Python 包:五个真正的 Python 最爱

目录
Python 拥有庞大的包、模块和库生态系统,您可以使用它们来创建应用程序。其中一些包和模块包含在您的 Python 安装中,统称为标准库。
标准库由为常见编程问题提供标准化解决方案的模块组成。它们是跨许多学科的应用程序的绝佳构建块。但是,许多开发人员更喜欢使用替代包或扩展,这可能会提高标准库中内容的可用性和实用性。
在本教程中,您将与Real Python 的一些作者会面,并了解他们喜欢使用的包来代替标准库中更常见的包。
您将在本教程中学习的包是:
pudb:一个先进的、基于文本的可视化调试器requests:用于发出 HTTP 请求的漂亮 APIparse:一个直观、可读的文本匹配器dateutil:流行datetime库的扩展typer:直观的命令行界面解析器
您将首先查看pdb.
pudb 用于可视化调试

Christopher Trudeau 是 Real Python 的作者和课程创建者。在工作中,他是一名顾问,帮助组织改进其技术团队。在家里,他把时间花在棋盘游戏和摄影上。
我花了很多时间通过SSH 连接到远程机器,所以我无法利用大多数IDE。我选择的调试器是pudb,它有一个基于文本的用户界面。我发现它的界面直观且易于使用。
Python 附带pdb, 其灵感来自gdb,其本身灵感来自dbx. 虽然可以pdb完成这项工作,但它最强大的功能是它附带了 Python。因为它是基于命令行的,所以你要记住很多快捷键,一次只能看到少量的源代码。
另一个用于调试的 Python 包是pudb. 它显示源代码的全屏以及有用的调试信息。它的另一个好处是让我怀念过去在Turbo Pascal 中编码的日子:
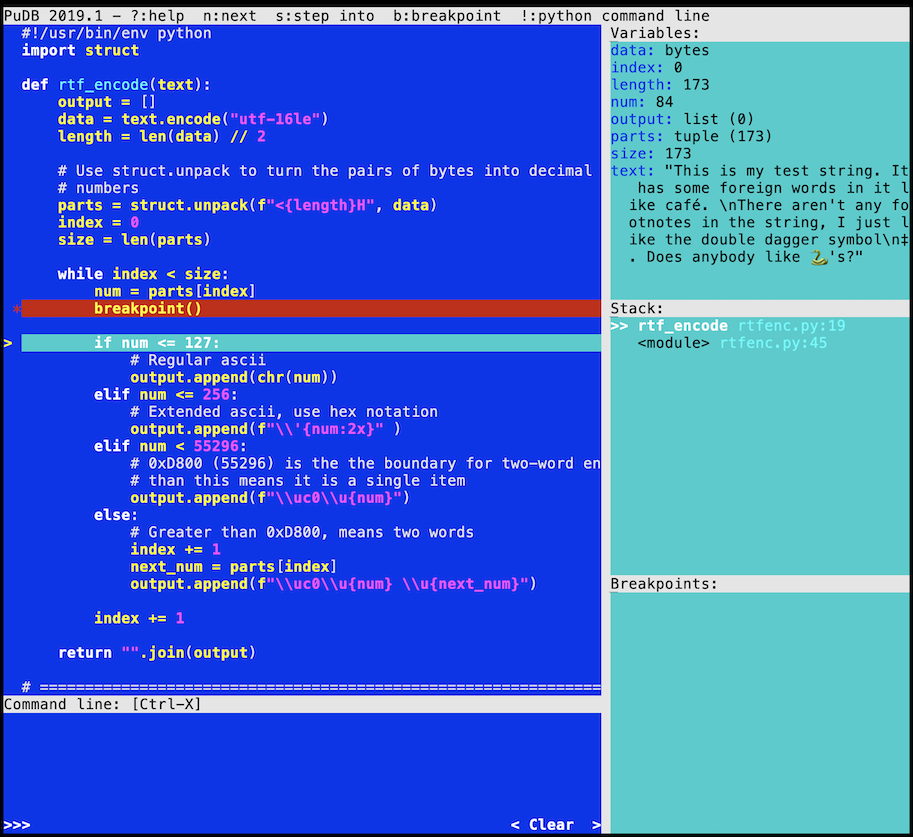
界面分为两个主要部分。左侧面板用于源代码,右侧面板用于上下文信息。右侧分为三个部分:
- Variables
- Stack
- Breakpoints
您在调试器中需要的一切都在一个屏幕上可用。
互动 pudb
您可以pudb通过pip以下方式安装:
$ python -m pip install pudb
如果您使用的是 Python 3.7 或更高版本,那么您可以breakpoint()通过将PYTHONBREAKPOINT环境变量设置为pudb.set_trace. 如果您使用的是基于 Unix 的操作系统,例如 Linux 或 macOS,那么您可以按如下方式设置变量:
$ export PYTHONBREAKPOINT=pudb.set_trace
如果您使用的是 Windows,则命令会有所不同:
C:\> set PYTHONBREAKPOINT=pudb.set_trace
或者,您可以import pudb; pudb.set_trace()直接插入到您的代码中。
当您运行的代码遇到断点时,会pudb中断执行并显示其界面:
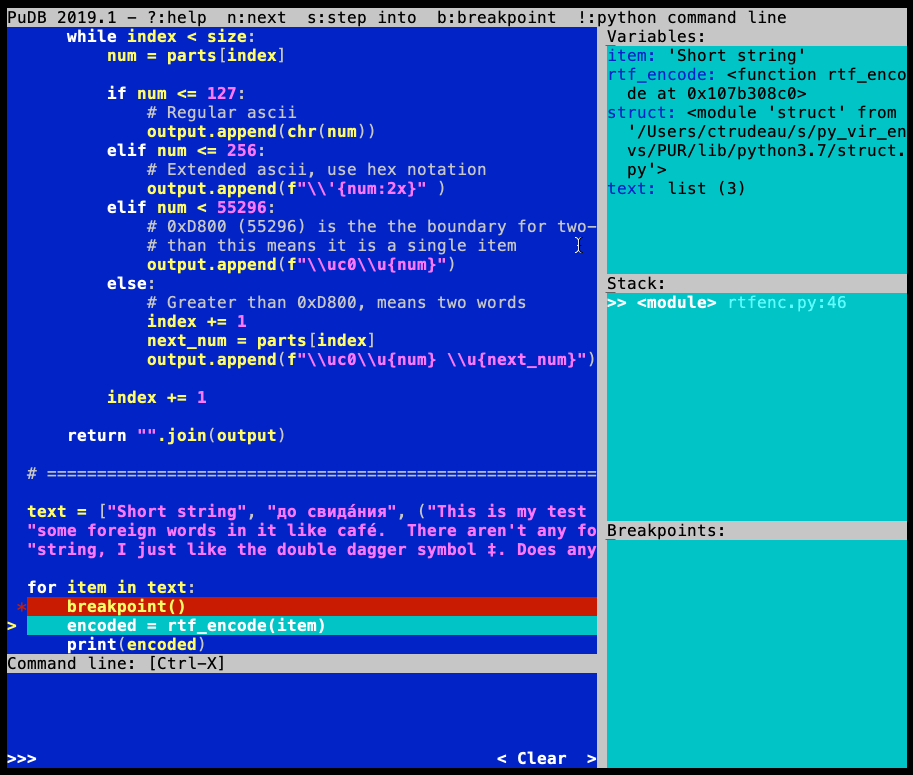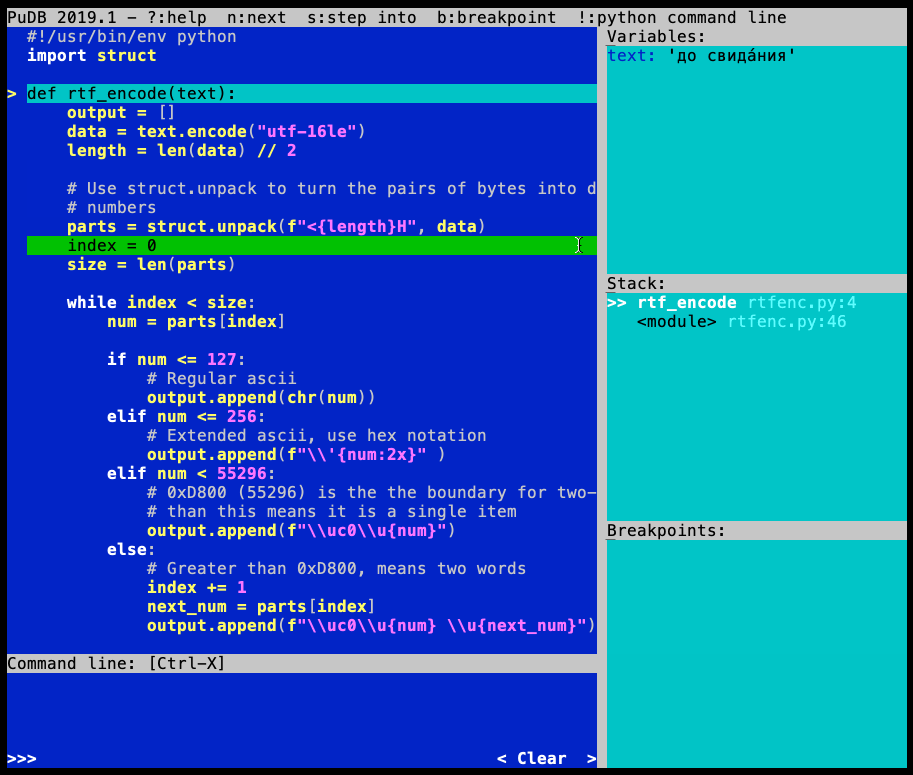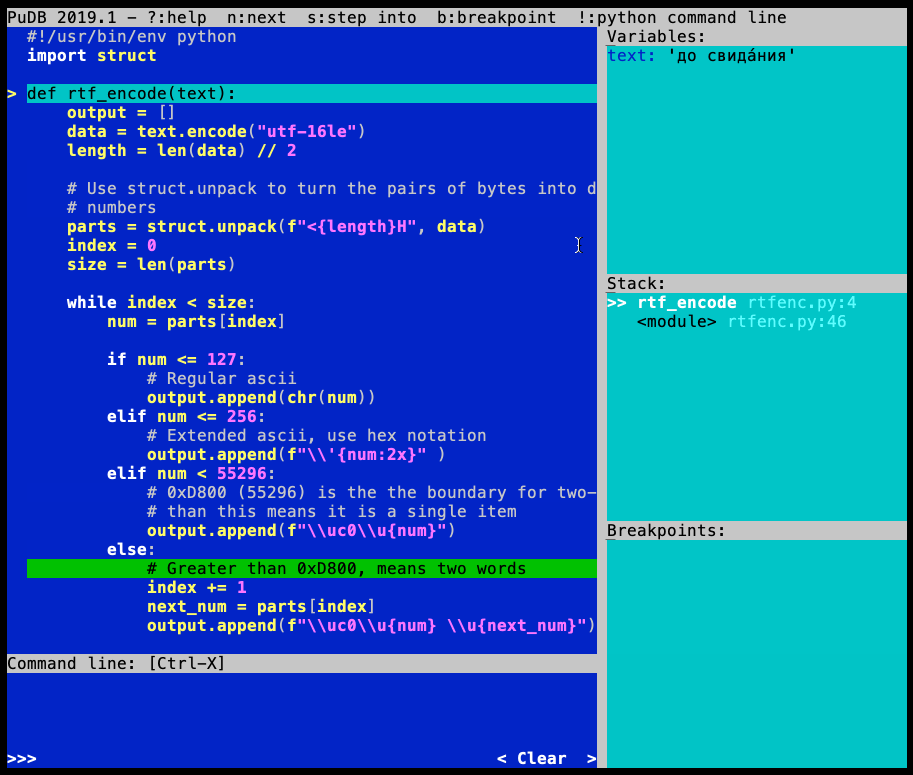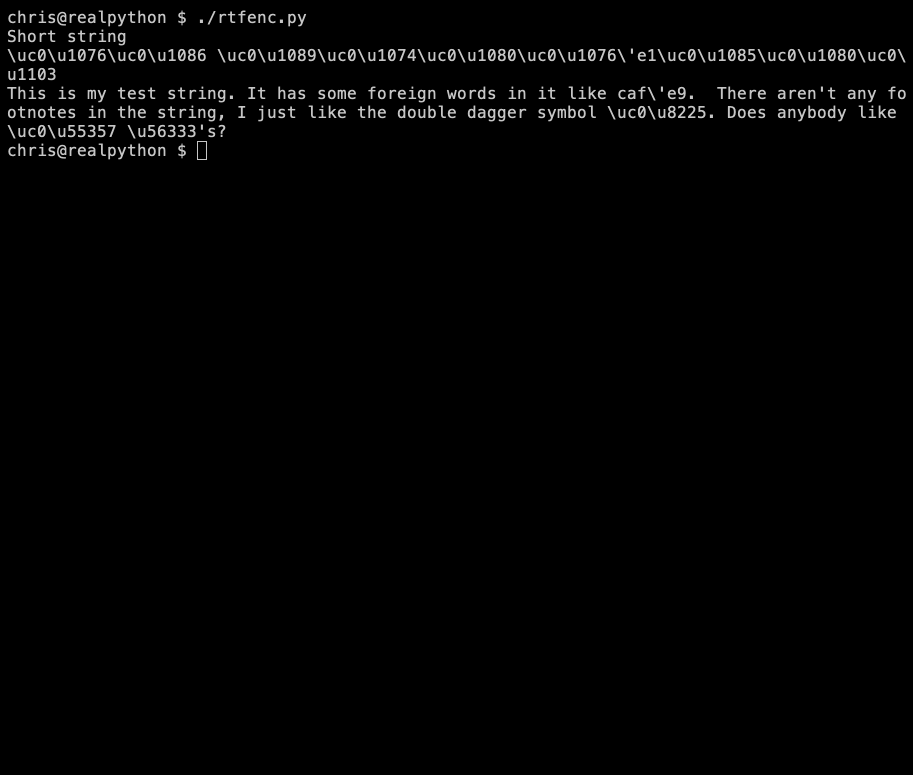
您可以使用键盘导航和执行源代码:
| 钥匙 | 行动 |
|---|---|
| Up 或者 K | 将代码向上移动一行 |
| Down 或者 J | 将代码下移一行 |
| Page Up或Ctrl+B | 向上滚动代码页 |
| Page Down或Ctrl+F | 向下滚动代码页 |
| N | 执行当前行 |
| S | 如果是函数则进入当前行 |
| C | 继续执行到下一个断点 |
如果您重新启动代码,则会pudb记住上一个会话中的断点。Right并Left允许您在右侧的源代码和控制区域之间移动。
在Variables框中,您会看到当前范围内的所有变量:

默认情况下,变量的视图被缩短,但您可以通过按 来查看完整内容\。展开视图将显示元组或列表中的项目,或者显示二进制变量的完整内容。T和R来回切换之间repr和type显示模式。
使用监视表达式并访问 REPL
当右侧的变量区域聚焦时,您还可以添加监视表达式。watch 可以是任何 Python 表达式。当对象仍处于其缩短形式时,它对于检查深埋在对象中的数据或评估变量之间的复杂关系非常有用。
注意:您可以通过按 来添加监视表达式N。由于N也用于执行当前代码行,因此在按下该键之前,您必须确保屏幕的正确区域处于焦点。
!在当前正在运行的程序的上下文中,按下会使您转义到 REPL。此模式还会向您显示在调试器触发之前发送到屏幕的任何输出。通过导航界面或使用快捷键,您还可以修改断点、更改您在堆栈帧中的位置以及加载其他源代码文件。
为什么pudb很棒
该pudb界面需要更少的快捷键记忆,pdb并且旨在显示尽可能多的代码。它具有IDE中调试器的大部分功能,但可以在终端中使用。由于这个 Python 包的安装只需很短的pip时间,您可以快速将其带入任何环境。下次你被命令行卡住时,检查一下!
requests 用于与 Web 交互

Martin Breuss 是 Real Python 的作者和课程创建者。他在 CodingNomads 担任编程教育家,在那里教授训练营和在线课程。工作之余,他喜欢坐席徒步、散步和录制随机声音。
我从标准库之外挑选的 Python 包的第一选择是流行的requests包。它在我的计算机上具有特殊地位,因为它是我在系统范围内安装的唯一外部软件包。所有其他软件包都位于其专用的虚拟环境中。
我并不是唯一一个喜欢requests作为 Python Web 交互的主要工具的人:根据requests 文档,该软件包每天的下载量约为 160 万次!
这个数字如此之高是因为与 Internet 的程序化交互提供了许多可能性,无论是通过Web API发布您的文章还是通过Web 抓取获取数据。但是 Python 的标准库已经包含了urllib帮助完成这些任务的包。那么为什么要使用外部包呢?是什么造就了requests如此受欢迎的选择?
requests 可读
该requests库提供了一个开发良好的 API,它紧密遵循 Python 的目标,即像普通英语一样可读。该requests开发者总结了他们的口号是理念,“HTTP人类。”
您可以使用在您的计算机pip上安装requests:
$ python -m pip install requests
让我们探索如何requests通过使用它来访问网站上的文本来提高可读性。使用可信赖的浏览器处理此任务时,您应遵循以下步骤:
- 打开浏览器。
- 输入网址。
- 看看网站的文字。
你怎么能用代码实现同样的结果?首先,您在伪代码中列出了必要的步骤:
- 导入您需要的工具。
- 获取网站数据。
- 打印网站的文本。
理清逻辑后,您可以使用requests库将伪代码转换为 Python:
>>> import requests
>>> response = requests.get("http://www.example.com")
>>> response.text
代码读起来几乎像英语,简洁明了。虽然使用标准库的urllib包来构建这个基本示例并不困难,但requests即使在更复杂的场景中也能保持其直接的、以人为中心的语法。
在下一个示例中,您将看到只需几行 Python 代码就可以实现很多目标。
requests 很强大
让我们加强游戏并挑战requests更复杂的任务:
- 登录到您的 GitHub 帐户。
- 保留该登录信息以处理多个请求。
- 创建一个新的存储库。
- 创建一个包含一些内容的新文件。
- 仅当第一个请求成功时才运行第二个请求。
接受并完成挑战!下面的代码片段完成了上述所有任务。所有你需要做的就是代替两个字符串 "YOUR_GITHUB_USERNAME",并"YOUR_GITHUB_TOKEN"与你的GitHub用户名和令牌,分别为个人访问。
注意:要创建个人访问令牌,请单击生成新令牌并选择存储库范围。复制生成的令牌并将其与您的用户名一起使用以进行身份验证。
阅读下面的代码片段,将其复制并保存到您自己的 Python 脚本中,填写您的凭据,然后运行它以查看requests操作:
import requests
session = requests.Session()
session.auth = ("YOUR_GITHUB_USERNAME", "YOUR_GITHUB_TOKEN")
payload = {
"name": "test-requests",
"description": "Created with the requests library"
}
api_url ="https://api.github.com/user/repos"
response_1 = session.post(api_url, json=payload)
if response_1:
data = {
"message": "Add README via API",
# The 'content' needs to be a base64 encoded string
# Python's standard library can help with that
# You can uncover the secret of this garbled string
# by uploading it to GitHub with this script :)
"content": "UmVxdWVzdHMgaXMgYXdlc29tZSE="
}
repo_url = response_1.json()["url"]
readme_url = f"{repo_url}/contents/README.md"
response_2 = session.put(readme_url, json=data)
else:
print(response_1.status_code, response_1.json())
html_url = response_2.json()["content"]["html_url"]
print(f"See your repo live at: {html_url}")
session.close()
运行代码后,继续导航到它在最后打印出来的链接。您将看到在您的 GitHub 帐户上创建了一个新存储库。新存储库包含一个README.md文件,其中包含一些文本,所有文本均使用此脚本生成。
注意:您可能已经注意到,该代码仅进行一次身份验证,但仍然能够发送多个请求。这是可能的,因为该requests.Session对象允许您在多个请求中保留信息。
如您所见,上面的简短代码片段完成了很多工作,并且仍然可以理解。
为什么requests很棒
Python 的request库是 Python 使用最广泛的外部库之一,因为它是一种可读、可访问且功能强大的与 Web 交互的工具。要了解有关使用 的多种可能性的更多信息requests,请查看使用 Python 进行 HTTP 请求。
parse 用于匹配字符串

Geir Arne Hjelle 是 Real Python 的作者和评论者。他在挪威奥斯陆担任数据科学顾问,当他的分析涉及地图和图像时特别高兴。远离键盘,Geir Arne 喜欢棋盘游戏、吊床和漫无目的地走进森林。
我喜欢正则表达式的力量。使用正则表达式或regex,您几乎可以搜索给定字符串中的任何模式。然而,强大的力量伴随着巨大的复杂性!构建一个正则表达式可能需要大量的反复试验,理解给定正则表达式的微妙之处可能更难。
parse是一个库,它包含了正则表达式的大部分功能,但使用的语法更清晰,可能更熟悉。简而言之,parse就是反向的f-strings。您可以使用与格式化字符串基本相同的表达式来搜索和解析字符串。让我们来看看它在实践中是如何工作的!
查找匹配给定模式的字符串
您需要一些要解析的文本。在这些示例中,我们将使用原始 f-strings 规范PEP 498。pepdocs是一个可以下载 Python Enhancement Proposal (PEP) 文档文本的小实用程序。
安装parse和pepdocs从PyPI:
$ python -m pip install parse pepdocs
首先,下载 PEP 498:
>>> import pepdocs
>>> pep498 = pepdocs.get(498)
parse例如,使用您可以找到 PEP 498 的作者:
>>> import parse
>>> parse.search("Author: {}\n", pep498)
<Result ('Eric V. Smith <eric@trueblade.com>',) {}>
parse.search()搜索的模式,在这种情况下"Author: {}\n",在任何地方给定的字符串中。您还可以使用parse.parse(), 将模式与完整字符串匹配。与 f 字符串类似,您可以使用花括号 ( {}) 来指示要解析的变量。
虽然您可以使用空花括号,但大多数情况下您希望将名称添加到搜索模式中。您可以像这样拆分 PEP 498 作者Eric V. Smith的姓名和电子邮件地址:
>>> parse.search("Author: {name} <{email}>", pep498)
<Result () {'name': 'Eric V. Smith', 'email': 'eric@trueblade.com'}>
这将返回一个Result包含匹配信息的对象。您可以访问与搜索的所有结果.fixed,.named和.spans。您还可以使用[]获取单个值:
>>> result = parse.search("Author: {name} <{email}>", pep498)
>>> result.named
{'name': 'Eric V. Smith', 'email': 'eric@trueblade.com'}
>>> result["name"]
'Eric V. Smith'
>>> result.spans
{'name': (95, 108), 'email': (110, 128)}
>>> pep498[110:128]
'eric@trueblade.com'
.spans 为您提供与您的模式匹配的字符串中的索引。
使用格式说明符
您可以使用 找到模式的所有匹配项parse.findall()。尝试查找 PEP 498 中提到的其他 PEP:
>>> [result["num"] for result in parse.findall("PEP {num}", pep498)]
['p', 'd', '2', '2', '3', 'i', '3', 'r', ..., 't', '4', 'i', '4', '4']
嗯,这看起来不是很有用。PEP 使用数字引用。因此,您可以使用格式语法来指定您正在寻找数字:
>>> [result["num"] for result in parse.findall("PEP {num:d}", pep498)]
[215, 215, 3101, 3101, 461, 414, 461]
添加:d告诉parse你正在寻找一个整数。作为奖励,结果甚至从字符串转换为数字。除了:d,您还可以使用f-strings使用的大多数格式说明符。
您还可以使用特殊的两字符规范解析日期:
>>> parse.search("Created: {created:tg}\n", pep498)
<Result () {'created': datetime.datetime(2015, 8, 1, 0, 0)}>
:tg查找写为day/month/year 的日期。如果顺序或格式不同,您可以使用:tiand:ta以及其他几个选项。
访问底层正则表达式
parse建立在 Python 的正则表达式库之上,re. 每次进行搜索时,都会parse在后台构建相应的正则表达式。如果您需要多次进行相同的搜索,那么您可以使用parse.compile.
以下示例打印出 PEP 498 中对其他文档的引用的所有描述:
>>> references_pattern = parse.compile(".. [#] {reference}")
>>> for line in pep498.splitlines():
... if result := references_pattern.parse(line):
... print(result["reference"])
...
%-formatting
str.format
[ ... ]
PEP 461 rejects bytes.format()
该循环使用Python 3.8 及更高版本中可用的walrus operator来根据提供的模板测试每一行。您可以查看编译模式以了解潜伏在新发现的解析功能背后的正则表达式:
>>> references_pattern._expression
'\\.\\. \\[#\\] (?P<reference>.+?)'
原始parse模式".. [#] {reference}"更易于读取和写入。
为什么parse很棒
正则表达式显然很有用。然而,已经编写了厚厚的书籍来解释正则表达式的微妙之处。parse是一个小型库,提供正则表达式的大部分功能,但语法更友好。
如果你比较".. [#] {reference}"和"\\.\\. \\[#\\] (?P<reference>.+?)",那么你就会明白为什么我爱parse正则表达式的力量甚至超过我爱正则表达式的力量。
dateutil 用于处理日期和时间

Bryan Weber 是 Real Python 的作者和评论者,也是机械工程教授。在不编写 Python 或教学时,他很可能会被发现做饭、与家人一起玩耍或去远足,并且在美好的日子里,三者兼而有之。
如果您曾经不得不随着时间进行任何编程,那么您就会知道它可以将您束缚在哪些复杂的结中。首先,您必须处理时区,其中地球上的两个不同点在任何给定时刻都有不同的时间。然后你有夏令时,一年两次的事件,其中一个小时发生两次或根本不发生,但仅限于某些国家/地区。
您还必须考虑闰年和闰秒,以使人类时钟与地球绕太阳的公转保持同步。您必须围绕Y2K和Y2038错误进行编程。这份清单不胜枚举。
幸运的是,Python 在标准库中包含了一个非常有用的模块,称为datetime. Pythondatetime是存储和访问有关日期和时间的信息的好方法。但是,datetime有一些地方的界面不太好。
作为回应,Python 很棒的社区开发了几个不同的库和 API,用于以合理的方式处理日期和时间。其中一些扩展了内置的datetime,一些是完整的替代品。我最喜欢的图书馆是dateutil.
要按照下面的示例进行操作,请dateutil像这样安装:
$ python -m pip install python-dateutil
现在您已经dateutil安装完毕,接下来几节中的示例将向您展示它的强大功能。您还将看到如何dateutil与datetime.
设置时区
dateutil有几件事要做。首先,它在 Python 文档中被推荐作为datetime处理时区和夏令时的补充:
>>> from dateutil import tz
>>> from datetime import datetime
>>> london_now = datetime.now(tz=tz.gettz("Europe/London"))
>>> london_now.tzname() # 'BST' in summer and 'GMT' in winter
'BST'
但是dateutil可以做的不仅仅是提供一个具体的tzinfo实例。这真的很幸运,因为在Python 3.9 之后,Python 标准库将拥有自己访问IANA 数据库的能力。
解析日期和时间字符串
dateutildatetime使用parser模块将字符串解析为实例变得更加简单:
>>> from dateutil import parser
>>> parser.parse("Monday, May 4th at 8am") # May the 4th be with you!
datetime.datetime(2020, 5, 4, 8, 0)
请注意,dateutil即使您没有指定它,它也会自动推断该日期的年份!您还可以控制如何时区进行解释或使用添加parser或工作与ISO-8601格式的日期。这为您提供了比datetime.
计算时差
另一个出色的特性dateutil是它能够用relativedelta模块处理时间算术。您可以从一个datetime实例中添加或减去任意时间单位,或者找出两个datetime实例之间的差异:
>>> from dateutil.relativedelta import relativedelta
>>> from dateutil import parser
>>> may_4th = parser.parse("Monday, May 4th at 8:00 AM")
>>> may_4th + relativedelta(days=+1, years=+5, months=-2)
datetime.datetime(2025, 3, 5, 8, 0)
>>> release_day = parser.parse("May 25, 1977 at 8:00 AM")
>>> relativedelta(may_4th, release_day)
relativedelta(years=+42, months=+11, days=+9)
这比datetime.timedelta因为您可以指定大于一天的时间间隔(例如一个月或一年)更灵活和强大。
计算重复事件
最后但并非最不重要的是,dateutil有一个强大的模块,rrule用于根据iCalendar RFC计算未来的日期。假设您想为 6 月份生成一个定期站立时间表,发生在星期一和星期五的上午 10:00:
>>> from dateutil import rrule
>>> from dateutil import parser
>>> list(
... rrule.rrule(
... rrule.WEEKLY,
... byweekday=(rrule.MO, rrule.FR),
... dtstart=parser.parse("June 1, 2020 at 10 AM"),
... until=parser.parse("June 30, 2020"),
... )
... )
[datetime.datetime(2020, 6, 1, 10, 0), ..., datetime.datetime(2020, 6, 29, 10, 0)]
请注意,您不必知道开始日期或结束日期是星期一还是星期五 —dateutil为您计算出来。另一种使用方法rrule是查找特定日期的下一次出现时间。让我们找出下一次闰日,即 2 月 29 日,会像 2020 年一样发生在星期六:
>>> list(
... rrule.rrule(
... rrule.YEARLY,
... count=1,
... byweekday=rrule.SA,
... bymonthday=29,
... bymonth=2,
... )
... )
[datetime.datetime(2048, 2, 29, 22, 5, 5)]
为什么dateutil很棒
您刚刚看到的四个功能dateutil可以让您在处理时间时更轻松:
- 设置与对象兼容的时区的便捷方法
datetime - 一种将字符串解析为日期的有用方法
- 用于进行时间运算的强大界面
- 一种计算重复日期或未来日期的绝妙方法。
下次当您尝试随着时间的推移进行编程而变灰时,请dateutil试一试!
typer 用于命令行界面解析

Dane Hillard 是 Python 书籍和博客作者,也是 ITHAKA(一个支持高等教育的非营利组织)的首席 Web 应用程序开发人员。在空闲时间,他几乎什么都做,但特别喜欢烹饪、音乐、棋盘游戏和国标舞。
Python 开发人员通常从使用sys模块的命令行界面 (CLI) 解析开始。您可以阅读sys.argv以获取用户提供给您的脚本的参数列表:
# command.py
import sys
if __name__ == "__main__":
print(sys.argv)
脚本的名称和用户提供的任何参数最终作为字符串值在sys.argv:
$ python command.py one two three
["command.py", "one", "two", "three"]
$ python command.py 1 2 3
["command.py", "1", "2", "3"]
但是,当您向脚本添加功能时,您可能希望以更明智的方式解析脚本的参数。您可能需要管理几种不同数据类型的参数,或者让用户更清楚哪些选项可用。
argparse 笨重
Python 的内置argparse模块可帮助您创建命名参数,将用户提供的值转换为正确的数据类型,并自动为您的脚本创建帮助菜单。如果您以前没有使用argparse过,请查看如何使用 argparse 在 Python 中构建命令行接口。
的一大优点argparse是您可以以更具声明性的方式指定 CLI 的参数,从而减少了大量的过程和条件代码。
考虑以下示例,该示例用于sys.argv以用户指定的次数打印用户提供的字符串,同时对边缘情况的处理最少:
# string_echo_sys.py
import sys
USAGE = """
USAGE:
python string_echo_sys.py <string> [--times <num>]
"""
if __name__ == "__main__":
if len(sys.argv) == 1 or (len(sys.argv) == 2 and sys.argv[1] == "--help"):
sys.exit(USAGE)
elif len(sys.argv) == 2:
string = sys.argv[1] # First argument after script name
print(string)
elif len(sys.argv) == 4 and sys.argv[2] == "--times":
string = sys.argv[1] # First argument after script name
try:
times = int(sys.argv[3]) # Argument after --times
except ValueError:
sys.exit(f"Invalid value for --times! {USAGE}")
print("\n".join([string] * times))
else:
sys.exit(USAGE)
此代码为用户提供了一种查看有关使用该脚本的有用文档的方法:
$ python string_echo_sys.py --help
USAGE:
python string_echo_sys.py <string> [--times <num>]
用户可以提供一个字符串和一个可选的打印字符串的次数:
$ python string_echo_sys.py HELLO! --times 5
HELLO!
HELLO!
HELLO!
HELLO!
HELLO!
要使用 实现类似的接口argparse,您可以编写如下内容:
# string_echo_argparse.py
import argparse
parser = argparse.ArgumentParser(
description="Echo a string for as long as you like"
)
parser.add_argument("string", help="The string to echo")
parser.add_argument(
"--times",
help="The number of times to echo the string",
type=int,
default=1,
)
if __name__ == "__main__":
args = parser.parse_args()
print("\n".join([args.string] * args.times))
该argparse代码是更具描述性的,并且argparse还提供了充分的论证分析和--help解释你如何使用脚本选项,全部免费。
虽然argparse比sys.argv直接处理有很大的改进,但它仍然迫使您对 CLI 解析进行很多思考。您通常会尝试编写一个脚本来做一些有用的事情,所以花在 CLI 解析上的精力是浪费!
为什么typer很棒
typer提供了几个相同的功能,argparse但使用了非常不同的开发范式。无需编写任何声明性、过程性或条件逻辑来解析用户输入,而是typer利用类型提示来内省您的代码并生成 CLI,这样您就不必花费太多精力来考虑处理用户输入。
首先typer从 PyPI安装:
$ python -m pip install typer
现在您已经typer可以随意使用了,下面是您如何编写一个脚本来实现与argparse示例类似的结果:
# string_echo_typer.py
import typer
def echo(
string: str,
times: int = typer.Option(1, help="The number of times to echo the string"),
):
"""Echo a string for as long as you like"""
typer.echo("\n".join([string] * times))
if __name__ == "__main__":
typer.run(echo)
这种方法使用更少的功能行,这些行主要集中在脚本的功能上。脚本多次回显字符串这一事实更为明显。
typer甚至为用户提供了Tab为他们的 shell生成补全的能力,这样他们就可以更快地使用脚本的 CLI。
您可以查看Comparing Python Command-Line Parsing Libraries – Argparse、Docopt 和 Click以查看其中的任何一个是否适合您,但我喜欢typer它的简洁和强大。
结论:五个有用的 Python 包
Python 社区已经构建了很多很棒的包。在本教程中,您了解了几个有用的包,它们是 Python 标准库中常见包的替代或扩展。
在本教程中,您学习了:
- 为什么
pudb可能会帮助您调试代码 - 如何
requests改进您与 Web 服务器的通信方式 - 如何使用
parse来简化您的字符串匹配 - 哪些功能
dateutil可用于处理日期和时间 - 为什么应该使用
typer解析命令行参数

- 点赞
- 收藏
- 关注作者
评论(0)