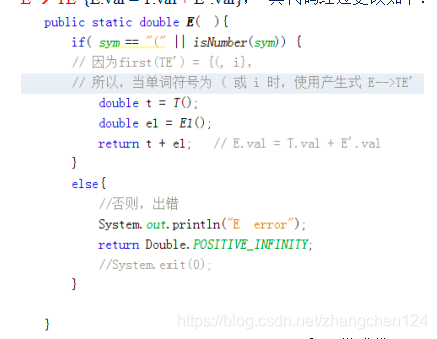
本题翻译模式的提示如下,请补充以下三个空之后,参考图2所示的代码,写出计算器。
E TE’{E.val = T.val + E’.val}
E’ +TE’ {E’.val = T.val + E’.val}
E’ -TE’ {undefined}
E’ ε {E’.val = 0}
T FT’{T.val = F.val * T’.val}
T’ *FT’ {T’.val = F.val * T’.val}
T’ /FT’ {}
T’ ε {_________________}
F (E) {F.val = E.val}
F i {F.val = i.lexval}
E TE’{E.val = T.val + E’.val}, 其代码经过更改如下:
图2 翻译模式代码
2、选做
请将语义分析纳入到小型公式编辑器中,并将小型公式编辑器实现出来。
文章来源: aaaedu.blog.csdn.net,作者:tea_year,版权归原作者所有,如需转载,请联系作者。
原文链接:aaaedu.blog.csdn.net/article/details/118355745

- 点赞
- 收藏
- 关注作者
评论(0)